强化学习 reinforcement learning: An Introduction 第一章, tic-and-toc 代码示例 (结构重建版,注释版)
强化学习入门最经典的数据估计就是那个大名鼎鼎的 reinforcement learning: An Introduction 了, 最近在看这本书,第一章中给出了一个例子用来说明什么是强化学习,那就是tic-and-toc游戏, 感觉这个名很不Chinese,感觉要是用中文来说应该叫三子棋啥的才形象。

这个例子就是下面,在一个3*3的格子里面双方轮流各执一色棋进行对弈,哪一方先把自方的棋子连成一条线则算赢,包括横竖一线,两个对角线斜连一条线。
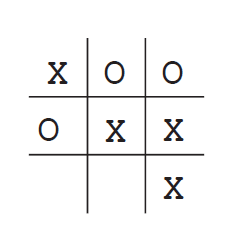

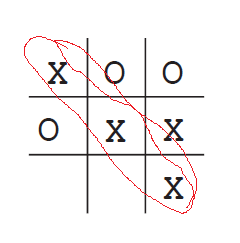
上图,则是 X 方赢,即:
reinforcement learning 的对应代码地址为:
https://github.com/ShangtongZhang/reinforcement-learning-an-introduction
该代码虽然很好,但是看起来较费力,于是自己就该它的基础上加了些注释并把结构进行了改动,具体代码如下:
源码地址:(本文给出的结构重建,注释版)
https://files.cnblogs.com/files/devilmaycry812839668/tic_tac_toe_code.zip
关于算法的解释可以具体参见书中的介绍,Reinforcement Learning:An Introduction 第一章
关于这个代码的,或者说是算法的设计主要是为了解释什么是时序差分的强化学习。
每一种状态都用一个值来表示,并用一个hash码表示,
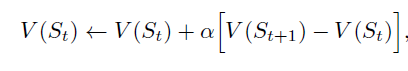
St 是此刻的棋盘状态值, St+1 是下一时刻的棋盘状态值。但是, 如果St状态到St+1 状态是因为自方进行策略探索而选择的不是最优的下一状态的动作,那么不进行此次计算。
状态值的变化树结构如下图:
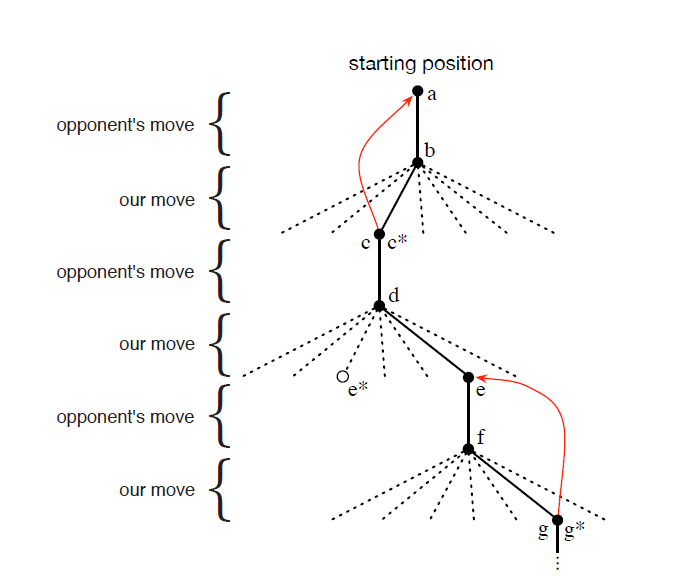
由 d 状态 到 e* 状态是此时可以选择的最优状态,但是我们选择了进入 e 状态的操作,这就是策略的探索操作。
具体的算法思想参照 reinforcement learning: An Introduction 原书。
==========================================================
目录结构如下图:

tic_tac_toe.py 是代码的主文件,需要运行该代码。
enviroment 文件夹中放的是 关于棋盘状态的类文件代码,和环境初始化的代码。

agents 文件夹中放的是 具体的下起策略中agent的代码:

interface.py 中的代码是 agent 代码和主程序的接口文件:
主文件 tic_toe_tac.py
强化学习 reinforcement learning: An Introduction 第一章, tic-and-toc 代码示例 (结构重建版,注释版)的更多相关文章
- 强化学习(Reinforcement Learning)中的Q-Learning、DQN,面试看这篇就够了!
1. 什么是强化学习 其他许多机器学习算法中学习器都是学得怎样做,而强化学习(Reinforcement Learning, RL)是在尝试的过程中学习到在特定的情境下选择哪种行动可以得到最大的回报. ...
- Learning From Data 第一章总结
之前上了台大的机器学习基石课程,里面用的教材是<Learning from data>,最近看了看觉得不错,打算深入看下去,内容上和台大的课程差不太多,但是有些点讲的更深入,想了解课程里面 ...
- 《Machine Learning》(第一章)序章
关键词:机器学习,基本术语,假设空间,归纳偏好,机器学习用途 一.机器学习概述 机器学习是一门从数据中,经过计算得到模型(Model)的一种过程,得到的模型不仅能反应出训练数据集中所蕴含的规律,并且能 ...
- 强化学习(Reinfment Learning) 简介
本文内容来自以下两个链接: https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/ https: ...
- 【php学习】PHP 入门经典第一章笔记
第一章: php在线手册:http://php.net/manual/zh/index.php 在开始学习PHP之前,先来看一个合格的PHP程序员今后应具备哪些知识,这里只是笔者的一些总结,希望对读者 ...
- 《Deep Learning》译文 第一章 前言(中) 神经网络的变迁与称谓的更迭
转载请注明出处. 第一章 前言(中) 1.1 本书适合哪些人阅读? 能够说本书的受众目标比較广泛,可是本书可能更适合于例如以下的两类人群.一类是学习过与机器学习相关课程的大学生们(本科生或者研究生). ...
- Reinforcement Learning: An Introduction读书笔记(3)--finite MDPs
> 目 录 < Agent–Environment Interface Goals and Rewards Returns and Episodes Policies and Val ...
- 【java并发编程艺术学习】(二)第一章 java并发编程的挑战
章节介绍 主要介绍并发编程时间中可能遇到的问题,以及如何解决. 主要问题 1.上下文切换问题 时间片是cpu分配给每个线程的时间,时间片非常短. cpu通过时间片分配算法来循环执行任务,当前任务执行一 ...
- 《STL源码剖析》学习半生记:第一章小结与反思
不学STL,无以立.--陈轶阳 从1.1节到1.8节大部分都是从各方面介绍STL, 包括历史之类的(大致上是这样,因为实在看不下去我就直接略到了1.9节(其实还有一点1.8.3的内容)). 第一章里比 ...
随机推荐
- 【Android】查看包名和首启动activity
工具:aapt 位置:$ANDROID_HOME/build-tools/版本号/aapt 需要配置环境变量才能使用 aapt dump badging XXXapk 输出信息中重要的有: packa ...
- aria2c --enable-rpc --rpc-listen-all -D
在后台启动的方法,如题, 用来配合 web-aria2
- Freemarker生成HTML静态页面
这段时间的工作是做一个网址导航的项目,面向用户的就是一个首页,于是就想到了使用freemarker这个模板引擎来对首页静态化. 之前是用jsp实现,为了避免用户每次打开页面都查询一次数据库,所以使用了 ...
- 12月13日 什么是help_method,session的简单理解, find_by等finder method
helper_method Declare a controller method as a helper. For example, helper_method :link_to def link_ ...
- Java 访问控制关键字
public, private, protected 在控制上有什么区别和不同请参考下面的说明. 请参考下图的说明. 和下面的一个说明: │ Class │ Package │ Subclass │ ...
- 加密算法(DES,AES,RSA,MD5,SHA1,Base64)比较和项目应用
加密技术通常分为两大类:"对称式"和"非对称式". 对称性加密算法:对称式加密就是加密和解密使用同一个密钥.信息接收双方都需事先知道密匙和加解密算法且其密匙是相 ...
- XMLItergration.java
/*===========================================================================+ | Copyright (c) 2001, ...
- 用js实现个优先队列吧
队列是一种很常用的数据结构,它是一组遵循先进先出(FIFO)规则的项.在现实生活中,最常见的队列的例子就是排队.队列有一些方法,入队.出队.队列的长度,清空队列等.用js实现一个普通的队列代码如下: ...
- c++ 发送消息,模拟拖拽文件
#include <ShlObj.h> BOOL SimulateDropFile(CString strFilePath) { }; wcstombs(szFile, strFilePa ...
- VC++ 报错:Heap corruption detected
今天在写代码时,发现莫名其妙的错误: std::string strName = L“testtest”; char* pOutString = new char(len + 1); Decrypt( ...