小爬爬5:scrapy介绍3持久化存储
一.两种持久化存储的方式
1.基于终端指令的吃持久化存储:
特点:终端指令的持久化存储,只可以将parse方法的返回值存储到磁盘文件
因此我们需要将上一篇文章中的author和content作为返回值的内容,我们可以将所有内容数据放在列表中,
每个字典存储作者名字和内容,最好将定义的列表返回即可
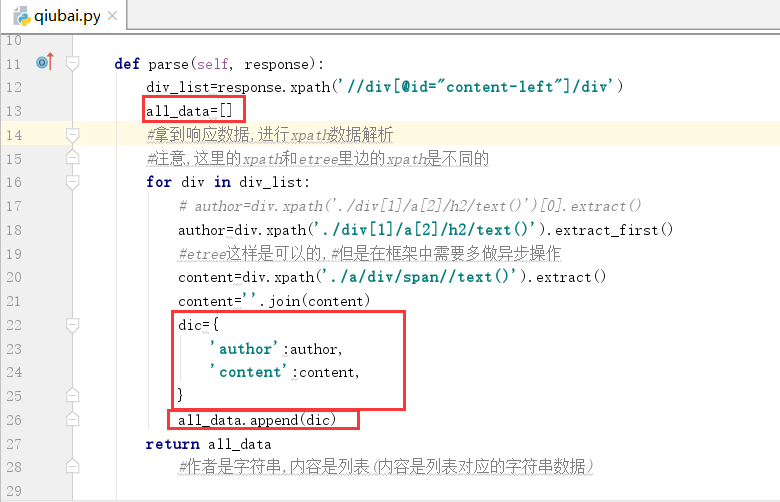
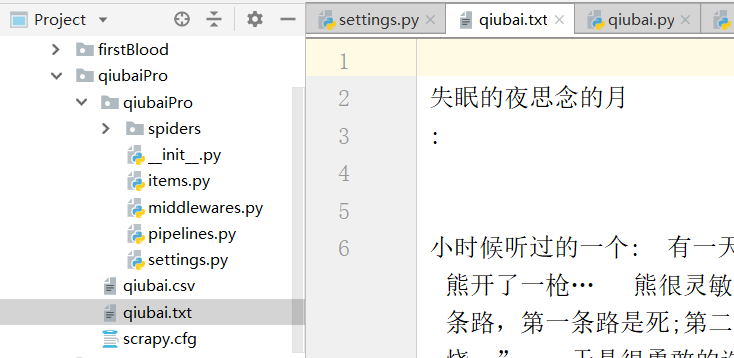
我们在下图的终端中运行下面的命令

我们右击整个爬虫工程,点击下面的选项,同步产生的数据
我们得到下面的qiubai.csv内容
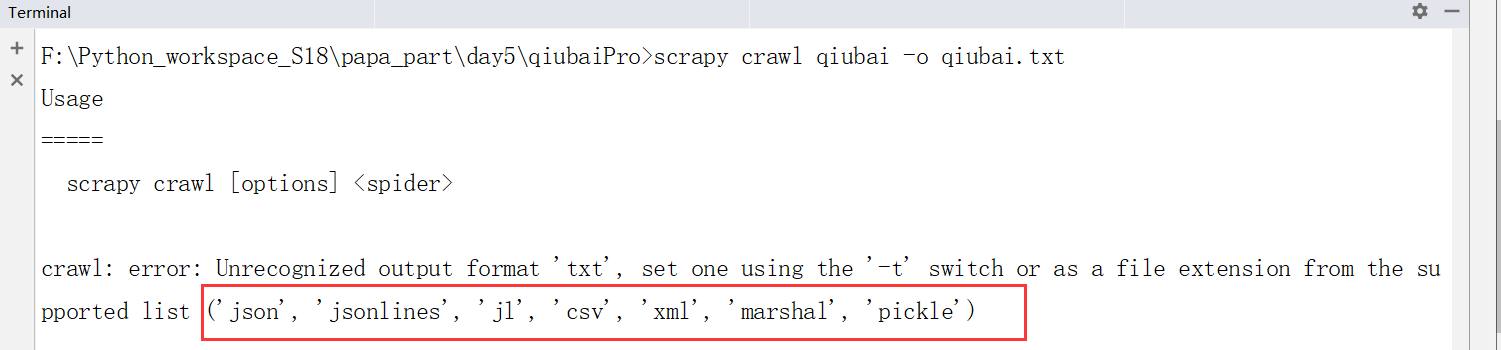
思考可不可以保存到txt后缀的文件中?只支持下面的文件格式,因此不支持
基于终端的命令:scrapy crawl qiubai -o qiubai.csv
优点:便捷
缺点:局限性强(只可以将数据写入本地文件,文件后缀是由具体要求)
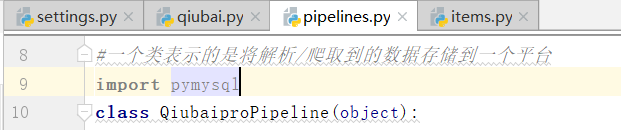
2.基于管道的持久化存储
基于管道:
基于持久化存储的所有操作都必须写入到管道文件的管道类中
open io 以及数据库(mysql,redis等),pymysql等等都是基于持久化的存储操作
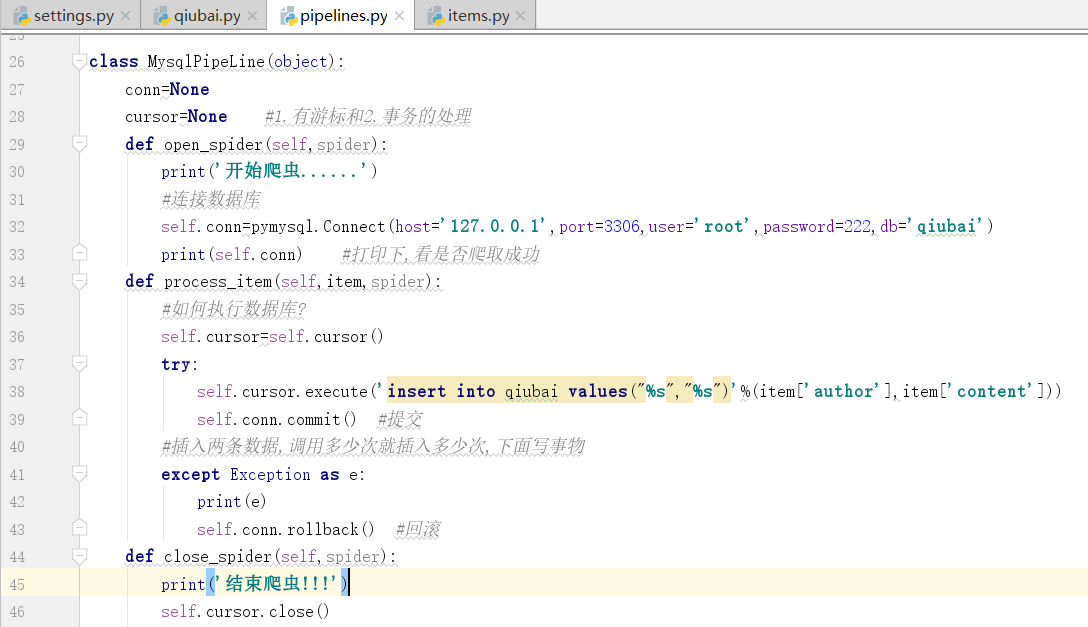
我们看到这个pipelines.py文件,以及这个文件中一个类
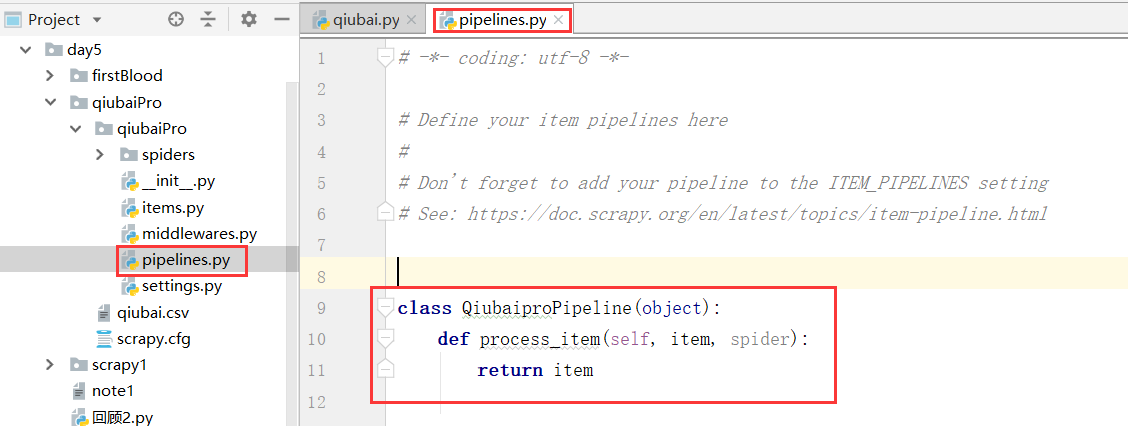
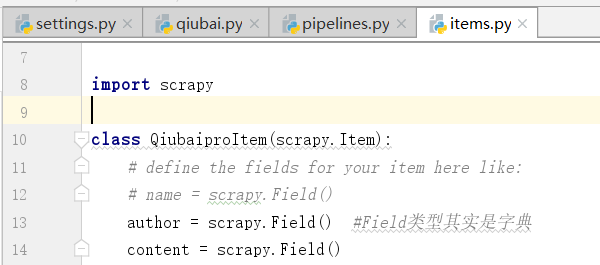
我们看到这个管道类中有一个item方法,以及item参数,只可以处理item类型的对象
#可以将item类型的对象中存储的数据进行持久化存储
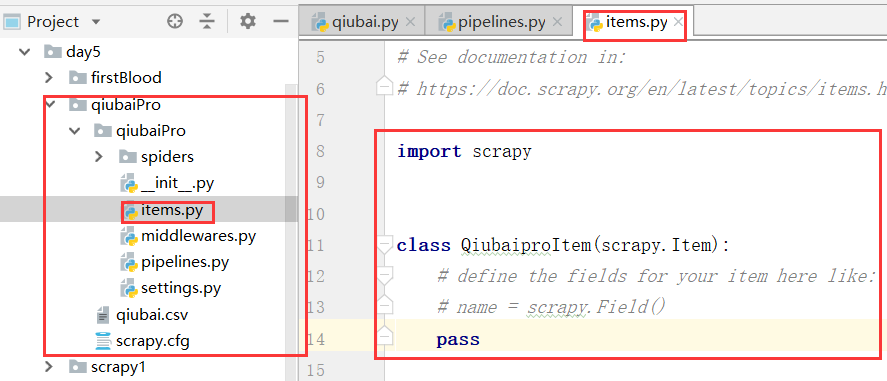
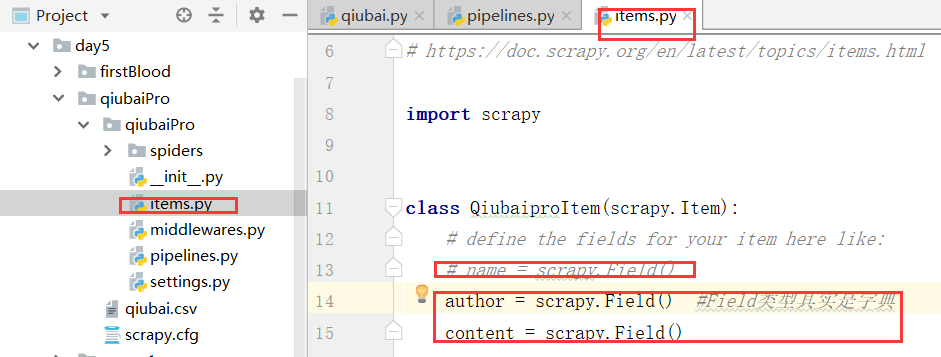
通过item类型的对象进行处理,我们通过对上边的数据写入items.py文件进行处理
下面我们进行定制,我们参考的是给定的公式
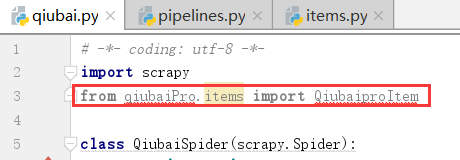
下面我们再爬虫文件中导入类,爆红是不一定代表出错,在这里可以体现
下面我们可以实例化这个item对象,
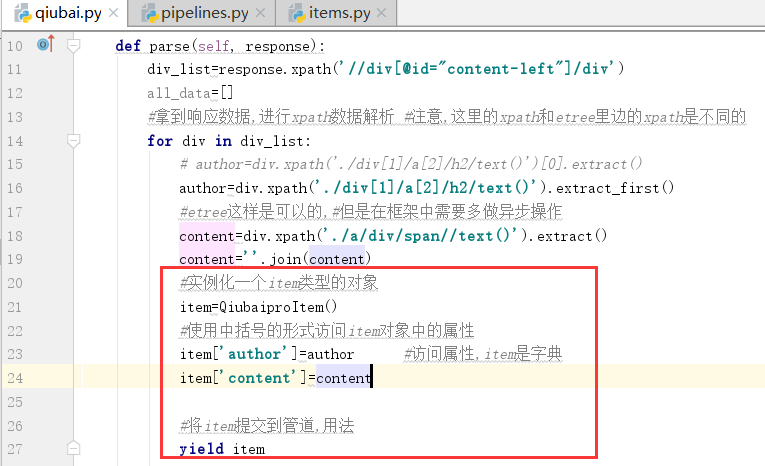
上边的for循环执行几次,在下面的process_item执行几次
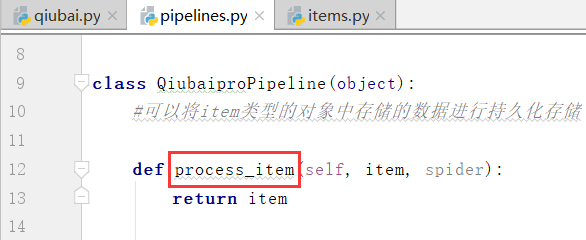
写完函数:
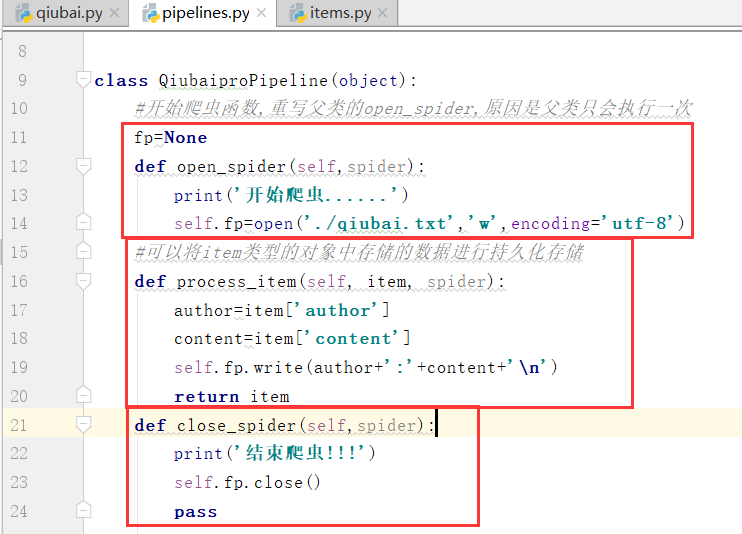
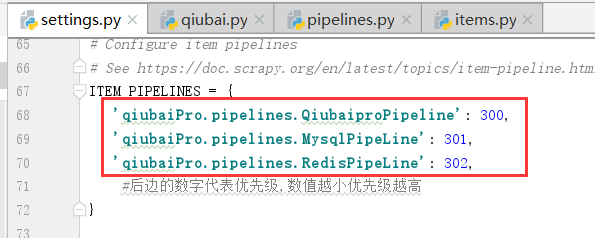
写完函数,我们需要在settings.py配置文件中开启管道.

什么时间定义多个管道类?items.py文件中的什么时间定义成字符串类型?
运行下面的命令:
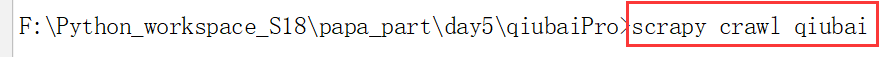
我们看到下面的开始和结束爬虫


这个时候,我们生成了一个txt持久化的文件
注意,下图为什么不用字符串类型,用json类型?Field是万能的数据类型,什么都能存储
思考,什么时间定义多个管道?
一份redis,一份本地存储,一份mysql,这个时候就需要多个管道类
导入一个pymysql
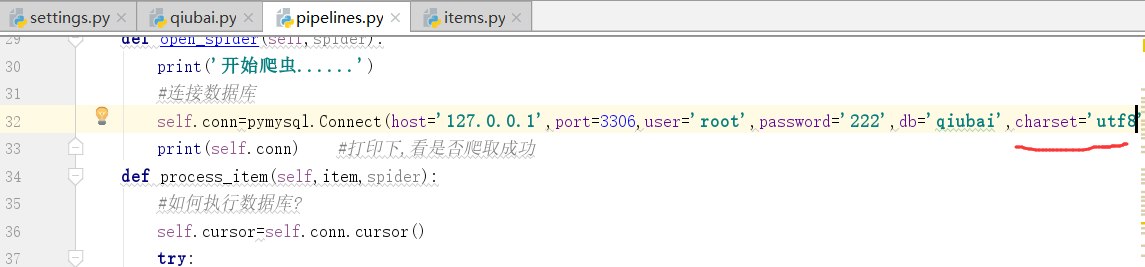
登录数据库
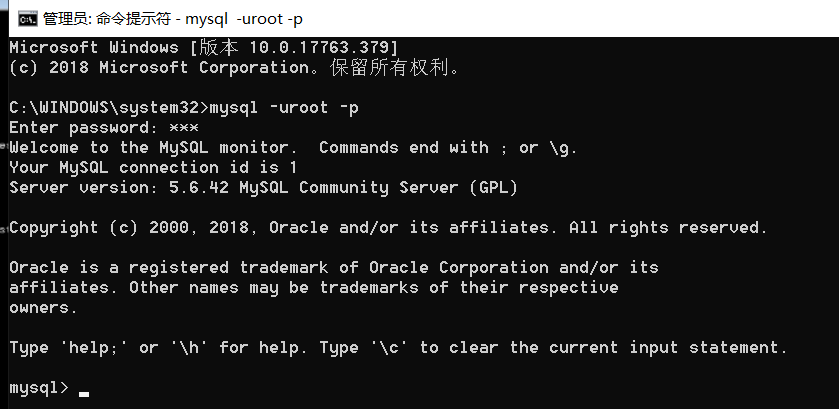


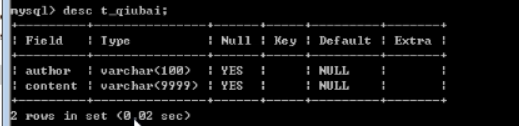

下面,我们新建一个数据库

下面创建一个表

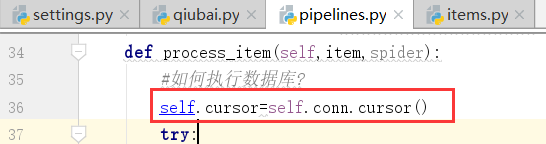
下面,我们连接数据库
在open中连接数据库
mysql端口:3306
redis端口:6379
修改下面的管道配置文件settings.py
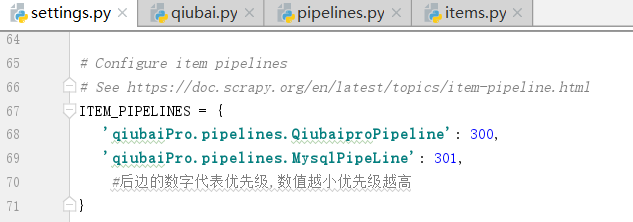
现在有两个管道类,谁先执行

我们的爬虫文件只提交了一个item,我们该如何处理?按照顺序,一定是献给了Qiubai,因为上边的这个数字Qiubai比Mysql小
当第一个类处理完item,第二个没有item了,我们该如何操作?
我们没有说哦process_item的返回值是什么?也就是这个函数有返回值,返回给的是下一个执行的管道类也就是item,症结就在这个地方
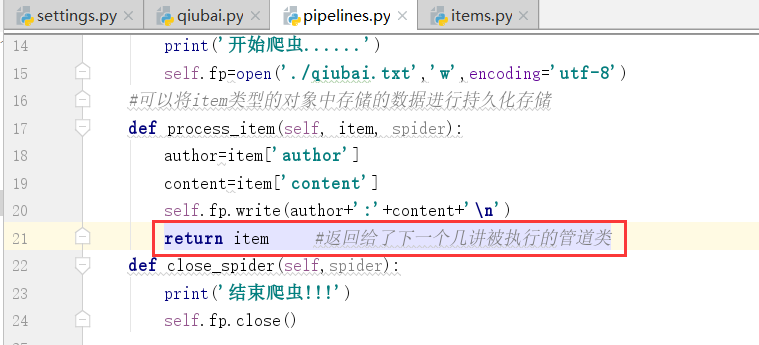
以此类推,我们加上这么一个管道类的返回值
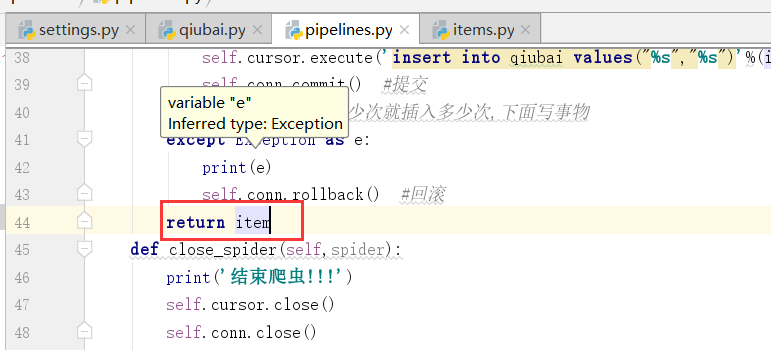
下面执行一下,看是否会有错,可能会出现数据库编码的问题
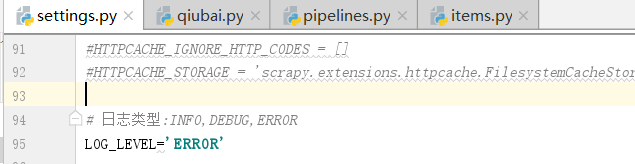
总结数据库日志类型:INFO,DEBUG,ERROR
我们可以指定日志输出的类型
运行得到下面的结果:

原因:
运行,得到下面的结果:

在执行这个过程中可能会出现编码问题,如何修改?

我们在连接的时候加上

查看上边表qiubai的信息
我们在分布式的时候会用到redis
启动redis

导入redis包
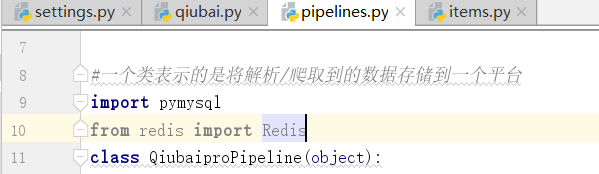
下面开始写类
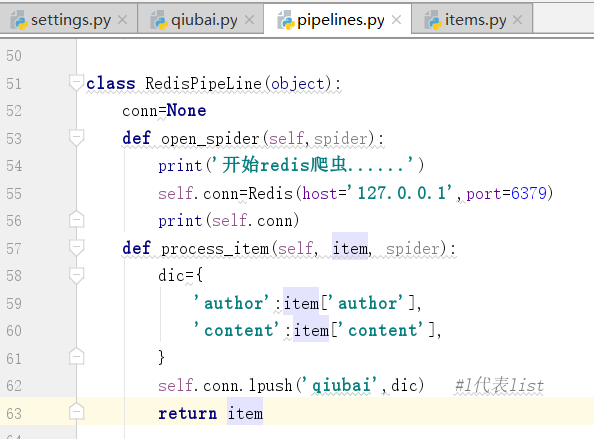
=
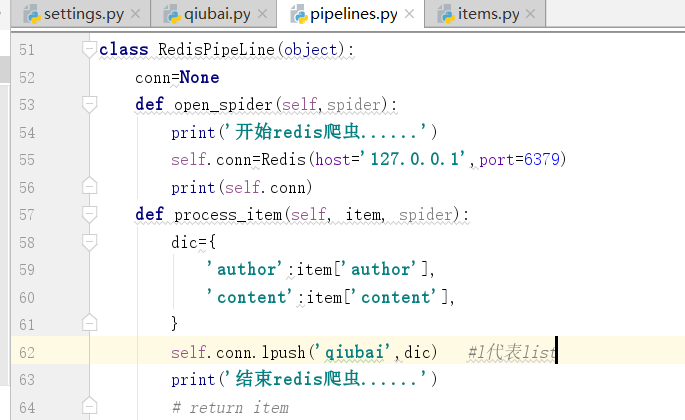
重新安装redis,换成2的版本
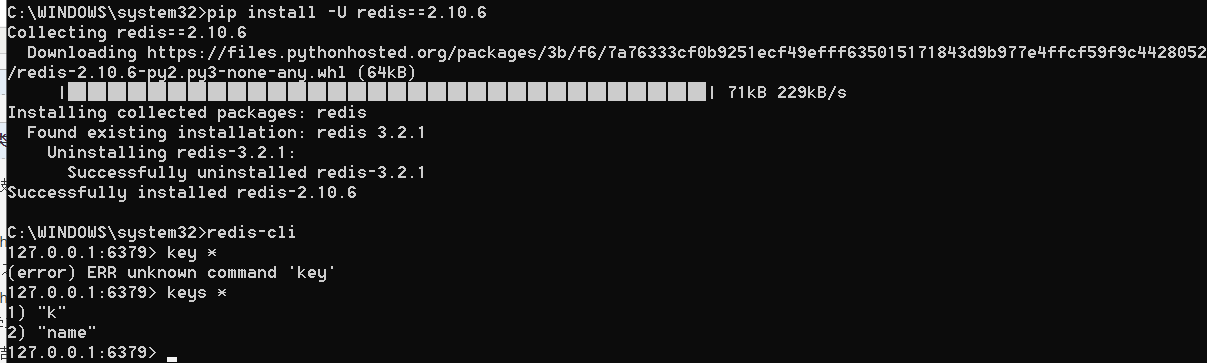
再次运行,我们可以成功执行
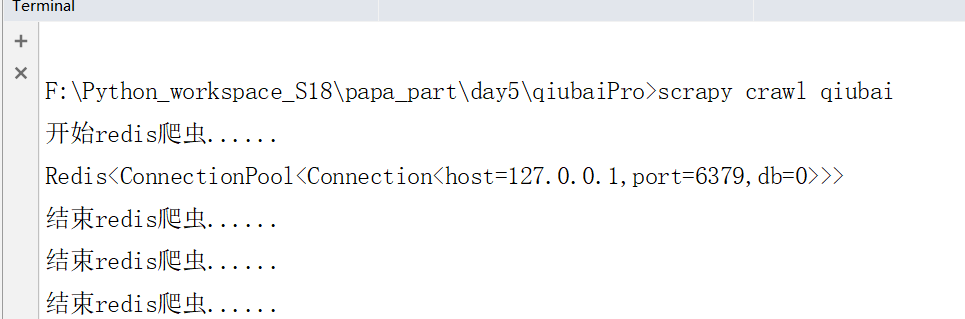
我们可以看到下面的内容qiubai
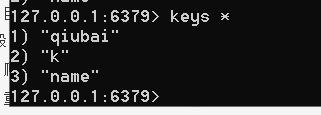
之一txt和mysql以及redis不能混合使用,容易报错
运行下面的命令,我们可以看到一串二进制数字.

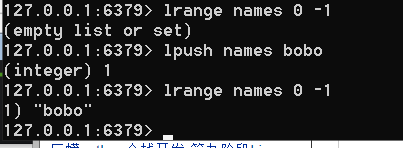
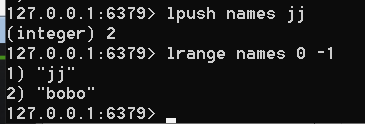
lpush names 'bobo'
添加和删除,见下图
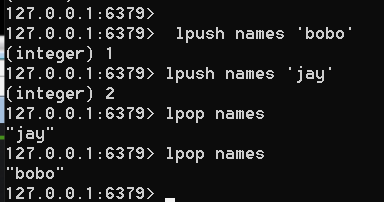
0到-1是全部取出,得到下面的内容
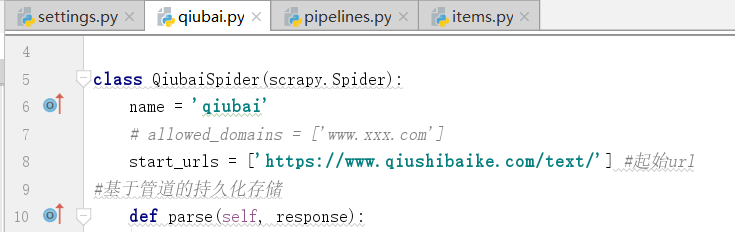
现在,我们只是发起了一个页面,我们将所有页码的url都放在start_urls列表中
如何爬取多个页码中的数据,请看下一节
小爬爬5:scrapy介绍3持久化存储的更多相关文章
- 小爬爬5:scrapy介绍2
1.scrapy:爬虫框架 -框架:集成了很多功能且具有很强通用性的一个项目模板 -如何学习框架:(重点:知道有哪些模块,会用就行) -学习框架的功能模板的具体使用. 功能:(1)异步爬取(自带buf ...
- scrapy框架的持久化存储
一 . 基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存 ...
- 小爬爬6.scrapy回顾和手动请求发送
1.数据结构回顾 #栈def push(self,item) def pop(self) #队列 def enqueue(self,item) def dequeue(self) #列表 def ad ...
- 11.scrapy框架持久化存储
今日概要 基于终端指令的持久化存储 基于管道的持久化存储 今日详情 1.基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的 ...
- scrapy框架持久化存储
基于终端指令的持久化存储 基于管道的持久化存储 1.基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文 ...
- Scrapy持久化存储
基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作; 执行输出指定格式进行存储:将爬 ...
- Scrapy持久化存储-爬取数据转义
Scrapy持久化存储 爬虫爬取数据转义问题 使用这种格式,会自动帮我们转义 'insert into wen values(%s,%s)',(item['title'],item['content' ...
- 10 Scrapy框架持久化存储
一.基于终端指令的持久化存储 保证parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存储:将爬取到的 ...
- scrapy之持久化存储
scrapy之持久化存储 scrapy持久化存储一般有三种,分别是基于终端指令保存到磁盘本地,存储到MySQL,以及存储到Redis. 基于终端指令的持久化存储 scrapy crawl xxoo - ...
随机推荐
- 一句代码上传MultipartFile图片到指定文件夹
代码如下: public class TestFile { void upload(MultipartFile file) throws IOException { file.transferTo(n ...
- Spring Cloud中Eureka开启密码认证
转载自 https://blog.csdn.net/u011499747/article/details/77410997 Eureka服务端配置 添加spring-boot-starter-secu ...
- css3新特性概览
一.特性 1.强大的选择器 2.半透明度效果的实现 3.多栏布局 4.多背景图 css3允许背景属性设置多个属性值,如:background-image,background-repeat,backg ...
- LINUX对超级用户和普通用户的理解
什么是超级用户 在所有Linux系统中,系统都是通过UID来区分用户权限级别的,而UID为0的用户被系统约定为是具有超级权限.超级用户具有在系统约定的最高权限满园内操作,所以说超级用户可以完成系统管理 ...
- 彻底理解setTimeout()
之前在网上看了很多关于setTimeout的文章,但我感觉都只是点到为止,并没有较深入的去剖析,也可能是我脑袋瓜笨,不容易被点解.后面看了<你不知道的javascript-上卷>一书,决定 ...
- Linux字体美化实战(Fontconfig配置)(转)
原文地址:http://www.jinbuguo.com/gui/linux_fontconfig.html 本文的主题是Linux环境下的字体美化,但是首先得要有字体,然后才能谈美化.所以第一件事就 ...
- WWDC 上讲到的 Objective C / LLVM 改进
https://developer.apple.com/wwdc/videos/ Advances in Objective-C What's New in the LLVM Compiler 下面是 ...
- Delphi 设计模式:《HeadFirst设计模式》Delphi7代码---命令模式之RemoteControlTest[转]
1 2{<HeadFirst设计模式>之命令模式 } 3{ 本单元中的类为命令的接收者 } 4{ 编译工具 :Delphi7.0 } 5{ 联 ...
- ubuntu 安装 go 编译环境
参考: http://wiki.ubuntu.org.cn/Golang 从仓库安装(apt-get) sudo apt-get install golang 修改环境变量: vim /etc/env ...
- solr问题missing content stream
在使用solrj建立索引的时候,报错:missing content stream; 原因在于 HttpSolrServer httpSolrServer = new HttpSolrServer(s ...