python 使用for循环简单爬取图片(1)
现在的网站大多做了反爬处理,找一个能爬的网站还真不容易。
下面开始一步步实现:
1.简单爬录目图片
import urllib.request
import re def gethtml(url):
page=urllib.request.urlopen(url)
html=page.read().decode('utf-8') return html def getimg(html): a=re.compile(r'src="(.+?\.jpg)"')
tp=a.findall(html)
x=0 for img in tp:
urllib.request.urlretrieve(img,'d:/tupian/%s.jpg' % x)
x+=1
url="http://www.meituba.com/yijing/28426.html" html=gethtml(url)
getimg(html)
2.爬图集
这里仅仅是爬取了录目上的图片,还没有涉及到for循环遍历,针对我们的目标,我们要尽可能仔细观察它的规律。
这里我们随便点进去一个图片集,如图:

打开后看到该图片集一共是6张,
分析一下它的url 和页面的源代码:
1,url分析
这里就不贴图片了,我直接说吧
第一张图片(也就是第一页)的url=“http://www.meituba.com/yijing/28426.html”
第二张图片的url=“http://www.meituba.com/yijing/28426_2.html”
。。。。。
第六页图片的url=“http://www.meituba.com/yijing/28426_6.html”
我们可以发现规律,这里直接改一下'_'后面的数字,这里就需要for循环了
2,源代码的规律:
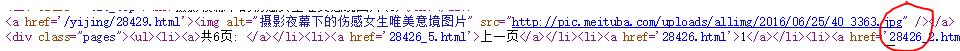
这里我们用正则表达式就应该稍作修改:
应该这样写:r'src="(.+?\.jpg)" /'
好了,下面就开始代码实现:
import urllib.request
import re def gethtml(url):
page=urllib.request.urlopen(url)
html=page.read().decode('utf-8') return html def getimg(html): a=re.compile(r'src="(.+?\.jpg)" /')
b=a.findall(html) for img in b:
urllib.request.urlretrieve(img,'d:/tupian/%s.jpg' % x) x=0 for i in range(1,7): if i==1:
url="http://www.meituba.com/yijing/28426.html"
else:
url=("http://www.meituba.com/yijing/28426_%s.html" % i) html=gethtml(url) x+=1 getimg(html)
1.这里有很多值得我们研究的问题比如第一页的url跟其他页的url有出入,所以我们应该想办法把第一页的图片也加进去,大家可以用if函数实现
看代码吧
2.关于urlretrieve()函数,在保存下载路径的时候要写出全路径,这里的
urllib.request.urlretrieve(img,'d:/tupian/%s.jpg' % x) 就应该做出变化了,我们可以理解一下,在第一个代码中,
我们将 x 这个函数直接定义在函数中,但那是在爬取一个网页下的所有图片,可我们的第二个代码是爬取每个页面下的一张图片,如果我们还是将 x 定义在函数中,那么就会出现一个问题,在文件夹中只会爬到一张图片
大家可以想想原因,
其实当我们用for循环遍历所有url时,getimg()函数是被一遍遍调用的,当第一个url下的图片被爬下来后,它的名称是 0.jpg 那么下一次下一个页面爬到的图片也将被命名为0.jpg
这样系统就只会默认的保存一张图片,所以我们在命名的时候应该注意这一点,
只需要将 x 的初始值定义在for循环的外面就可以了
参考:https://my.oschina.net/talentwang/blog/48524
3.一个图集的图片实在不能满足我们。
一般来说,我们可以通过观察页面url的规律来推出下一个url的地址,可我接下来观察了几个连续图集中的url的信息
28426
28429
28435
28438
28443
28445
28456
28461
本人数学不好,实在发现不了规律,其实在每个图集的下方都会给下一个图集的链接,这就给我们提供了思路,大家如果在爬取某个页面时遇到这种问题,不妨试一下
好了开始我们的代码实现了:下面仅仅是获取下个图集的url地址的代码,其余的下次补全:
import urllib.request
import re
from bs4 import BeautifulSoup def gethtml(url):
page=urllib.request.urlopen(url)
html=page.read().decode('utf-8')
soup=BeautifulSoup(html,'html.parser')
return soup def getimg(html): b=html.find_all("div",{"class":"descriptionBox"})
href=re.compile(r'<b>下一篇:</b><a href="(.+?\.html)">')
c=href.findall(str(b))
print(c)
print(type(c))
e="http://www.meituba.com"+('').join(c)
print(e)
d=urllib.request.urlopen(e)
f=d.read().decode('utf-8')
print(f)
url="http://www.meituba.com/yijing/28426.html"
soup=gethtml(url)
getimg(soup)
运行可以看到它已经可以成功的打印出下一个图集的html页面源代码。
之后再把所有代码总结一下,
今天就写到这,(明天继续)
python 使用for循环简单爬取图片(1)的更多相关文章
- 孤荷凌寒自学python第八十二天学习爬取图片2
孤荷凌寒自学python第八十二天学习爬取图片2 (完整学习过程屏幕记录视频地址在文末) 今天在昨天基本尝试成功的基础上,继续完善了文字和图片的同时爬取并存放在word文档中. 一.我准备爬取一个有文 ...
- 使用Scrapy爬虫框架简单爬取图片并保存本地(妹子图)
初学Scrapy,实现爬取网络图片并保存本地功能 一.先看最终效果 保存在F:\pics文件夹下 二.安装scrapy 1.python的安装就不说了,我用的python2.7,执行命令pip ins ...
- [python学习] 简单爬取图片站点图库中图片
近期老师让学习Python与维基百科相关的知识,无聊之中用Python简单做了个爬取"游讯网图库"中的图片,由于每次点击下一张感觉很浪费时间又繁琐.主要分享的是怎样爬取HTML的知 ...
- 简单的python爬虫教程:批量爬取图片
python编程语言,可以说是新型语言,也是这两年来发展比较快的一种语言,而且不管是少儿还是成年人都可以学习这个新型编程语言,今天南京小码王python培训机构变为大家分享了一个python爬虫教程. ...
- Python爬虫--简单爬取图片
今天晚上弄了一个简单的爬虫,可以爬取网页的图片,现在现在做一下准备工作. 需要的库:urllib 和 re urllib库可以理解为是一个url下载器,其中有三个重要的方法 urllib.urlope ...
- python网络爬虫之四简单爬取豆瓣图书项目
一.爬虫项目一: 豆瓣图书网站图书的爬取: import requests import re content = requests.get("https://book.douban.com ...
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- python如何使用request爬取图片
下面是代码的简单实现,变量名和方法都是跑起来就行,没有整理,有需要的可以自己整理下: image2local: import requests import time from lxml import ...
- python +requests 爬虫-爬取图片并进行下载到本地
因为写12306抢票脚本需要用到爬虫技术下载验证码并进行定位点击所以这章主要讲解,爬虫,从网页上爬取图片并进行下载到本地 爬虫实现方式: 1.首先选取你需要的抓取的URL:2.将这些URL放入待抓 ...
随机推荐
- 跟bWAPP学WEB安全(PHP代码)--邮件头和LDAP注入
背景 由于时间限制和这俩漏洞也不是特别常用,在这里就不搭建环境了,我们从注入原来和代码审计的角度来看看. 邮件头注入 注入原理: 这个地方首先要说一下邮件的结构,分为信封(MAIL FROM.RCPT ...
- 删除个别主机的Know_hosts文件信息
方法一: rm -rf ~/.ssh/known_hosts 缺点:把其他正确的公钥信息也删除,下次链接要全部重新经过认证 方法二: vi ~/.ssh/known_hosts 删除对应ip的相关rs ...
- 改变presentModalView大小
rc.modalTransitionStyle = UIModalTransitionStyleFlipHorizontal; rc.modalPresentationStyle = UIModalP ...
- jQuery相同id元素 全部获取问题解决办法
问题:今天在做页面链接的点击效果时,让部分a链接跳转到同一个地址,即使使用$().each()也同样无法获取所有相同id的值. 用以下方法只有第一个a链接点击可以正常跳转 例如: html代码: &l ...
- python类中的self参数和cls参数
1. self表示一个类的实例对象本身.如果用了staticmethod就无视这个self了,就将这个方法当成一个普通的函数使用了. 2. cls表是这个类本身. # 代码为证 class A(obj ...
- 初学filter
一. Filter介绍 Filter可以认为是Servlet的一种加强版,它主要用于对用户请求进行预处理,也可以对HTTPServletResponse进行后处理,是个典型的处理链.它的完整处理流程是 ...
- MPD大会北京上海两站圆满落幕
MPD大会北京上海两站圆满落幕 由麦思博(MSUP)主办的亚太软件研发团队管理峰会(以下简称MPD大会)分别于6月15及6月22日在北京.上海成功举办.国内外知名软件.互联网行业项目领头人及业内从业人 ...
- codeforces 888A/B/C/D/E - [数学题の小合集]
这次CF不是很难,我这种弱鸡都能在半个小时内连A四道……不过E题没想到还有这种折半+状压枚举+二分的骚操作,后面就挂G了…… A.Local Extrema 题目链接:https://cn.vjudg ...
- Django的URL name 学习
1.打开工程文件下的url.py: from django.contrib import admin from django.urls import path from django.conf.url ...
- Unified Modeling Language
https://en.wikipedia.org/wiki/Unified_Modeling_Language