R包 randomForest 进行随机森林分析
randomForest 包提供了利用随机森林算法解决分类和回归问题的功能;我们这里只关注随机森林算法在分类问题中的应用
首先安装这个R包
install.packages("randomForest")
安装成功后,首先运行一下example
library(randomForset)
?randomForset
通过查看函数的帮助文档,可以看到对应的example
data(iris)
set.seed(71)
iris.rf <- randomForest(Species ~ ., data=iris, importance=TRUE,
proximity=TRUE)
print(iris.rf)
代码很简单,全部的功能都封装在 randomForest 这个R包中,首先来看下用于分类的数据
> str(iris)
'data.frame': 150 obs. of 5 variables:
$ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
$ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
$ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
采用数据集iris 进行分类,iris 数据集共有150行,5列,其中第5列为分类变量,共有3种分类情况,这个数据集可以看做150个样本,根据4个指标进行分类,最终分成了3类
接下来调用randomForest 函数就行分类
iris.rf <- randomForest(Species ~ ., data=iris, importance=TRUE, proximity=TRUE)
调用该函数时,通过一个表达式指定分类变量 Species 和对应的数据集data 就可以了,后面的importance 和 proximity 是计算每个变量的重要性和样本之间的距离
分类器构建完毕之后,首先看一下这个分类器的准确性
> print(iris.rf) Call:
randomForest(formula = Species ~ ., data = iris, importance = TRUE, proximity = TRUE)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 2 OOB estimate of error rate: 4%
Confusion matrix:
setosa versicolor virginica class.error
setosa 50 0 0 0.00
versicolor 0 47 3 0.06
virginica 0 3 47 0.06
print 的结果中,OOB estimate of error rate 表明了分类器的错误率为4%, Confusion matrix 表明了每个分类的详细的分类情况;
对于setosa 这个group而言,基于随机森林算法的分类器,有50个样本分类到了setosa 这个group, 而且这50个样本和iris 中属于setosa 这个group的样本完全一致,所以对于setosa 这个group而言,分类器的错误率为0;
对于versicolor 这个group而言,基于随机森林算法的分类器,有47个样本分类到了versicolor 这个group, 3个样本分类到了virginica 这个group,有3个样本分类错误,在iris 中属于versicolor 这个group的样本有50个,所以对于versicolor 这个group而言,分类器的错误率为3/50 = 0.06 ;
对于virginica 这个group而言,基于随机森林算法的分类器,有3个样本分类到了versicolor 这个group, 47个样本分类到了virginica 这个group,有3个样本分类错误,在iris 中属于virginica 这个group的样本有50个,所以对于virginica这个group而言,分类器的错误率为3/50 = 0.06 ;
然后看一下样本之间的距离
iris.mds <- cmdscale(1 - iris.rf$proximity, eig=TRUE)
通过调用cmdscale 函数进行样本之间的距离,proximity 是样本之间的相似度矩阵,所以用1减去之后得到样本的类似距离矩阵的一个矩阵
iris.mds 的结果如下
> str(iris.mds)
List of 5
$ points: num [1:150, 1:2] -0.566 -0.566 -0.566 -0.565 -0.565 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:150] "1" "2" "3" "4" ...
.. ..$ : NULL
$ eig : num [1:150] 23.87 20.89 2.32 1.67 1.23 ...
$ x : NULL
$ ac : num 0
$ GOF : num [1:2] 0.723 0.786
> head(iris.mds$points)
[,1] [,2]
1 -0.5656446 0.01611053
2 -0.5656904 0.01585927
3 -0.5656267 0.01654988
4 -0.5651292 0.01649026
5 -0.5653773 0.01576609
6 -0.5651923 0.01663060
在iris.mds 中points可以看做每个样本映射到2维空间中的坐标,每一维空间是一个分类特征,但是不是最原始的4个特征,而是由4个特征衍生得到的新的分类特征,根据这个坐标,可以画一张散点图,得到每个样本基于两个分类变量的分组情况
plot(iris.mds$points, col = rep(c("red", "blue", "green"), each = 50))
生成的图片如下:
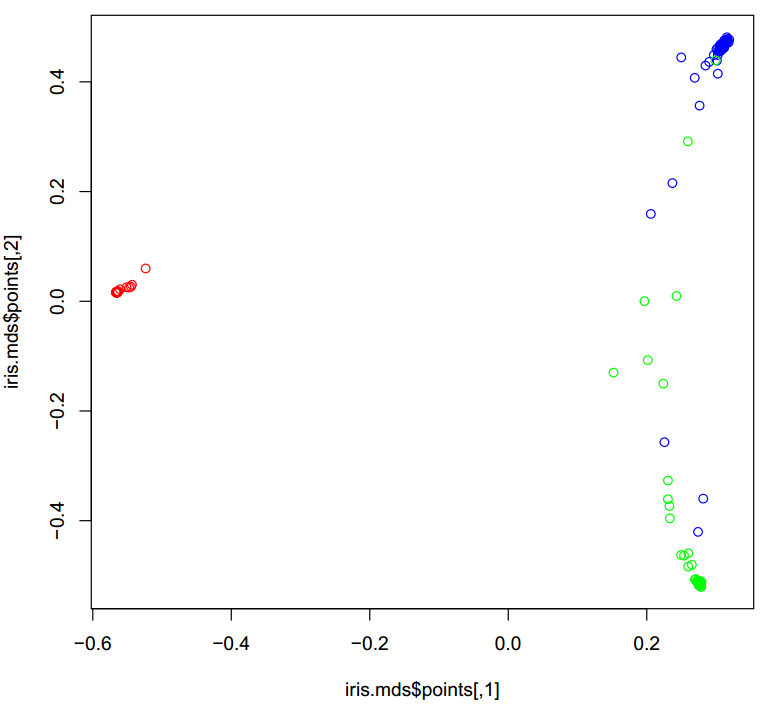
图中不同分类的样本用不同的颜色标注,可以看到基于两个新的分类特征,样本的分组效果还是很好的,不同组的样本明显区分开来
最后,在看一下4个特征,每个特征的重要性
> iris.rf$importance
setosa versicolor virginica MeanDecreaseAccuracy
Sepal.Length 0.027726158 0.0202591689 0.03688967 0.028920613
Sepal.Width 0.007300694 0.0006999737 0.01078650 0.006093858
Petal.Length 0.331994212 0.3171074926 0.31762366 0.319580655
Petal.Width 0.332417881 0.3004615039 0.26540155 0.296416932
MeanDecreaseGini
Sepal.Length 9.013793
Sepal.Width 2.263645
Petal.Length 44.436189
Petal.Width 43.571706
之前调用randomForest 函数时,通过指定importance = TRUE 来计算每个特征的importance , 在 iris.rf$importance 矩阵中,有两个值是需要重点关注的MeanDecreaseAccuracy 和 MeanDecreaseGini
我们还可以利用
varImpPlot(iris.rf, main = "Top 30 - variable importance")
生成的图片如下:
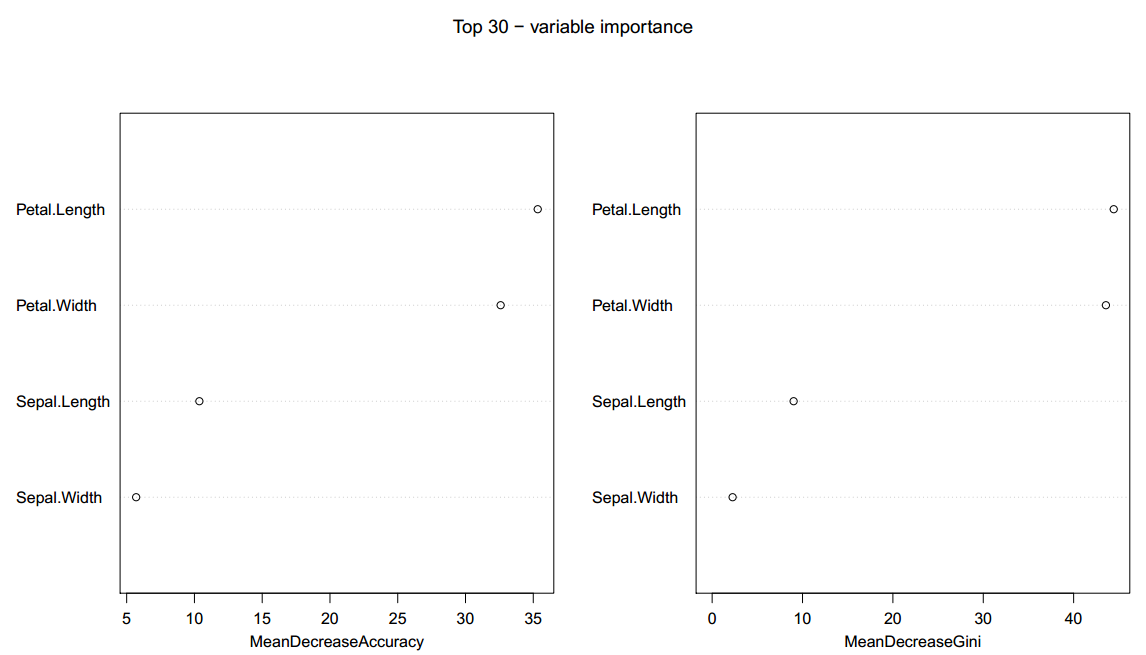
图中和坐标为importance 结果中的MeanDecreaseAccuracy 和 MeanDecreaseGini 指标的值,纵坐标为对应的每个分类特征,该函数默认画top30个特征,由于这个数据集只有4个分类特征,所以4个都出现了
R包 randomForest 进行随机森林分析的更多相关文章
- R语言︱决策树族——随机森林算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:有一篇<有监督学习选择深度学习 ...
- 笔记+R︱风控模型中变量粗筛(随机森林party包)+细筛(woe包)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本内容来源于CDA-DSC课程内容,原内容为& ...
- R语言之Random Forest随机森林
什么是随机森林? 随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法.随机森林的名称中有 ...
- 随机森林入门攻略(内含R、Python代码)
随机森林入门攻略(内含R.Python代码) 简介 近年来,随机森林模型在界内的关注度与受欢迎程度有着显著的提升,这多半归功于它可以快速地被应用到几乎任何的数据科学问题中去,从而使人们能够高效快捷地获 ...
- 【R语言进行数据挖掘】决策树和随机森林
1.使用包party建立决策树 这一节学习使用包party里面的函数ctree()为数据集iris建立一个决策树.属性Sepal.Length(萼片长度).Sepal.Width(萼片宽度).Peta ...
- ML—随机森林·1
Introduction to Random forest(Simplified) With increase in computational power, we can now choose al ...
- Python 实现的随机森林
随机森林是一个高度灵活的机器学习方法,拥有广泛的应用前景,从市场营销到医疗保健保险. 既可以用来做市场营销模拟的建模,统计客户来源,保留和流失.也可用来预测疾病的风险和病患者的易感性. 随机森林是一个 ...
- 第九篇:随机森林(Random Forest)
前言 随机森林非常像<机器学习实践>里面提到过的那个AdaBoost算法,但区别在于它没有迭代,还有就是森林里的树长度不限制. 因为它是没有迭代过程的,不像AdaBoost那样需要迭代,不 ...
- 随机森林(Random Forest),决策树,bagging, boosting(Adaptive Boosting,GBDT)
http://www.cnblogs.com/maybe2030/p/4585705.html 阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 ...
随机推荐
- 歌曲播放页面的数据vuex管理
1.state.js import {playMode} from '@/common/js/config' const state = { singer:{}, playing:false, ful ...
- 从 shell 眼中看世界
(字符) 展开每一次你输入一个命令,然后按下 enter 键,在 bash 执行你的命令之前, bash 会对输入的字符完成几个步骤处理.我们已经知道两三个案例,怎样一个简单的字符序列,例如 “*”, ...
- EF中的1:0或1:1关系以及1:n关系
先给出1:0关系 User表包括用户名和密码 public class User { public int ID { get; set; } public string UserName { get; ...
- Spirng MVC启动流程
以Tomcat为例,想在Web容器中使用Spirng MVC,必须进行四项的配置: 修改web.xml,添加servlet定义.编写servletname-servlet.xml( servletna ...
- git diff 的用法
git diff 对比两个文件修改的记录 不带参数的调用 git diff filename 这种是比较 工作区和暂存区 比较暂存区与最新本地版本库 git diff --cached filenam ...
- STM32 ADC多通道转换
描述:用ADC连续采集11路模拟信号,并由DMA传输到内存.ADC配置为扫描并且连续转换模式,ADC的时钟配置为12MHZ.在每次转换结束后,由DMA循环将转换的数据传输到内存中.ADC可以连续采集N ...
- PHP判断字符串的包含
PHP语言是一个功能强大的嵌入式HTML脚本语言,它的易用性让许多程序员选择使用.PHP判断字符串的包含,可以使用PHP的内置函数strstr,strpos,stristr直接进行判断.也可以通过ex ...
- JQ 获取地址栏参数
var cat_id = getParamValue("cat_id"); if(cat_id == null){ cat_id = 1; } $("#brand_cat ...
- How Vmware snapshots works
VMware中的快照是对VMDK在某个时间点的“拷贝”,这个“拷贝”并不是对VMDK文件的复制,而是保持磁盘文件和系统内存在该时间点的状态,以便在出现故障后虚拟机能够恢复到该时间点.如果对某个虚拟机创 ...
- 自然语言交流系统 phxnet团队 创新实训 个人博客 (四)
关于项目中个使用到的自然语言语音转文字&文字转语言的个人总结: VOICE_NAME, "xiaoyan");speechSynthesizer.setParameter( ...