python 使用for循环简单爬取图片(1)
现在的网站大多做了反爬处理,找一个能爬的网站还真不容易。
下面开始一步步实现:
1.简单爬录目图片
import urllib.request
import re def gethtml(url):
page=urllib.request.urlopen(url)
html=page.read().decode('utf-8') return html def getimg(html): a=re.compile(r'src="(.+?\.jpg)"')
tp=a.findall(html)
x=0 for img in tp:
urllib.request.urlretrieve(img,'d:/tupian/%s.jpg' % x)
x+=1
url="http://www.meituba.com/yijing/28426.html" html=gethtml(url)
getimg(html)
2.爬图集
这里仅仅是爬取了录目上的图片,还没有涉及到for循环遍历,针对我们的目标,我们要尽可能仔细观察它的规律。
这里我们随便点进去一个图片集,如图:

打开后看到该图片集一共是6张,
分析一下它的url 和页面的源代码:
1,url分析
这里就不贴图片了,我直接说吧
第一张图片(也就是第一页)的url=“http://www.meituba.com/yijing/28426.html”
第二张图片的url=“http://www.meituba.com/yijing/28426_2.html”
。。。。。
第六页图片的url=“http://www.meituba.com/yijing/28426_6.html”
我们可以发现规律,这里直接改一下'_'后面的数字,这里就需要for循环了
2,源代码的规律:
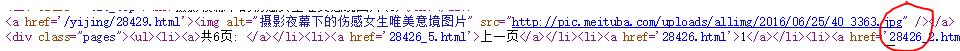
这里我们用正则表达式就应该稍作修改:
应该这样写:r'src="(.+?\.jpg)" /'
好了,下面就开始代码实现:
import urllib.request
import re def gethtml(url):
page=urllib.request.urlopen(url)
html=page.read().decode('utf-8') return html def getimg(html): a=re.compile(r'src="(.+?\.jpg)" /')
b=a.findall(html) for img in b:
urllib.request.urlretrieve(img,'d:/tupian/%s.jpg' % x) x=0 for i in range(1,7): if i==1:
url="http://www.meituba.com/yijing/28426.html"
else:
url=("http://www.meituba.com/yijing/28426_%s.html" % i) html=gethtml(url) x+=1 getimg(html)
1.这里有很多值得我们研究的问题比如第一页的url跟其他页的url有出入,所以我们应该想办法把第一页的图片也加进去,大家可以用if函数实现
看代码吧
2.关于urlretrieve()函数,在保存下载路径的时候要写出全路径,这里的
urllib.request.urlretrieve(img,'d:/tupian/%s.jpg' % x) 就应该做出变化了,我们可以理解一下,在第一个代码中,
我们将 x 这个函数直接定义在函数中,但那是在爬取一个网页下的所有图片,可我们的第二个代码是爬取每个页面下的一张图片,如果我们还是将 x 定义在函数中,那么就会出现一个问题,在文件夹中只会爬到一张图片
大家可以想想原因,
其实当我们用for循环遍历所有url时,getimg()函数是被一遍遍调用的,当第一个url下的图片被爬下来后,它的名称是 0.jpg 那么下一次下一个页面爬到的图片也将被命名为0.jpg
这样系统就只会默认的保存一张图片,所以我们在命名的时候应该注意这一点,
只需要将 x 的初始值定义在for循环的外面就可以了
参考:https://my.oschina.net/talentwang/blog/48524
3.一个图集的图片实在不能满足我们。
一般来说,我们可以通过观察页面url的规律来推出下一个url的地址,可我接下来观察了几个连续图集中的url的信息
28426
28429
28435
28438
28443
28445
28456
28461
本人数学不好,实在发现不了规律,其实在每个图集的下方都会给下一个图集的链接,这就给我们提供了思路,大家如果在爬取某个页面时遇到这种问题,不妨试一下
好了开始我们的代码实现了:下面仅仅是获取下个图集的url地址的代码,其余的下次补全:
import urllib.request
import re
from bs4 import BeautifulSoup def gethtml(url):
page=urllib.request.urlopen(url)
html=page.read().decode('utf-8')
soup=BeautifulSoup(html,'html.parser')
return soup def getimg(html): b=html.find_all("div",{"class":"descriptionBox"})
href=re.compile(r'<b>下一篇:</b><a href="(.+?\.html)">')
c=href.findall(str(b))
print(c)
print(type(c))
e="http://www.meituba.com"+('').join(c)
print(e)
d=urllib.request.urlopen(e)
f=d.read().decode('utf-8')
print(f)
url="http://www.meituba.com/yijing/28426.html"
soup=gethtml(url)
getimg(soup)
运行可以看到它已经可以成功的打印出下一个图集的html页面源代码。
之后再把所有代码总结一下,
今天就写到这,(明天继续)
python 使用for循环简单爬取图片(1)的更多相关文章
- 孤荷凌寒自学python第八十二天学习爬取图片2
孤荷凌寒自学python第八十二天学习爬取图片2 (完整学习过程屏幕记录视频地址在文末) 今天在昨天基本尝试成功的基础上,继续完善了文字和图片的同时爬取并存放在word文档中. 一.我准备爬取一个有文 ...
- 使用Scrapy爬虫框架简单爬取图片并保存本地(妹子图)
初学Scrapy,实现爬取网络图片并保存本地功能 一.先看最终效果 保存在F:\pics文件夹下 二.安装scrapy 1.python的安装就不说了,我用的python2.7,执行命令pip ins ...
- [python学习] 简单爬取图片站点图库中图片
近期老师让学习Python与维基百科相关的知识,无聊之中用Python简单做了个爬取"游讯网图库"中的图片,由于每次点击下一张感觉很浪费时间又繁琐.主要分享的是怎样爬取HTML的知 ...
- 简单的python爬虫教程:批量爬取图片
python编程语言,可以说是新型语言,也是这两年来发展比较快的一种语言,而且不管是少儿还是成年人都可以学习这个新型编程语言,今天南京小码王python培训机构变为大家分享了一个python爬虫教程. ...
- Python爬虫--简单爬取图片
今天晚上弄了一个简单的爬虫,可以爬取网页的图片,现在现在做一下准备工作. 需要的库:urllib 和 re urllib库可以理解为是一个url下载器,其中有三个重要的方法 urllib.urlope ...
- python网络爬虫之四简单爬取豆瓣图书项目
一.爬虫项目一: 豆瓣图书网站图书的爬取: import requests import re content = requests.get("https://book.douban.com ...
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- python如何使用request爬取图片
下面是代码的简单实现,变量名和方法都是跑起来就行,没有整理,有需要的可以自己整理下: image2local: import requests import time from lxml import ...
- python +requests 爬虫-爬取图片并进行下载到本地
因为写12306抢票脚本需要用到爬虫技术下载验证码并进行定位点击所以这章主要讲解,爬虫,从网页上爬取图片并进行下载到本地 爬虫实现方式: 1.首先选取你需要的抓取的URL:2.将这些URL放入待抓 ...
随机推荐
- Linux 下 SVN 命令操作详解
1.将文件checkout到本地目录 svn checkout path(path是服务器上的目录) 例如:svn checkout svn://192.168.1.1/pro/domain ...
- 23种设计模式之建造者模式(Builder)
建造者模式强调将一个复杂对象的创建与它的表示分离,使得同样的构建过程可以创建不同的表示.建造者模式是一步一步地创建一个复杂的对象,它允许用户只通过制定复杂对象的类型和内容就可以构建它们,用户不需要知道 ...
- 解决启动Distributed Transaction Coordinator服务出错的问题
解决启动Distributed Transaction Coordinator服务出错的问题 "Windows 不能在 本地计算机 启动 Distributed Transaction ...
- 解决远程登陆Linux误按ctrl+s锁屏
很多刚从windows转移到linux上来工作的朋友,在用vi/vim编辑文件时,常常会习惯性的按下Ctrl+s来保存文件内容.殊不知这样按下去后面会造成整个终端不响应了,ssh连接还好说,直接关 ...
- c++的矩阵乘法加速trick
最近读RNNLM的源代码,发现其实现矩阵乘法时使用了一个trick,这里描述一下这个trick. 首先是正常版的矩阵乘法(其实是矩阵乘向量) void matrixXvector(float* des ...
- iOS - Block的简单使用
Block 的使用有两种: .独立Block .内联Block <一>独立Block 使用方式 一.定义一个Block Object,并调用. 1.定义 // 定义一个Bl ...
- iOS8新特性(2)——UIPopoverController和UIPresentationController
一.以往使用 UIPopoverController 都是只在iPad上使用 /** * UIPopoverController 只能用于iPad,上,iPhone上使用会崩溃 */ -(void)o ...
- python--pytest库
pytest:是一个框架,使构建简单和可扩展的测试变得容易. 安装:pip install -U pytest 检查安装:pytest --version 官方文档:https://docs.pyte ...
- ELK之使用filebeat的多行过滤插件把多行合并成一行
java运行日志一般有多行,格式类似如下 格式为:日期 + 日志级别 + 日志信息 有些日志是多行的,需要使用filebeat多行插件把多行合并成一行 未使用多行插件的日志格式 修改filebeat配 ...
- SHU 414 - 字符串进制转换
题目链接:http://acmoj.shu.edu.cn/problem/414/ 很咸鱼的网上拉了个进制转换模板过来,因为数组开的太小一直WA,后来一气之下MAXN开到1e5,真是蓝瘦…… 后来实在 ...