机器学习入门-线性判别分析(LDA)1.LabelEncoder(进行标签的数字映射) 2.LinearDiscriminantAnalysis (sklearn的LDA模块)
1.from sklearn.processing import LabelEncoder 进行标签的代码编译
首先需要通过model.fit 进行预编译,然后使用transform进行实际编译
2.from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA 从sklearn的线性分析库中导入线性判别分析即LDA
用途:分类预处理中的降维,做分类任务
目的:LDA关心的是能够最大化类间区分度的坐标轴
将特征空间(数据中的多维样本,将投影到一个维度更小的K维空间,保持区别类型的信息)
监督性:LDA是“有监督”的,它计算的是另一个类特定的方向
投影:找到更适用的分类空间
与PCA不同: 更关心分类而不是方差(PCA更关心的是方差)

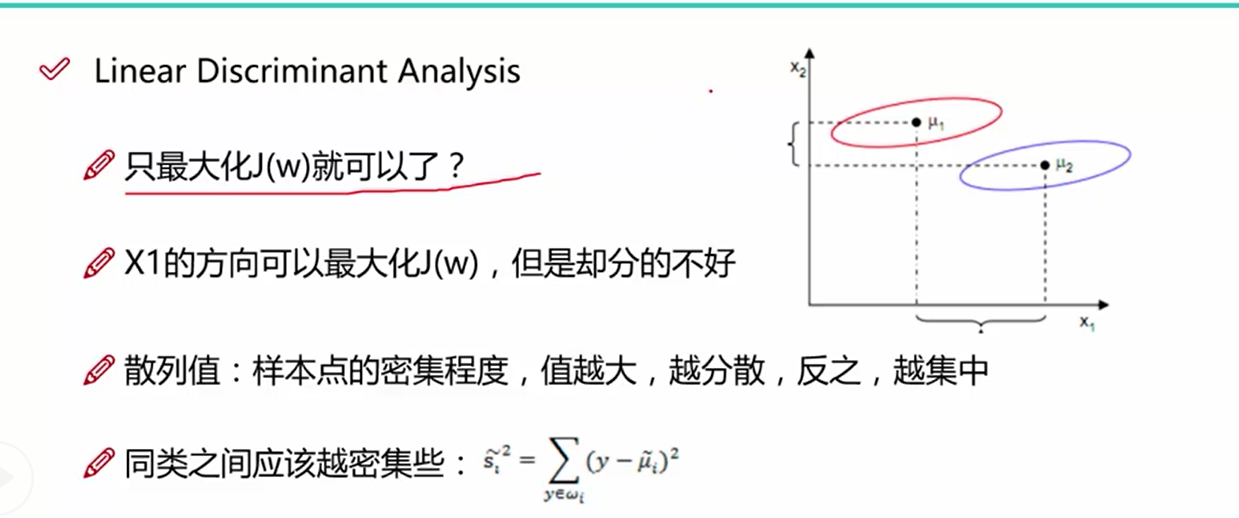
如图所示,找到合适的方向投影后的数据更加的分散
LDA的数据原理:
目标找到投影:y = w^T * x ,我们需要求解出w

LDA的第一个目标是使得投影后两个类别之间的距离越大越好,使用的判别依据,是投影后两个类别的中心点的距离越大越好,即均值u1^ - u2^
第一步:求出当前均值和投影后的均值
J(W) = |w^T(u1 - u2)| # 计算投影以后的两个类别中心位置之差

LDA的第二个目标是使得投影后的类别之间的距离越来越小,从图一中我们可以看出,只讨论类别之间的距离是不够的, 同类之间的距离使用单个类别的数据到类别中心之差来表示,值越大,同类数据越分散,值越小,同类数据越集中,我们需要使得这个值的大小越小越好
根据上面两个目标函数,我们做一个组合, 分子使用类间距离, 分母使用类内距离,求得组合后的最大值

该图表示的是最终的目标函数(类间距离/类内距离),这里的类内散布矩阵:通过同种类别数据-该类别的均值之差进行加和后求得
求得类间距离的散步矩阵

上述的目标矩阵就是我们求解的方程,我们需要求得其最大值
构造拉格朗日方程, 我们对分母进行缩放,使得w^TSw*w = 1, 作为限制条件
cw = w^T*SB*w - a(w^T*Sw*w-1) --构造的拉格朗日方程
cw/dw = w^T*SB*w - a(w^T*Sw*w-1) / dw 对上述方程使用dw进行求导,求偏导等于零求最大值
2SB*w - 2*a*Sw * w = 0
a * w = Sw^-1*SB*w ---- a*w = A*w
w是Sw^-1*SB的特征向量

代码:自己自行的编写
第一步:读取数据
第二步:提取样本变量和标签
第三步:对标签进行数字映射,使用LableEncoder
第四步:计算类内散列矩阵Sw sum((x-ui).dot((x-ui).T))
第五步:计算类间散列矩阵SB sum(n*(ui-u).dot(ui-u)) ui表示每一类样本的均值, u表示所有样本的均值
第六步:计算Sw^-1*SB的特征向量,即w,如果我们投影的维度是2,使用np.vstack, 将求得的特征向量的第一列和第二列数据进行拼接
第七步:将二维的w和X特征进行点乘操作, 获得变化后的二维特征
第八步:进行画图操作
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt # 第一步数据载入
data = pd.io.parsers.read_csv(filepath_or_buffer='https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',
header=None, names=['sepal length in cm', 'sepal width in cm','petal length in cm', 'petal width in cm', 'names'],
sep=',',)
data.dropna(how='all', inplace=True) # 第二步提取数据的X轴和y轴信息
feature_names = ['sepal length in cm', 'sepal width in cm','petal length in cm', 'petal width in cm']
X = data[feature_names].values
y = data['names'].values # 第三步 使用Label_encoding进行标签的数字转换
from sklearn.preprocessing import LabelEncoder model = LabelEncoder().fit(y)
y = model.transform(y) + 1 labels_type = np.unique(y) # 第四步 计算类内距离Sw
Sw = np.zeros([4, 4])
# 循环每一种类型
print(labels_type)
for i in range(1, 4):
xi = X[y==i]
ui = np.mean(xi, axis=0)
sw = ((xi - ui).T).dot(xi-ui)
Sw += sw
print(Sw) # 第五步:计算类间距离SB
SB = np.zeros([4, 4])
u = np.mean(X, axis=0).reshape(4, 1)
for i in range(1, 4):
n = X[y==i].shape[0]
u1 = np.mean(X[y==i], axis=0).reshape(4, 1)
sb = n * (u1 - u).dot((u1 - u).T)
SB += sb # 第六步:使用Sw^-1*SB特征向量计算w
vals, eigs = np.linalg.eig(np.linalg.inv(Sw).dot(SB)) # 第七步:取前两个特征向量作为w,与X进行相乘操作,相当于进行了2维度的降维操作
w = np.vstack([eigs[:, 0], eigs[:, 1]]).T transform_X = X.dot(w) # 第八步:定义画图函数
labels_dict = data['names'].unique()
def plot_lda(): ax = plt.subplot(111)
for label, m, c in zip(labels_type, ['*', '+', 'v'], ['red', 'black', 'green']):
plt.scatter(transform_X[y==label][:, 0], transform_X[y==label][:, 1], c=c, marker=m, alpha=0.6, s=100, label=labels_dict[label-1]) plt.xlabel('LD1')
plt.ylabel('LD2')
# 定义图例,loc表示的是图例的位置
leg = plt.legend(loc='upper right', fancybox=True)
# 设置图例的透明度为0.6
leg.get_frame().set_alpha(0.6)
#坐标轴上的一簇簇的竖点
plt.tick_params(axis='all', which='all', bottom='off', left='off', right='off', top='off',
labelbottom='on', labelleft='on')
# 表示的是坐标方向上的框线
ax.spines['top'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['right'].set_visible(False) plt.tight_layout()
plt.grid()
plt.show() plot_lda()

我们使用Sklearn自带的程序进行操作
第一步:读取数据
第二步:提取特征
第三步:对标签做数字映射,使用的是LabelEncoder
第四步:使用from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
第五步:结果进行画图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt # 第一步数据载入
data = pd.io.parsers.read_csv(filepath_or_buffer='https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',
header=None, names=['sepal length in cm', 'sepal width in cm','petal length in cm', 'petal width in cm', 'names'],
sep=',',)
data.dropna(how='all', inplace=True) # 第二步提取数据的X轴和y轴信息
feature_names = ['sepal length in cm', 'sepal width in cm','petal length in cm', 'petal width in cm']
X = data[feature_names].values
y = data['names'].values # 第三步 使用Label_encoding进行标签的数字转换
from sklearn.preprocessing import LabelEncoder model = LabelEncoder().fit(y)
y = model.transform(y) + 1 labels_type = np.unique(y) # 第四步 建立LDA模型
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA model = LDA(n_components=2)
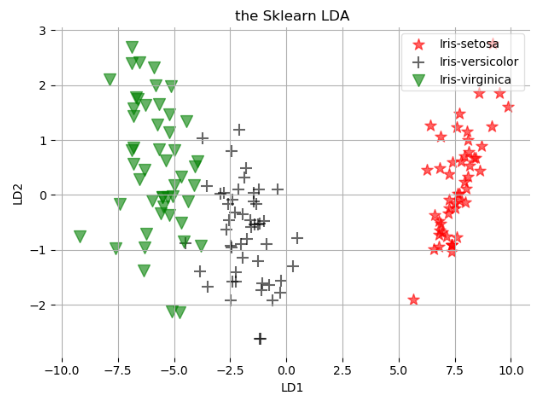
sklearn_x = model.fit_transform(X, y) # 第五步进行画图操作
def plot_lda_sklearn(X, title): ax = plt.subplot(111)
for label, m, c in zip(labels_type, ['*', '+', 'v'], ['red', 'black', 'green']):
plt.scatter(X[y==label][:, 0], X[y==label][:, 1], c=c, marker=m, alpha=0.6, s=100, label=labels_dict[label-1]) plt.title(title)
plt.xlabel('LD1')
plt.ylabel('LD2')
leg = plt.legend(loc='upper right', fancybox=True)
leg.get_frame().set_alpha(0.6) plt.tick_params(axis='all', which='all', bottom='off', left='off', right='off', top='off',
labelbottom='on', labelleft='on')
ax.spines['top'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['right'].set_visible(False) plt.tight_layout()
plt.grid()
plt.show() plot_lda_sklearn(sklearn_x, 'the Sklearn LDA')
机器学习入门-线性判别分析(LDA)1.LabelEncoder(进行标签的数字映射) 2.LinearDiscriminantAnalysis (sklearn的LDA模块)的更多相关文章
- TensorFlow.NET机器学习入门【5】采用神经网络实现手写数字识别(MNIST)
从这篇文章开始,终于要干点正儿八经的工作了,前面都是准备工作.这次我们要解决机器学习的经典问题,MNIST手写数字识别. 首先介绍一下数据集.请首先解压:TF_Net\Asset\mnist_png. ...
- 运用sklearn进行线性判别分析(LDA)代码实现
基于sklearn的线性判别分析(LDA)代码实现 一.前言及回顾 本文记录使用sklearn库实现有监督的数据降维技术——线性判别分析(LDA).在上一篇LDA线性判别分析原理及python应用(葡 ...
- 机器学习入门-文本特征-使用LDA主题模型构造标签 1.LatentDirichletAllocation(LDA用于构建主题模型) 2.LDA.components(输出各个词向量的权重值)
函数说明 1.LDA(n_topics, max_iters, random_state) 用于构建LDA主题模型,将文本分成不同的主题 参数说明:n_topics 表示分为多少个主题, max_i ...
- 机器学习入门-贝叶斯构造LDA主题模型,构造word2vec 1.gensim.corpora.Dictionary(构造映射字典) 2.dictionary.doc2vec(做映射) 3.gensim.model.ldamodel.LdaModel(构建主题模型)4lda.print_topics(打印主题).
1.dictionary = gensim.corpora.Dictionary(clean_content) 对输入的列表做一个数字映射字典, 2. corpus = [dictionary,do ...
- (数据科学学习手札17)线性判别分析的原理简介&Python与R实现
之前数篇博客我们比较了几种具有代表性的聚类算法,但现实工作中,最多的问题是分类与定性预测,即通过基于已标注类型的数据的各显著特征值,通过大量样本训练出的模型,来对新出现的样本进行分类,这也是机器学习中 ...
- TensorFlow.NET机器学习入门【0】前言与目录
曾经学习过一段时间ML.NET的知识,ML.NET是微软提供的一套机器学习框架,相对于其他的一些机器学习框架,ML.NET侧重于消费现有的网络模型,不太好自定义自己的网络模型,底层实现也做了高度封装. ...
- 机器学习中的数学-线性判别分析(LDA), 主成分分析(PCA)
转:http://www.cnblogs.com/LeftNotEasy/archive/2011/01/08/lda-and-pca-machine-learning.html 版权声明: 本文由L ...
- 机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
本文简单整理了以下内容: (一)维数灾难 (二)特征提取--线性方法 1. 主成分分析PCA 2. 独立成分分析ICA 3. 线性判别分析LDA (一)维数灾难(Curse of dimensiona ...
随机推荐
- FastAdmin 插件的 Git 开发流程(简明)
FastAdmin 插件的 Git 开发流程(简明) cms zip 安装 包安装 删除 addons 里的 cms 使用 mklink 软链接到 cms 插件 Git 仓库 修改 cms 插件 gi ...
- PHP 的工作流组件记录
我目前只知道在有审批流程中会用到工作流. 不过我我还没用过,还不知道怎么使用. 暂且先记录一下,目前我找到的几个 PHP 工作流组件. symfony https://github.com/symfo ...
- DevExpress GridControl控件行内新增、编辑、删除添加选择框(转)
http://blog.csdn.net/m1654399928/article/details/21951519 1.首先到GridControl控件设计里设置属性Repository (In ...
- 51nod 1965 奇怪的式子——min_25筛
题目:http://www.51nod.com/Challenge/Problem.html#!#problemId=1965 考虑 \( \prod_{i=1}^{n}\sigma_0^i \) \ ...
- POJ1050最大子矩阵面积
题目:http://poj.org/problem?id=1050 自己用了n^4的像暴搜一样的方法,感到有点奇怪——真的是这样? #include<iostream> #include& ...
- bzoj2464 小明的游戏
Description 小明最近喜欢玩一个游戏.给定一个n * m的棋盘,上面有两种格子#和@.游戏的规则很简单:给定一个起始位置和一个目标位置,小明每一步能向上,下,左,右四个方向移动一格.如果移动 ...
- yum安装软件时报错:Loaded plugins:fastestnirror,security Existing lock /var/run/yum.pid
在linux中使用yum时出现如下错误: Loaded plugins: fastestmirror, security Existing lock /var/run/yum.pid: another ...
- POJ 2139 Six Degrees of Cowvin Bacon (floyd)
Six Degrees of Cowvin Bacon Time Limit : 2000/1000ms (Java/Other) Memory Limit : 131072/65536K (Ja ...
- H-Index II @python
Follow up for H-Index: What if the citations array is sorted in ascending order? Could you optimize ...
- 联想Z510升级BCM94352HMB刷网卡白名单曲折经历
联想Z510笔记本:CPU I7 4702MQ没毛病 :内存4G DDR3不上虚拟机办公足够用: 硬盘升级为SSD240G足够用:有线网卡100M,真是垃圾,不过有线网卡是主板上的芯片,这个我可动不了 ...