小爬爬5:scrapy介绍2
1.scrapy:爬虫框架
-框架:集成了很多功能且具有很强通用性的一个项目模板
-如何学习框架:(重点:知道有哪些模块,会用就行)
-学习框架的功能模板的具体使用.
功能:(1)异步爬取(自带buffer)
(2)高性能的数据解析+持久化存储操作.
2.scrapy环境安装:
Linux:
pip3 install scrapy
Windows:
a. pip3 install wheel
b. 下载地址twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
#注意:这一步是需要参考python版本cp36或者cp35
d. pip3 install pywin32
e. pip3 install scrapy
3.scrapy数据解析
scrapy使用流程
(1)首先,可以切换想要创建的目录,直接在下面的Terminal中创建一个工程,切换回上一层目录.
(2)创建一个工程命令:scrapy startproject scrapy1

(3)看一下目录结构,我们先了解spiders文件夹和settings.py文件
(4)settings.py里边,我们需要进行相关的属性配置
spiders文件夹下面,我们需要新建"爬虫文件",
我们再cd到我们刚才新建的工程内: cd scrapy1
创建爬虫文件:scrapy genspider 爬虫文件名 起始url
scrapy genspider first www.xxx.com
(5)下面,我们看一下穿件的爬虫文件first.py:

爬虫程序first.py,详细描述
# -*- coding: utf- -*-
import scrapy
class FirstSpider(scrapy.Spider):
name = 'first'
#name爬虫文件的名称,爬虫文件的唯一标识,有多个爬虫文件的时候会用到 # allowed_domains = ['www.xxx.com']
# allowed_domains = ['www.baidu.com']
#被允许的域名
#如果修改成:www.baidu.com这个被允许的域名,那么只可以访问百度下的相关地址
#因此我们知道这个allowed_domains是用来做限定的,这个可以注释掉 #起始的url列表(可以放置多个url)
#多个(都会被scrapy进行自动的请求发送)
start_urls = ['https://www.baidu.com/','https://www.sogou.com/'] #用来解析数据的parse函数,现在列表中有两个url,这两个都会被请求发送
#因此会调用两次
def parse(self, response): #response是url请求之后得到的响应对象
print(response)
下面执行爬虫程序(见下图):scrapy crawl first
我们看起来是仅仅执行这一个爬虫文件,但其实是执行了这整个工程
如果仅仅执行这一个爬虫文件是没有任何意义的.
运行:
得到的内容,很像是一些日志信息.

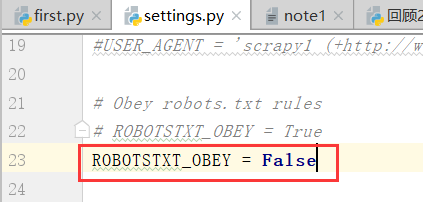
(6)我们可以看到其中有一条是"遵循robotstxt_obey"遵循robots协议,这也就意味着我们爬取不到任何的数据,
因此我们应该设置,不遵从robots协议,具体在settings.py里边设置,
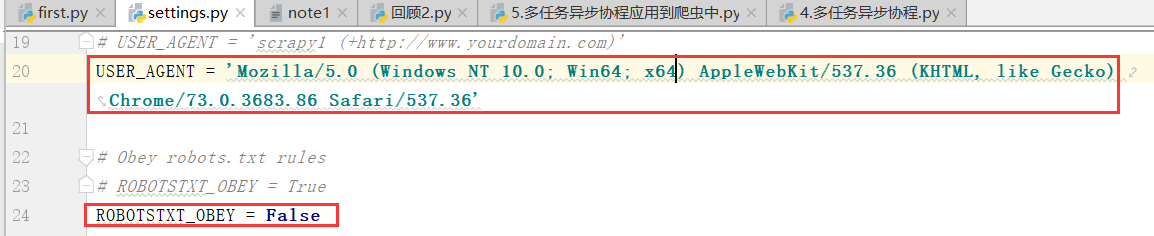
ROBOTSTXT_OBEY = False
(7)下面我们再在设置里,写"遵循UA伪装"
(8)这个时候,我们再次运行这个爬虫程序:
得到下面的结果:

(9)start_urls列表里边的url会自动发送请求的,不管有多少个都会发生请求.
parse这个函数就会得到response响应的响应
(10)我们看到的信息可能会干扰我们看信息,我们可以设置不看日志
这个时候,我们可以看到只要结果数据

2.爬取糗事百科中的作者名称
(1)回退到上一层:
创建一个项目:scrapy startproject qiubaiPro
(2)注意:我们创建爬虫文件一定要进入创建的工程内

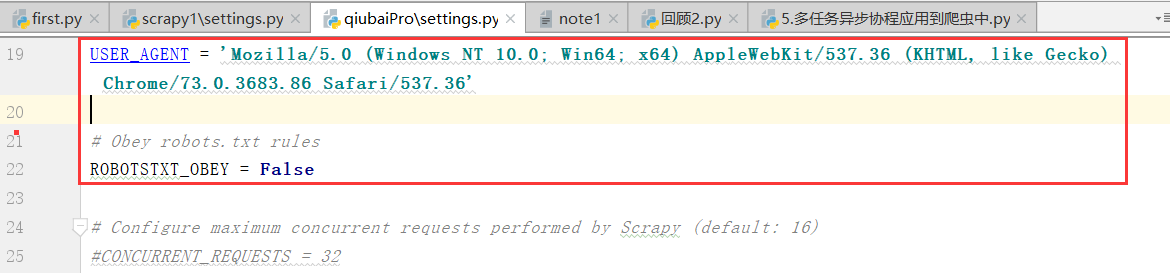
(3)先实现UA伪装和robots协议改写
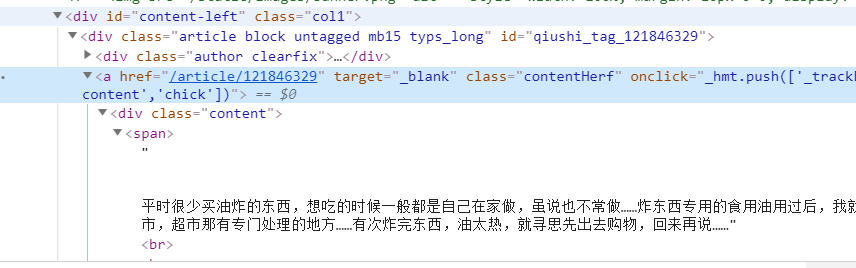
(4)下面,我们再实现爬虫文件的编写,先找到一个总的id="content-left",进行id定位

一步步,推导出作者的这个名称:
爬虫程序:qiubai.py
# -*- coding: utf- -*-
import scrapy class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.xxx.com']
#起始url
start_urls = ['https://www.qiushibaike.com/text/'] def parse(self, response):
div_list=response.xpath('//*[@id="content-left"]/div')
#拿到响应数据,进行xpath数据解析
#注意,这里的xpath和etree里边的xpath是不同的
for div in div_list:
author=div.xpath('./div[1]/a[2]/h2/text()')[]
content=div.xpath('.a/div/span//text()')
print(author,content)
break
#作者是字符串,
#内容是列表(内容是列表对应的字符串数据)
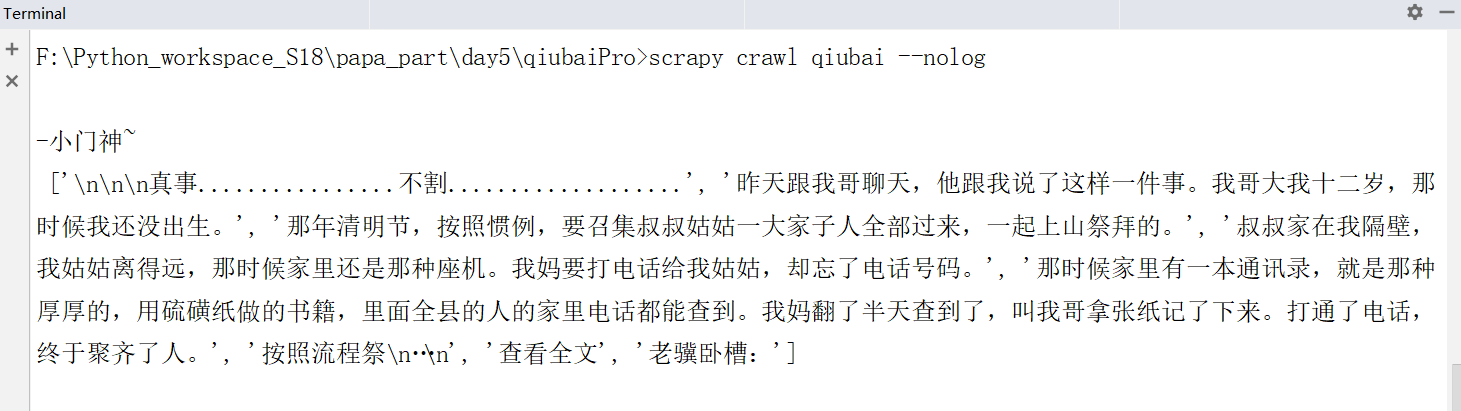
运行:下面的内容:
出不来结果,原因是xpath出现的问题,
content=div.xpath('./a/div/span//text()')
a的前边少了一个/
我们可以通过检查,看下日志,检查下错误出现在哪个地方:scrapy crawl qiubai(爬虫的文件名)
(5)下面是重新启动程序之后重新打开的命令:


我看看到得到的结果
下面我们加上extract()进行处理取数据
如何取出列表中很多条的数据?

Terminal中 cls命令是将内容推到上边
下面我们改变一下内容

我们得到下面的结果:
当我们只知道列表中有一个数据用下边的方法extract_first()
extract() 列表中有多条数据的时候,我们需要将内容拼接起来.
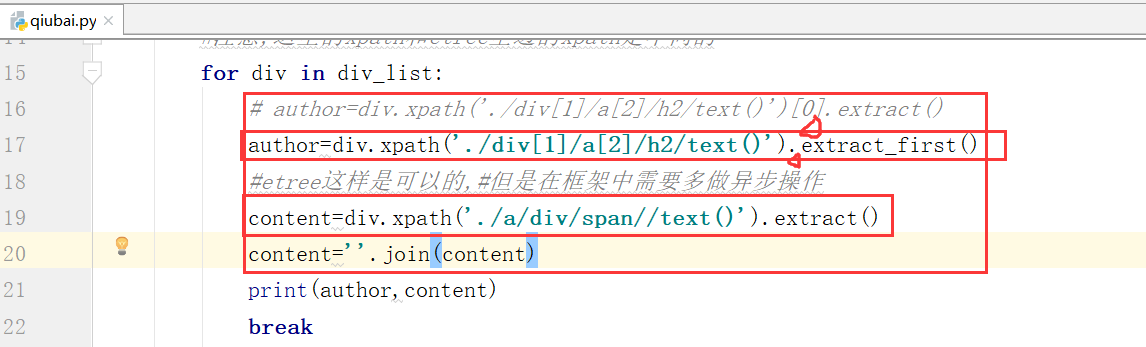
运行.这个时候我们可以拿到作者和笑话,还有评论人的名称

这个时候,我们将上边的代码中的break去掉,再次运行

运行,得到全部的作者和笑话
小爬爬5:scrapy介绍2的更多相关文章
- 小爬爬5:scrapy介绍3持久化存储
一.两种持久化存储的方式 1.基于终端指令的吃持久化存储: 特点:终端指令的持久化存储,只可以将parse方法的返回值存储到磁盘文件 因此我们需要将上一篇文章中的author和content作为返回值 ...
- 小爬爬6.scrapy回顾和手动请求发送
1.数据结构回顾 #栈def push(self,item) def pop(self) #队列 def enqueue(self,item) def dequeue(self) #列表 def ad ...
- 微信小程序管理后台介绍
微信小程序的管理后台,每次进入都需要扫码,还是特别不爽,现在微信小程序还没正式发布,很多人都还没看到管理后台,这里抢先发布出来 ------------------------------------ ...
- 微信小程序-06-详解介绍.js 逻辑层文件-注册页面
上一篇介绍的是 app.js 逻辑层文件中注册程序,对应的每个分页面都会有的 js 文件中 page() 函数注册页面 微信小程序-06-详解介绍.js 逻辑层文件-注册页面 宝典官方文档: http ...
- 微信小程序-05-详解介绍.js 逻辑层文件
上一篇介绍了关于.json 的配置文件,本篇介绍关于.js 逻辑层文件 微信小程序-05-详解介绍.js 逻辑层文件 宝典官方文档: https://developers.weixin.qq.com/ ...
- 微信小程序-04-详解介绍.json 配置文件
致我自己:小程序开发不是简单一两天的事,一两天只能算是了解,有时候看多了会烦,感觉很熟悉了,其实只是对表面进行了解,对编程却知之甚少,小程序开发不是简单的改模板,一两天很多部分改模板可能都做不到,坚持 ...
- ELK之开心小爬爬
1.开心小爬爬 在爬取之前需要先安装requests模块和BeautifulSoup这两个模块 ''' https://www.autohome.com.cn/all/ 爬取图片和链接 写入数据库里边 ...
- 小爬爬6: 网易新闻scrapy+selenium的爬取
1.https://news.163.com/ 国内国际,军事航空,无人机都是动态加载的,先不管其他我们最后再搞中间件 2. 我们可以查看到"国内"等板块的位置 新建一个项目,创建 ...
- 小爬爬1:开篇&&简单介绍启动
1.第一阶段的内容 2.学习的方法? 思考,总结,重复 3.长大了意味着什么?家庭的责任,真的很重 4.数据分析&&数据清洗 numpy&&pandas&&am ...
随机推荐
- element-ui 使用笔记
1,获取级联选择器 cascader的值 获取value值:就是v-model绑定的值, 获取label值:要先给cascader组件一个ref值,然后通过 this.$refs.组件的ref值.cu ...
- extern “C”的用法
引言 由于不同的代码互相调用起来很容易出错,甚至同一种代码但由不同的编译器编译,为实现C++代码调用其他C语言代码,会在C语言代码的部分加上extern "C",表明这段代码需要按 ...
- 【DM8168学习笔记3】CodSourcery GCC Tool Chain安装过程记录
eagle@eagle-desktop:~$ cd/home/eagle/desktop eagle@eagle-desktop:~/desktop$ cd./vboxshared eagle@eag ...
- python学习笔记3_数据载入、存储及文件格式
一.丛mysql数据库中读取数据 import pandas as pdimport pymysqlconn = pymysql.connect( host = '***', user = '***' ...
- 关于开启Eureka安全Security认证后,客户端死活注册不上的问题
遇到一个问题"开启Eureka服务端的安全认证后,客户端死活注册不到Eureka上",已经尝试了以下办法,完全搞不定... 客户端出错的版本: spring-boot:2.0.3. ...
- 把char[]数组里面的内容用MessageBox显示出来
const char *q; q = mysql_get_client_info(); //获得一字符串指针 CString p(q); AfxMessageBox(p);
- 2018-2-13-visual-Studio-无法调试,提示程序跟踪已退出
title author date CreateTime categories visual Studio 无法调试,提示程序跟踪已退出 lindexi 2018-2-13 17:23:3 +0800 ...
- 如何实现一个HTTP请求库——axios源码阅读与分析 JavaScript
概述 在前端开发过程中,我们经常会遇到需要发送异步请求的情况.而使用一个功能齐全,接口完善的HTTP请求库,能够在很大程度上减少我们的开发成本,提高我们的开发效率. axios是一个在近些年来非常火的 ...
- python实例 字典
#! /usr/bin/python x={'a':'aaa','b':'bbb','c':12} print (x['a']) print (x['b']) print (x['c']) for k ...
- python实例 列表
#! /usr/bin/python # -*- coding: utf8 -*- #列表类似Javascript的数组,方便易用 #定义元组 word=['a','b','c','d','e','f ...