Python爬虫教程-16-破解js加密实例(有道在线翻译)
python爬虫教程-16-破解js加密实例(有道在线翻译)
- 在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如:
- 加cookie,身份验证UserAgent
- 图形验证,还有很难破解的滑动验证
- js签名验证,对传输数据进行加密处理
- 对于js加密
- 经过加密传输的就是密文,但是加密函数或者过程一定是在浏览器完成,
也就是一定会把js代码暴露给使用者 - 通过阅读加密算法,就可以模拟出加密过程,从而达到破解
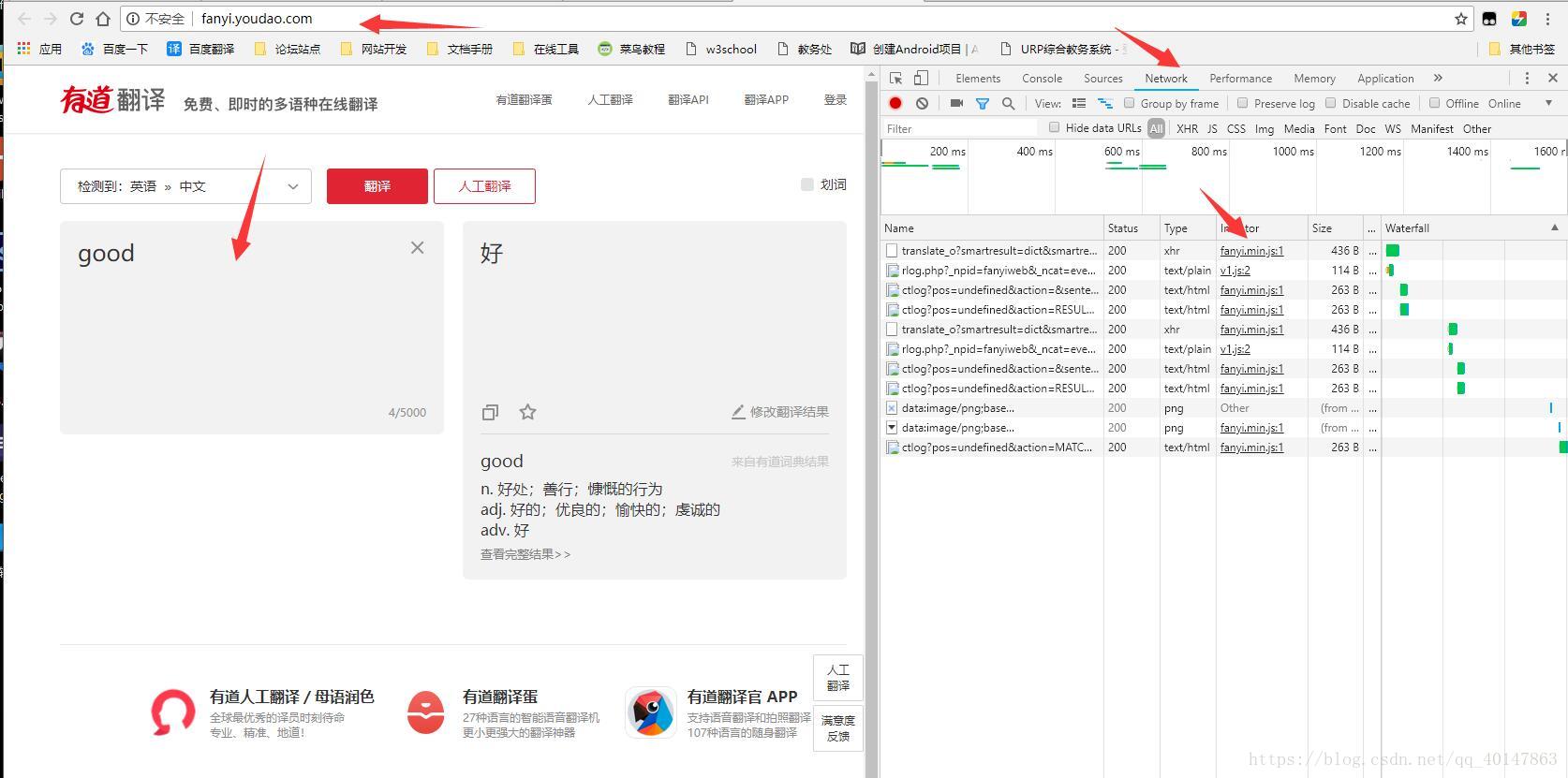
- 怎样判断网站有没有使用js加密,很简单,例如有道在线翻译
1.打开【有道在线翻译】网页:http://fanyi.youdao.com/
2.【右键检查】,选中【Network】
3.【输入单词】
4.在请求中,找到关于翻译内容的Form Data,可以看到有下面两项说明js加密
"salt": "1523100789519",
"sign": "b8a55a436686cd8973fa46514ccedbe",
- 经过加密传输的就是密文,但是加密函数或者过程一定是在浏览器完成,
分析js
- 一定要按照下面的顺序,不然的话会有很多无用的东西干扰
- 1.打开【有道在线翻译】网页:http://fanyi.youdao.com/
- 2.【右键检查】,选中【Network】
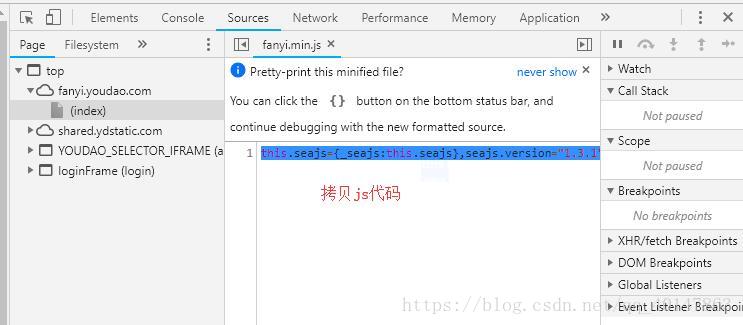
- 3.【输入单词】,【抓取js代码】
- 操作截图:
- 我们得到的js代码是一行代码,是压缩后的min代码,我们需要进行格式转换
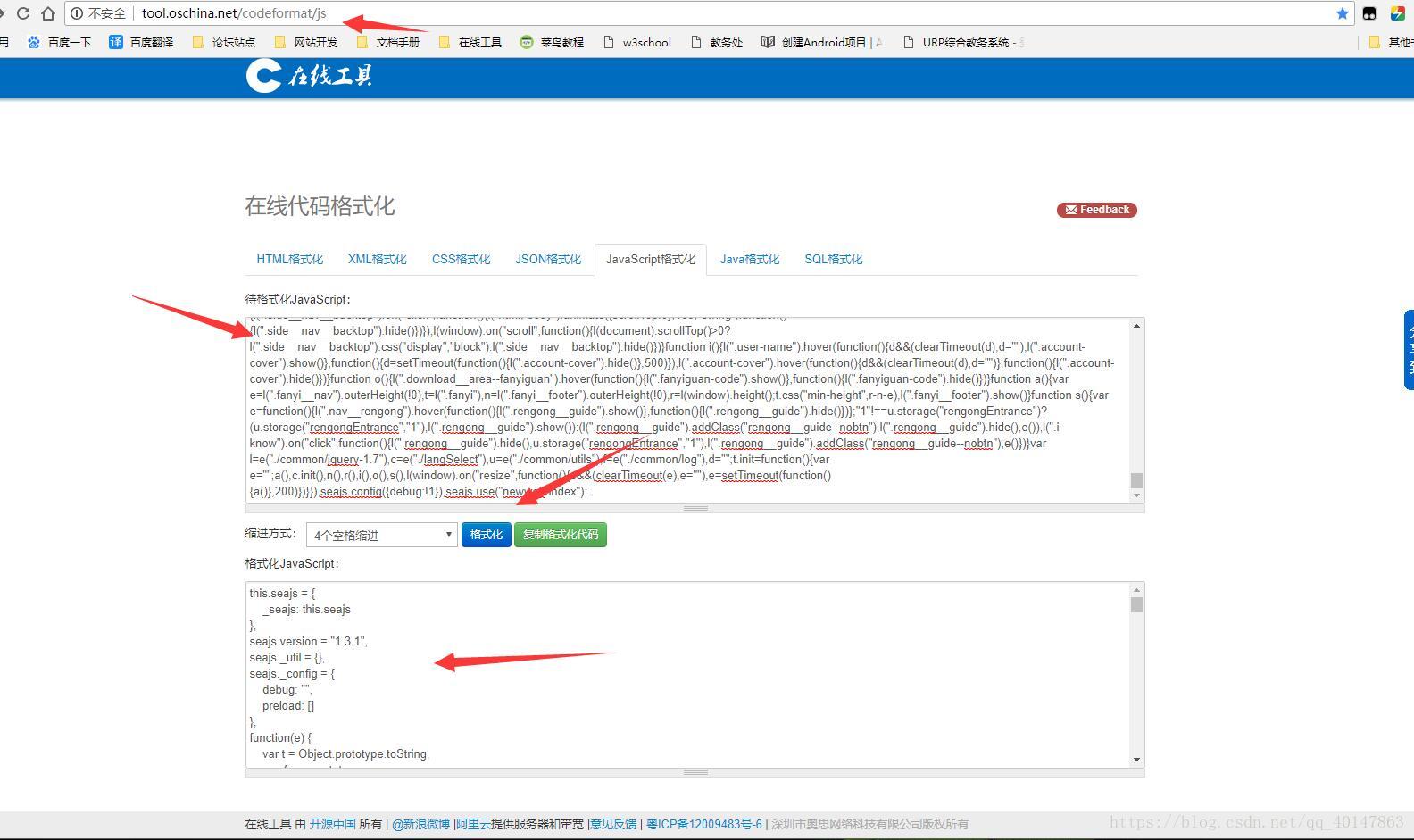
- 4.打开在线代码格式化网站:http://tool.oschina.net/codeformat/js
- 5.将拷贝的一行格式的js代码,粘贴在表单中,点击【格式化】
- 操作截图:
- 然后将格式化后的js代码,拷贝到一个可以搜索的代码编码器,备用
- 编写第2个版本
- 案例v18文件:https://xpwi.github.io/py/py爬虫/py18js2.py
# 破解js加密,版本2
'''
通过在js文件中查找salt或者sign,可以找到
1.可以找到这个计算salt的公式
r = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10))
2.sign:n.md5("fanyideskweb" + t + r + "ebSeFb%=XZ%T[KZ)c(sy!");
md5 一共需要四个参数,第一个和第四个都是固定值得字符串,第三个是所谓的salt,
第二个参数是输入的需要翻译的单词
'''
from urllib import request, parse
def getSalt():
'''
salt的公式r = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10))
把它翻译成python代码
'''
import time, random
salt = int(time.time()*1000) + random.randint(0, 10)
return salt
def getMD5(v):
import hashlib
md5 = hashlib.md5()
md5.update(v.encode('utf-8'))
sign = md5.hexdigest()
return sign
def getSign(key, salt):
sign = "fanyideskweb" + key + str(salt) + "ebSeFb%=XZ%T[KZ)c(sy!"
sign = getMD5(sign)
return sign
def youdao(key):
# url从http://fanyi.youdao.com输入词汇右键检查得到
url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=true"
salt = getSalt()
# data从右键检查FormData得到
data = {
"i": key,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": str(salt),
"sign": getSign(key, salt),
"doctype": "json",
"version": "2.1",
"keyform": "fanyi.web",
"action": "FY_BY_REALTIME",
"typoResult": "false"
}
print(data)
# 对data进行编码,因为参数data需要bytes格式
data = parse.urlencode(data).encode()
# headers从右键检查Request Headers得到
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": len(data),
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "OUTFOX_SEARCH_USER_ID=685021846@10.168.8.76; OUTFOX_SEARCH_USER_ID_NCOO=366356259.5731474; _ntes_nnid=1f61e8bddac5e72660c6d06445559ffb,1535033370622; JSESSIONID=aaaVeQTI9KXfqfVBNsXvw; ___rl__test__cookies=1535204044230",
"Host": "fanyi.youdao.com",
"Origin": "http://fanyi.youdao.com",
"Referer": "http://fanyi.youdao.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
}
req = request.Request(url=url, data=data, headers=headers)
rsp = request.urlopen(req)
html = rsp.read().decode()
print(html)
if __name__ == '__main__':
youdao("girl")
运行结果
返回翻译后的值,才算是成功
注意
按照步骤,熟悉流程最重要
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-16-破解js加密实例(有道在线翻译)的更多相关文章
- python爬虫_从零开始破解js加密(一)
除了一些类似字体反爬之类的奇淫技巧,js加密应该是反爬相当常见的一部分了,这也是一个分水岭,我能解决基本js加密的才能算入阶. 最近正好遇到一个比较简单的js,跟大家分享一下迅雷网盘搜索_838888 ...
- Python破解js加密实例(有道在线翻译)
在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如: 加cookie,身份验证UserAgent 图形验证,还有很难破解的滑动验证 js签名验证,对传输数据进行加密处理 对于js加密经过加密传输的就是 ...
- Python爬虫教程(16行代码爬百度)
最近在学习python,不过有一个正则表达式一直搞不懂,自己直接使用最笨的方法写出了一个百度爬虫,只有短短16行代码.首先安装必背包: pip3 install bs4 pip3 install re ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫—破解JS加密的Cookie
前言 在GitHub上维护了一个代理池的项目,代理来源是抓取一些免费的代理发布网站.上午有个小哥告诉我说有个代理抓取接口不能用了,返回状态521.抱着帮人解决问题的心态去跑了一遍代码.发现果真是这样. ...
- python爬虫之快速对js内容进行破解
python爬虫之快速对js内容进行破解 今天介绍下数据被js加密后的破解方法.距离上次发文已经过去半个多月了,我写文章的主要目的是把从其它地方学到的东西做个记录顺便分享给大家,我承认自己是个懒猪.不 ...
- 爬虫破解js加密(一) 有道词典js加密参数 sign破解
在爬虫过程中,经常给服务器造成压力(比如耗尽CPU,内存,带宽等),为了减少不必要的访问(比如爬虫),网页开发者就发明了反爬虫技术. 常见的反爬虫技术有封ip,user_agent,字体库,js加密, ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
随机推荐
- [转] watch 命令使用(linux监控状态)
[From] https://jingyan.baidu.com/article/495ba841c5a31738b30eded4.html 可以使用watch 命令设置执行间隔,去反复间隔一条命令或 ...
- pycharm入门的简易使用教程
1.安装python3.5包: 本人安装到C盘,如下所示: Ps:安装时候,路径一定要添加到环境变量中,安装完,需要更新环境变量,所以要重启电脑 2.安装pycharm 下载相应的安装包,步骤不重复了 ...
- 九度oj 1468 Sharing 2012年浙江大学计算机及软件工程研究生机试真题
题目1468:Sharing 时间限制:1 秒 内存限制:128 兆 特殊判题:否 提交:2687 解决:550 题目描述: To store English words, one method is ...
- solr linux配置
一.先在官网下载solr的最新版本或者你需求的版本1 目前我使用的是4.10.3(http://archive.apache.org/dist/lucene/solr/4.10.3/)2 复制到你的云 ...
- vue加载Element ui地址省市区插件-- element-china-area-data
1.安装 npm install element-china-area-data -S 2.使用(引入) import { provinceAndCityData, regionData, provi ...
- C#语言-06.XML
a. XML:称为可扩展标记性语言,它主要用于描述数据 i. 特点: . XML 中用于描述数据的各个节点可以自由扩展 . XML 文件中的节点区分大小写 . XML 中的每对标记通常被称为节点,它们 ...
- IIS调试技术之 Debug Diagnostic (调试诊断)
IIS 调试技术之 Debug Diagnostic (调试诊断) 1 概述 1.1 文档简介 系统出现错误或崩溃,免不了要进行调试.调试能进行的前提是错误能重现,但实际上要重现一个错误有 ...
- ActiveMQ整合spring结合项目开发流程(生产者和消费者)总结
一:生产者代码编写: 1.配置pom.xml引入相关坐标 <dependencies> <!-- spring开发测试 --> <dependency> <g ...
- ajax上传数据
---恢复内容开始--- ajax上传数据,(简洁版) 1.上传普通同表单标签内容. 1.获取表单的内容 1. var file=$('#file').val();(放在点击事件后面) 2. var ...
- thrift简介
thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发.它结合了功能强大的软件堆栈和代码生成引擎,以构建在 C++, Java, Python, PHP, Ruby, Erlang, Perl ...