用Python写简单的爬虫
准备:
1.扒网页,根据URL来获取网页信息
import urllib.parse
import urllib.request
response = urllib.request.urlopen("https://www.cnblogs.com")
print(response.read())
urlopen方法
urlopen(url, data, timeout)
url即为URL,data是访问URL时要传送的数据,timeout是设置超时时间
返回response对象
response对象的read方法,可以返回获取到的网页内容
POST方式
import urllib.parse
import urllib.request
values = {"username":"XXX","password":"XXX"}
data = urllib.parse.urlencode(values)
data = data.encode('utf-8')
url = "https://passport.cnblogs.com/user/signin?ReturnUrl=https://home.cnblogs.com/&AspxAutoDetectCookieSupport=1"
response = urllib.request.urlopen(url,data)
print(response.read())
GET方式
import urllib.parse
import urllib.request
values = {"itemCount":30}
data = urllib.parse.urlencode(values)
data = data.encode('utf-8')
url = "https://news.cnblogs.com/CommentAjax/GetSideComments"
data = urllib.parse.urlencode(values)
response = urllib.request.urlopen(url+'?'+data)
print(response.read())
2.正则表达式re模块
Python 自带了re模块,提供了对正则表达式的支持
#返回pattern对象
re.compile(string[,flag])
#以下为匹配所用函数
re.match(pattern, string[, flags]) #在字符串中查找,是否能匹配正则表达式
re.search(pattern, string[, flags]) #字符串的开头是否能匹配正则表达式
re.split(pattern, string[, maxsplit]) #通过正则表达式将字符串分离
re.findall(pattern, string[, flags]) #找到 RE 匹配的所有子串,并把它们作为一个列表返回
re.finditer(pattern, string[, flags]) #找到 RE 匹配的所有子串,并把它们作为一个迭代器返回
re.sub(pattern, repl, string[, count]) #找到 RE 匹配的所有子串,并将其用一个不同的字符串替换
re.subn(pattern, repl, string[, count])#返回 (sub(repl, string[, count]), 替换次数)
3.Beautiful Soup,是从网页抓取数据的库,使用时需要导入 bs4 库
4.MongoDB
使用的MongoEngine库
示例:
抓取博客园前20页数据,保存到MongoDB中
1.获取博客园的数据
request.py
import urllib.parse
import urllib.request
def getHtml(url,values):
data = urllib.parse.urlencode(values)
response_result = urllib.request.urlopen(url+'?'+data).read()
html = response_result.decode('utf-8')
return html def requestCnblogs(num):
print('请求数据page:',num)
url = 'https://www.cnblogs.com/mvc/AggSite/PostList.aspx'
values= {
'CategoryId':808,
'CategoryType' : 'SiteHome',
'ItemListActionName' :'PostList',
'PageIndex' : num,
'ParentCategoryId' : 0,
'TotalPostCount' : 4000
}
result = getHtml(url,values)
return result
注:
打开第二页,f12,找到https://www.cnblogs.com/mvc/AggSite/PostList.aspx
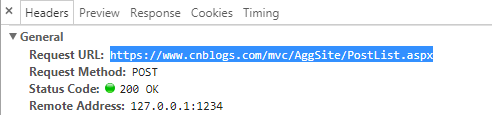

2.解析获取来的数据
deal.py
from bs4 import BeautifulSoup
import request
import re
def blogParser(index):
cnblogs = request.requestCnblogs(index)
soup = BeautifulSoup(cnblogs, 'html.parser')
all_div = soup.find_all('div', attrs={'class': 'post_item_body'}, limit=20)
blogs = []
#循环div获取详细信息
for item in all_div:
blog = analyzeBlog(item)
blogs.append(blog)
return blogs def analyzeBlog(item):
result = {}
a_title = find_all(item,'a','titlelnk')
if a_title is not None:
result["title"] = a_title[0].string
result["link"] = a_title[0]['href']
p_summary = find_all(item,'p','post_item_summary')
if p_summary is not None:
result["summary"] = p_summary[0].text
footers = find_all(item,'div','post_item_foot')
footer = footers[0]
result["author"] = footer.a.string
str = footer.text
time = re.findall(r"发布于 .+? .+? ", str)
result["create_time"] = time[0].replace('发布于 ','')
return result def find_all(item,attr,c):
return item.find_all(attr,attrs={'class':c},limit=1)
注:
分析html结构
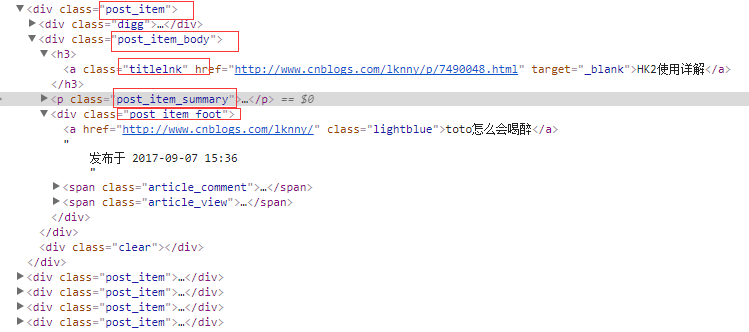
3.将处理好的数据保存到MongoDB
db.py
from mongoengine import *
connect('test', host='localhost', port=27017)
import datetime
class Blogs(Document):
title = StringField(required=True, max_length=200)
link = StringField(required=True)
author = StringField(required=True)
summary = StringField(required=True)
create_time = StringField(required=True) def savetomongo(contents):
for content in contents:
blog = Blogs(
title=content['title'],
link= content['link'],
author=content['author'],
summary=content['summary'],
create_time=content['create_time']
)
blog.save()
return "ok" def haveBlogs():
blogs = Blogs.objects.all()
return len(blogs)
4.开始抓取数据
test.py
import db
import deal
print("start.......")
for i in range(1, 21):
contents = deal.blogParser(i)
db.savetomongo(contents)
print('page',i,' OK.')
counts = db.haveBlogs()
print("have ",counts," blogs")
print("end.......")

注:
当前使用的Python版本是3.6.1
可以在可视化工具中查看(可是化工具 介绍 )

用Python写简单的爬虫的更多相关文章
- 【Python开发】【神经网络与深度学习】如何利用Python写简单网络爬虫
平时没事喜欢看看freebuf的文章,今天在看文章的时候,无线网总是时断时续,于是自己心血来潮就动手写了这个网络爬虫,将页面保存下来方便查看 先分析网站内容,红色部分即是网站文章内容div,可以看 ...
- Python 利用Python编写简单网络爬虫实例3
利用Python编写简单网络爬虫实例3 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://bbs.51testing. ...
- Python 利用Python编写简单网络爬虫实例2
利用Python编写简单网络爬虫实例2 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://www.51testing. ...
- 爬虫入门-使用python写简单爬虫
从第一章到上一章为止,基本把python所有的基础点都已经包括了,我们有控制逻辑的关键字,有内置数据结构,有用于工程需要的函数和模块,又有了标准库和第三方库,可以写正规的程序了. python可以做非 ...
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
前面一直强调Python运用到网络爬虫方面很有效,这篇文章也是结合学习的Python视频知识及我研究生数据挖掘方向的知识.从而简介下Python是怎样爬去网络数据的,文章知识很easy ...
- 使用Python编写简单网络爬虫抓取视频下载资源
我第一次接触爬虫这东西是在今年的5月份,当时写了一个博客搜索引擎.所用到的爬虫也挺智能的,起码比电影来了这个站用到的爬虫水平高多了! 回到用Python写爬虫的话题. Python一直是我主要使用的脚 ...
- 使用python实现简单的爬虫
python爬虫的简单实现 开发环境的配置 python环境的安装 编辑器的安装 爬虫的实现 包的安装 简单爬虫的初步实现 将数据写入到数据库-简单的数据清洗-数据库的连接-数据写入到数据库 开发环境 ...
- Python实现简单的爬虫获取某刀网的更新数据
昨天晚上无聊时,想着练习一下Python所以写了一个小爬虫获取小刀娱乐网里的更新数据 #!/usr/bin/python # coding: utf-8 import urllib.request i ...
- 用Python写一个小爬虫吧!
学习了一段时间的web前端,感觉有点看不清前进的方向,于是就写了一个小爬虫,爬了51job上前端相关的岗位,看看招聘方对技术方面的需求,再有针对性的学习. 我在此之前接触过Python,也写过一些小脚 ...
随机推荐
- Xcode7.3 beta 新功能 https://developer.apple.com/go/?id=xcode-7.3-rn
Xcode7.3 beta 新功能html, body {overflow-x: initial !important;}html { font-size: 14px; } body { margin ...
- css部分样式资料
1. css字体 Lato,"Helvetica Neue","Segoe UI",Helvetica,Arial,sans-serif
- js+jquery检测用户浏览器型号(转)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- [RTC]系统时间NTP和RTC同步,Debian的时区配置
转自:http://www.cnblogs.com/jiu0821/p/5999566.html Debian的时区配置 一. 修改时区 1. 查看当前时区 命令 : "date -R&qu ...
- Anaconda下载(改变了镜像路径,下载速度很快!!!)
Anaconda下载(改变了镜像路径,下载速度很快!!!) 使用conda install 包名 安装需要的Python非常方便,但是官方的服务器在国外,因此下载速度很慢,国内清华大学提供了Anaco ...
- c# dump 程序崩溃 windbg
待研究 http://issf.blog.163.com/blog/static/194129082201002534895/ http://www.cppblog.com/woaidongmao/a ...
- 两种常用的jquery事件加载的方法 的区别
两种常用的jquery事件加载的方法 $(function(){}); window.onload=function(){} 第一个呢,是在DOM结构渲染完成以后调用的,这时候网页中一些资源还 ...
- js 的数值限制可能引起的问题
源于:https://raw.github.com/ruanyf/jstutorial/gh-pages/grammar/number.md 1. 根据国际标准IEEE 754,64位浮点数格式的64 ...
- React Native常用第三方组件汇总--史上最全[转]
本文出处: http://blog.csdn.net/chichengjunma/article/details/52920137 React Native 项目常用第三方组件汇总: react-na ...
- 记录一下寄几个儿的greendao数据库升级,可以说是非常菜鸡了嗯
之前使用的greendao数据库存储服务器所有的历史推送消息,但是后来消息需要加几个新的字段 举个栗子,比如要新增红色框住的字段到数据库中: 本仙女作为一只思想成熟的菜鸡,当然是加了字段就赶紧重新往里 ...