python +requests 爬虫-爬取图片并进行下载到本地
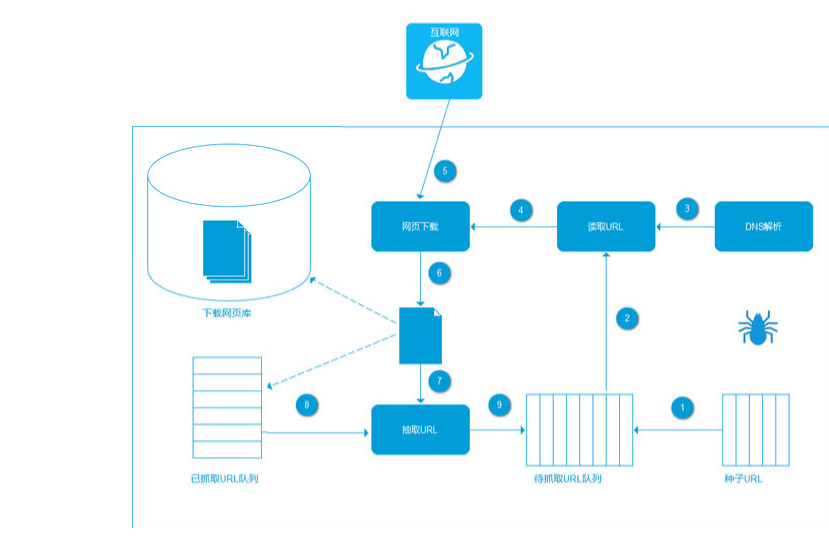
- 爬虫实现方式:
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。

- 环境 :
- python
- re
- requests
- 正则:
pic_url = re.findall('"objURL":"(.*?)",',html, re.S)
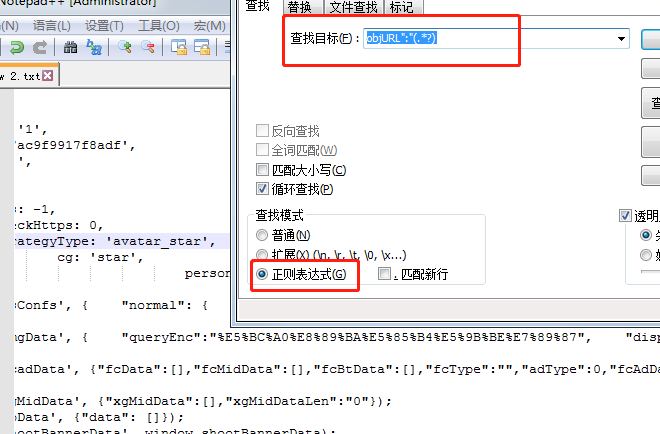
- 小技巧:这边的正则如果你不太确定有没有匹配到的话可以使用notepad++来匹配下
- 第一步查看你需要抓取网页右击查看源代码
- 第二步把代码贴入notepad++中
- 第三步f12查询选择正则进行匹配
- 也可用这个网址:http://tool.oschina.net/regex/#
- 废话不多说直接上代码
import re
import requests def download(html):
#通过正则匹配
pic_url = re.findall('"objURL":"(.*?)",',html, re.S)
i = 1
for key in pic_url:
print("开始下载图片:"+key +"\r\n")
try:
pic = requests.get(key, timeout=10)
except requests.exceptions.ConnectionError:
print('图片无法下载')
continue
#保存图片路径
dir = '保存路径' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
def main():
url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word=lay'
result = requests.get(url)
download(result.text) if __name__ == '__main__':
main()
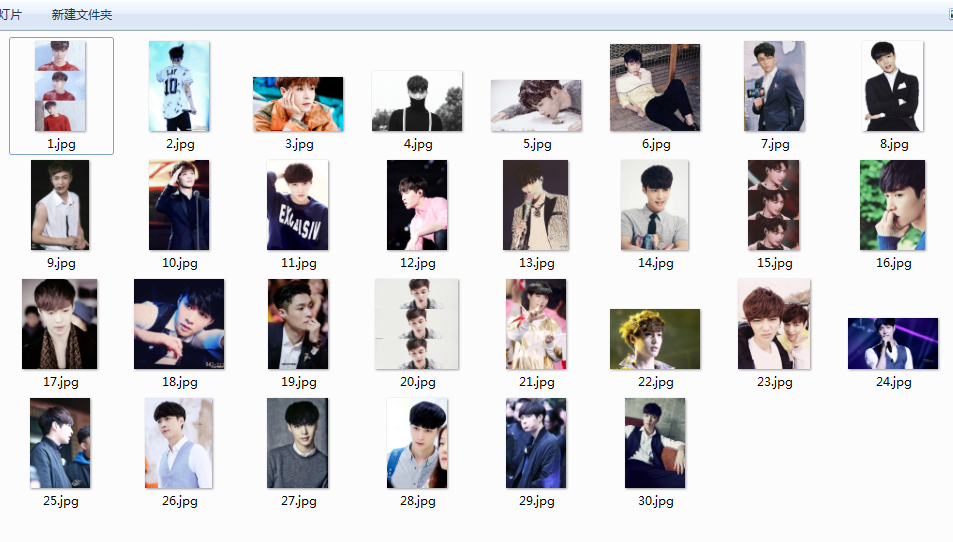
- 最后找到你下载图片的文件,然后看下小绵羊的盛世美颜
python +requests 爬虫-爬取图片并进行下载到本地的更多相关文章
- python网络爬虫&&爬取图片
爬取学院官网数据from urllib.request import * #导入所有request urllib文件夹,request只是里面的一个模块from lxml import etree # ...
- Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片
Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片 其实没太大用,就是方便一些,因为现在各个平台之间的图片都不能共享,比如说在 CSDN 不能用简书的图片, ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 使用Scrapy爬取图片入库,并保存在本地
使用Scrapy爬取图片入库,并保存在本地 上 篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy 目标: 爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地 好了不多说,让我们实 ...
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- Python 爬虫 爬取图片入门
爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 用户看到的网页实质是由 HTML 代码构成的,爬 ...
- 一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
[一.项目背景] 相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态. 今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来 ...
- Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
随机推荐
- Ionic -v1初始项目结构
界面
- 表格类型数据,Excel csv导入,导出操作
import pandas # 创建表格格式# ad = pandas.DataFrame({"a": range(1, 10), "b": range(10, ...
- 按字节读取txt文件缓存区大小设置多少比较好?
读取 txt 文件常规写法有逐行读取和按照字节缓存读取,那么按照字节缓存读取时,设置缓存区多大比较好呢?百度了一下,没发现有说这个问题的,自测了一把,以事实说话. 常规读取方法如下: // 字节流读取 ...
- Linux性能优化从入门到实战:17 网络篇:网络基础
网络模型 为了解决网络互联中异构设备的兼容性问题,并解耦复杂的网络包处理流程,国际标准化组织制定了开放式系统互联通信参考模型(Open System Interconnection Reference ...
- 51nod 1554 欧姆诺姆和项链
有一天,欧姆诺姆发现了一串长度为n的宝石串,上面有五颜六色的宝石.他决定摘取前面若干个宝石来做成一个漂亮的项链. 他对漂亮的项链是这样定义的,现在有一条项链S,当S=A+B+A+B+A+...+A+B ...
- Python日志库logging总结
转自 https://cloud.tencent.com/developer/article/1354396 在部署项目时,不可能直接将所有的信息都输出到控制台中,我们可以将这些信息记录到日志文件中 ...
- MySQL数据库的自动备份与数据库被破坏后的恢复1
一.前言: 当数据库服务器建立好以后,我们首先要做的不是考虑要在这个支持数据库的服务器运行哪些受MySQL提携的程序,而是当数据库遭到破坏后,怎样安然恢复到最后一次正常的状态,使得数据的损失达到最小. ...
- Pyhton爬虫实战
Pyhton爬虫实战 零.致谢 感谢BOSS直聘相对权威的招聘信息,使本人有了这次比较有意思的研究之旅. 由于爬虫持续爬取 www.zhipin.com 网站,以致产生的服务器压力,本人深感歉意,并没 ...
- hdu 4717: The Moving Points 【三分】
题目链接 第一次写三分 三分的基本模板 int SanFen(int l,int r) //找凸点 { ) { //mid为中点,midmid为四等分点 ; ; if( f(mid) > f(m ...
- python学习笔记(十三)处理时间模块
import time time.sleep(2)#等待几秒 时间的三种表现方式: 1.格式化好的时间 2018-1-14 16:12 2.时间戳 是从unix元年到现在所有的秒数 3.时间元组 想时 ...