Python爬虫学习笔记之微信宫格验证码的识别(存在问题)
本节我们将介绍新浪微博宫格验证码的识别。微博宫格验证码是一种新型交互式验证码,每个宫格之间会有一条
指示连线,指示了应该的滑动轨迹。我们要按照滑动轨迹依次从起始宫格滑动到终止宫格,才可以完成验证,如
下图所示。

鼠标滑动后的轨迹会以黄色的连线来标识,如下图所示。
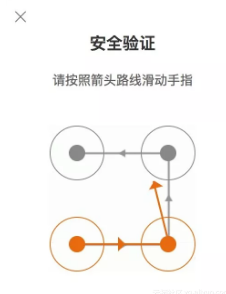
访问新浪微博移动版登录页面,就可以看到如上验证码,链接为 https://passport.weibo.cn/signin/login
一、本节目标
我们的目标是用程序来识别并通过微博宫格验证码的验证。
二、准备工作
本次我们使用的Python库是Selenium,使用的浏览器为Chrome,请确保已经正确安装好Selenium库、Chrome浏览器,并配置好ChromeDriver。
三、识别思路
识别从探寻规律入手。规律就是,此验证码的四个宫格一定是有连线经过的,每一条连线上都会相应的指示箭头,连线的形状多样,包括C型、Z型、X型等,如下图所示。
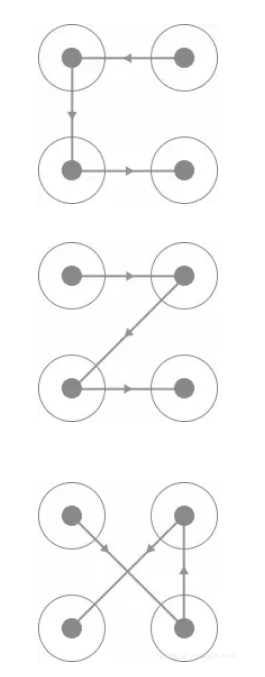
我们发现,同一类型的连线轨迹是相同的,唯一不同的就是连线的方向,如下图所示。这两种验证码的连线轨迹是相同的。但是由于连线上面的指示箭头不同,导致滑动的宫格顺序有所不同。
如果要完全识别滑动宫格顺序,就需要具体识别出箭头的朝向。而整个验证码箭头朝向一共有8种,而且会出现在不同的位置。如果要写一个箭头方向识别算法,需要考虑不同箭头所在的位置,找
出各个位置箭头的像素点坐标,计算像素点变化规律,这个工作量就会变得比较大。这时我们可以考虑用模板匹配的方法,就是将一些识别目标提前保存并做好标记,这称作模板。这里将验证码图
片做好拖动顺序的标记当做模板。对比要新识别的目标和每一个模板,如果找到匹配的模板,则就成功识别出要新识别的目标。在图像识别中,模板匹配也是常用的方法,实现简单且易用性好。
我们必须要收集到足够多的模板,模板匹配方法的效果才会好。而对于微博宫格验证码来说,宫格只有4个,验证码的样式最多4×3×2×1=24种,则我们可以将所有模板都收集下来。
接下来我们需要考虑的就是,用何种模板来进行匹配,只匹配箭头还是匹配整个验证码全图呢?我们权衡一下这两种方式的匹配精度和工作量。
 首先是精度问题。如果是匹配箭头,比对的目标只有几个像素点范围的箭头,我们需要精确知道各个箭头所在的像素点,一旦像素点有偏差,那么会直接错位,导致匹配结果大打折扣。如果
首先是精度问题。如果是匹配箭头,比对的目标只有几个像素点范围的箭头,我们需要精确知道各个箭头所在的像素点,一旦像素点有偏差,那么会直接错位,导致匹配结果大打折扣。如果
是匹配全图,我们无需关心箭头所在位置,同时还有连线帮助辅助匹配。显然,全图匹配的精度更高。其次是工作量的问题。如果是匹配箭头,我们需要保存所有不同朝向的箭头模板,而相同位置箭头的朝向可能不一,相同朝向的箭头位置可能不一,那么我们需要算出每个箭头的位置并将其
逐个截出保存成模板,依次探寻验证码对应位置是否有匹配模板。如果是匹配全图,我们不需要关心每个箭头的位置和朝向,只需要将验证码全图保存下来即可,在匹配的时候也不需要计算箭头的
位置。显然,匹配全图的工作量更少。
综上考虑,我们选用全图匹配的方式来进行识别。找到匹配的模板之后,我们就可以得到事先为模板定义的拖动顺序,然后模拟拖动即可。
获取模板:
import os
import time
from io import BytesIO
from PIL import Image
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from os import listdir USERNAME = ''
PASSWORD = '' TEMPLATES_FOLDER = 'templates/' class CrackWeiboSlide():
def __init__(self):
self.url = 'https://passport.weibo.cn/signin/login?entry=mweibo&r=https://m.weibo.cn/'
self.browser = webdriver.Chrome()
self.wait = WebDriverWait(self.browser, 20)
self.username = USERNAME
self.password = PASSWORD def __del__(self):
self.browser.close() def open(self):
"""
打开网页输入用户名密码登陆
:return: None
"""
self.browser.get(self.url)
username = self.wait.until(EC.presence_of_element_located((By.ID, 'loginName')))
password = self.wait.until(EC.presence_of_element_located((By.ID, 'loginPassword')))
submit = self.wait.until(EC.element_to_be_clickable((By.ID, 'loginAction')))
username.send_keys(self.username)
password.send_keys(self.password)
submit.click() def get_position(self):
"""
获取验证码位置
:return: 验证码位置元组
"""
try:
img = self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'patt-shadow')))
except TimeoutException:
print('未出现验证码')
self.opem()
time.sleep(2)
location = img.location
size = img.size
top, bottom, left, right = location['y'], location['y'] + size['height'], location['x'], location['x'] + size['width']
return (top, bottom, left, right) def get_screenshot(self):
"""
获取网页截图
:return: 截图对象
"""
screenshot = self.browser.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
return screenshot def get_image(self, name='captcha.png'):
"""
获取验证码图片
:return:图片对象
"""
top, bottom, left, right = self.get_position()
print('验证码位置', top, bottom, left, right)
screenshot = self.get_screenshot()
captcha = screenshot.crop((left, top, right, bottom))
captcha.save(name)
return captcha def main(self):
"""
批量获取验证码
:return: 图片对象
"""
count = 0
while True:
self.open()
self.get_image(str(count) + '.png')
count += 1 if __name__ == '__main__':
crack = CrackWeiboSlide()
crack.main()
这里需要将USERNAME和PASSWORD修改为自己微博的用户名和密码。运行一段时间后,本地多了很多以数字命名的验证码,如下图所示。
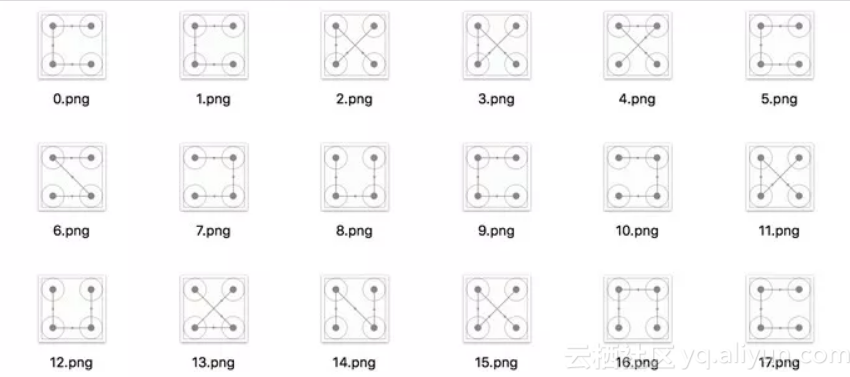
我们将图片命名为4132.png,代表滑动顺序为4-1-3-2。按照这样的规则,我们将验证码整理为如下24张图,如下图所示。
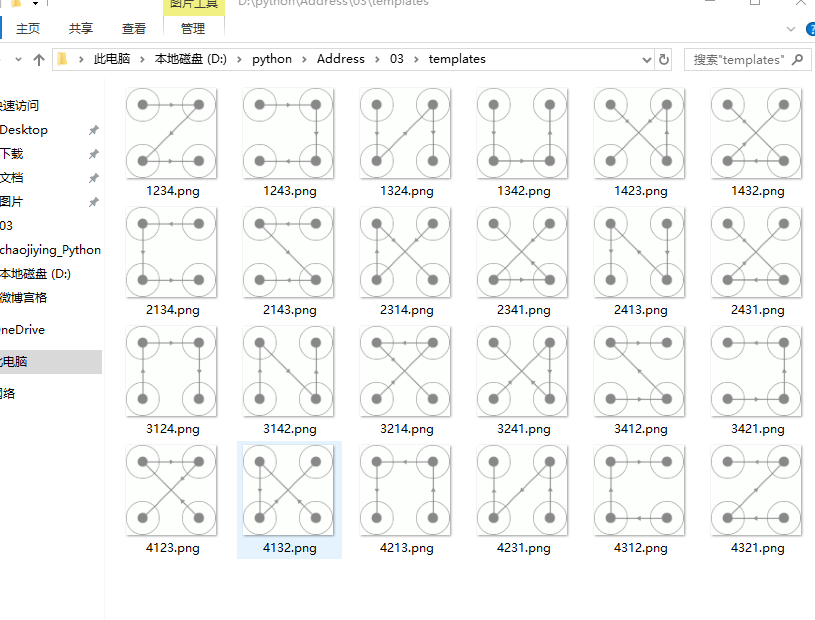
好了,获取模板就到此结束了,接下来该模板匹配了
方法解释:
(1)调用get_image()方法,得到验证码图片对象。然后,对验证码图片对象进行模板匹配
(2)TEMPLATES_FOLDER就是模板所在的文件夹。这里通过listdir()方法获取所有模板的文件名称,然后对其进行遍历,通过same_image()
方法对验证码和模板进行比对。如果匹配成功,那么就将匹配到的模板文件名转换为列表。如模板文件3124.png匹配到了,则返回结果
为[3, 1, 2, 4]。
(3)same_image()方法接收两个参数,image为待检测的验证码图片对象,template是模板对象。由于二者大小是完全一致的,所以在这里我
们遍历了图片的所有像素点。比对二者同一位置的像素点,如果像素点相同,计数就加1。最后计算相同的像素点占总像素的比例。如果
该比例超过一定阈值,那就判定图片完全相同,则匹配成功。这里阈值设定为0.99,即如果二者有0.99以上的相似比,则代表匹配成功。
(4)通过上面的方法,依次匹配24个模板。如果验证码图片正常,我们总能找到一个匹配的模板,这样就可以得到宫格的滑动顺序了。
(5)接下来,根据滑动顺序拖动鼠标,连接各个宫格
这里方法接收的参数就是宫格的点按顺序,如[3,1,2,4]。首先我们利用find_elements_by_css_selector()方法获取到4个宫格元素,它
是一个列表形式,每个元素代表一个宫格。接下来遍历宫格的点按顺序,做一系列对应操作。其中如果当前遍历的是第一个宫格,那就直
接鼠标点击并保持动作,否则移动到下一个宫格。如果当前遍历的是最后一个宫格,那就松开鼠标,如果不是最后一个宫格,则计算移动
到下一个宫格的偏移量。通过4次循环,我们便可以成功操作浏览器完成宫格验证码的拖拽填充,松开鼠标之后即可识别成功.
(6)鼠标会慢慢从起始位置移动到终止位置。最后一个宫格松开之后,验证码的识别便完成了。至此,微博宫格验证码的识别就全部完成。验
证码窗口会自动关闭。直接点击登录按钮即可登录微博。
方法代码(为什么验证不成功?请大家帮我看一下):
import os
import time
from io import BytesIO
from PIL import Image
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from os import listdir USERNAME = ''
PASSWORD = '' TEMPLATES_FOLDER = 'templates/' class CrackWeiboSlide():
def __init__(self):
self.url = 'https://passport.weibo.cn/signin/login?entry=mweibo&r=https://m.weibo.cn/'
self.browser = webdriver.Chrome()
self.wait = WebDriverWait(self.browser, 20)
self.username = USERNAME
self.password = PASSWORD def __del__(self):
self.browser.close() def open(self):
"""
打开网页输入用户名密码并点击
:return: None
"""
self.browser.get(self.url)
username = self.wait.until(EC.presence_of_element_located((By.ID, 'loginName')))
password = self.wait.until(EC.presence_of_element_located((By.ID, 'loginPassword')))
submit = self.wait.until(EC.element_to_be_clickable((By.ID, 'loginAction')))
username.send_keys(self.username)
password.send_keys(self.password)
submit.click() def get_position(self):
"""
获取验证码位置
:return: 验证码位置元组
"""
try:
img = self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'patt-shadow')))
except TimeoutException:
print('未出现验证码')
self.open()
time.sleep(2)
location = img.location
size = img.size
top, bottom, left, right = location['y'], location['y'] + size['height'], location['x'], location['x'] + size[
'width']
return (top, bottom, left, right) def get_screenshot(self):
"""
获取网页截图
:return: 截图对象
"""
screenshot = self.browser.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
return screenshot def get_image(self, name='captcha.png'):
"""
获取验证码图片
:return: 图片对象
"""
top, bottom, left, right = self.get_position()
print('验证码位置', top, bottom, left, right)
screenshot = self.get_screenshot()
captcha = screenshot.crop((left, top, right, bottom))
captcha.save(name)
return captcha def is_pixel_equal(self, image1, image2, x, y):
"""
判断两个像素是否相同
:param image1: 图片1
:param image2: 图片2
:param x: 位置x
:param y: 位置y
:return: 像素是否相同
"""
# 取两个图片的像素点
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
threshold = 20
if abs(pixel1[0] - pixel2[0]) < threshold and abs(pixel1[1] - pixel2[1]) < threshold and abs(
pixel1[2] - pixel2[2]) < threshold:
return True
else:
return False def same_image(self, image, template):
"""
识别相似验证码
:param image: 待识别验证码
:param template: 模板
:return:
"""
# 相似度阈值
threshold = 0.99
count = 0
for x in range(image.width):
for y in range(image.height):
# 判断像素是否相同
if self.is_pixel_equal(image, template, x, y):
count += 1
result = float(count) / (image.width * image.height)
if result > threshold:
print('成功匹配')
return True
return False def detect_image(self, image):
"""
匹配图片
:param image: 图片
:return: 拖动顺序
"""
for template_name in listdir(TEMPLATES_FOLDER):
print('正在匹配', template_name)
template = Image.open(TEMPLATES_FOLDER + template_name)
if self.same_image(image, template):
# 返回顺序
numbers = [int(number) for number in list(template_name.split('.')[0])]
print('拖动顺序', numbers)
return numbers def move(self, numbers):
"""
根据顺序拖动
:param numbers:
:return:
"""
# 获得四个按点
circles = self.browser.find_elements_by_css_selector('.patt-wrap .patt-circ')
dx = dy = 0
for index in range(4):
circle = circles[numbers[index] - 1]
# 如果是第一次循环
if index == 0:
# 点击第一个按点
ActionChains(self.browser).move_to_element_with_offset(circle, circle.size['width'] / 2, circle.size['height'] / 2).click_and_hold().perform()
else:
# 小幅移动次数
times = 30
# 拖动
for i in range(times):
ActionChains(self.browser).move_by_offset(dx / times, dy / times).perform()
time.sleep(1 / times)
# 如果是最后一次循环
if index == 3:
# 松开鼠标
ActionChains(self.browser).release().perform()
else:
# 计算下一次偏移
dx = circles[numbers[index + 1] - 1].location['x'] - circle.location['x']
dy = circles[numbers[index + 1] - 1].location['y'] - circle.location['y'] def crack(self):
"""
破解入口
:return:
"""
self.open()
# 获取验证码图片
image = self.get_image('captcha.png')
numbers = self.detect_image(image)
self.move(numbers)
time.sleep(10)
print('识别结束') if __name__ == '__main__':
crack = CrackWeiboSlide()
crack.crack()
错误提示:

最后,本节代码来自:https://github.com/Python3WebSpider/CrackWeiboSlide
Python爬虫学习笔记之微信宫格验证码的识别(存在问题)的更多相关文章
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- Python爬虫学习笔记(三)
Cookies: 以抓取https://www.yaozh.com/为例 Test1(不使用cookies): 代码: import urllib.request # 1.添加URL url = &q ...
- python爬虫学习笔记
爬虫的分类 1.通用爬虫:通用爬虫是搜索引擎(Baidu.Google.Yahoo等)“抓取系统”的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 简单来讲就是尽可 ...
- Python、pip和scrapy的安装——Python爬虫学习笔记1
Python作为爬虫语言非常受欢迎,近期项目需要,很是学习了一番Python,在此记录学习过程:首先因为是初学,而且当时要求很快速的出demo,所以首先想到的是框架,一番查找选用了Python界大名鼎 ...
- 一入爬虫深似海,从此游戏是路人!总结我的python爬虫学习笔记!
前言 还记得是大学2年级的时候,偶然之间看到了学长在学习python:我就坐在旁边看他敲着代码,感觉很好奇.感觉很酷,从那之后,我就想和学长一样的厉害,就想让学长教我,请他吃了一周的饭,他答应了.从此 ...
- Python爬虫学习笔记——豆瓣登陆(一)
#-*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup import html5lib import re import ...
- Python爬虫学习笔记-1.Urllib库
urllib 是python内置的基本库,提供了一系列用于操作URL的功能,我们可以通过它来做一个简单的爬虫. 0X01 基本使用 简单的爬取一个页面: import urllib2 request ...
- 【Python爬虫学习笔记(3)】Beautiful Soup库相关知识点总结
1. Beautiful Soup简介 Beautiful Soup是将数据从HTML和XML文件中解析出来的一个python库,它能够提供一种符合习惯的方法去遍历搜索和修改解析树,这将大大减 ...
- 【Python爬虫学习笔记(1)】urllib2库相关知识点总结
1. urllib2的opener和handler概念 1.1 Openers: 当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例).正常情况下,我们使 ...
随机推荐
- 【机器学习】多项式回归python实现
[机器学习]多项式回归原理介绍 [机器学习]多项式回归python实现 [机器学习]多项式回归sklearn实现 使用python实现多项式回归,没有使用sklearn等机器学习框架,目的是帮助理解算 ...
- Python3 小工具-UDP发现
from scapy.all import * import optparse import threading import os def scan(ip): pkt=IP(dst=ip)/UDP( ...
- HDU 4302 Holedox Eating (线段树模拟)
题意:一个老鼠在一条长度为L的直线上跑,吃蛋糕,老鼠只能沿直线移动.开始时没有蛋糕,老鼠的初始位置是0. 有两个操作,0 x 代表在位置x添加一个蛋糕: 1 代表老鼠想吃蛋糕.老鼠每次都会选择离自己最 ...
- nodejs基础学习
一:复制官网的代码,建立一个简单的服务器 const http = require('http'); const hostname = '127.0.0.1'; const port = 3000; ...
- Java容器之Iterator接口
Iterator 接口: 1. 所有实现了Collection接口的容器类都有一个iterator方法用以返回一个实现了Iterator接口的对象. 2. Iterator 对象称作迭代器,用以方便的 ...
- TCP系列19—重传—9、thin stream下的重传
一.介绍 当TCP连续大量的发送数据的时候,当出现丢包的时候可以有足够的dup ACK来触发快速重传.但是internet上还有大量的交互式服务,这类服务一般都是由小包组成,而且一次操作中需要传输的数 ...
- getGeneratedKeys自动获取主键的方法
public class Demo { public static void main(String[] args) { try { String sql="insert into pers ...
- python中元组与小括号的关系
在学习Python 的时候.说到有两种数据类型,一种叫 列表,一种叫做元组,可以认为,元组是功能精简的列表.因为它少了列表很多功能.但是又有相识.定义他们的时候,主要是用中括号和小括号之分. 例如:定 ...
- (转)linux sort,uniq,cut,wc命令详解
linux sort,uniq,cut,wc命令详解 sort sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出.如果 File 参数指定多个文件,那么 sort 命令将这些 ...
- 使用thymeleaf实现div中加载html
目标:固定顶部或者左侧导航,点击导航动态更新中间content区域的页面,也就是在放一个div在页面上,把html加载到div里,以前类似的实现都是通过Iframe或者js实现,在使用springbo ...