jieba结巴分词
pip install jieba
安装jieba模块 如果网速比较慢,
可以使用豆瓣的Python源:
pip install -i https://pypi.douban.com/simple/ jieba 一、分词:
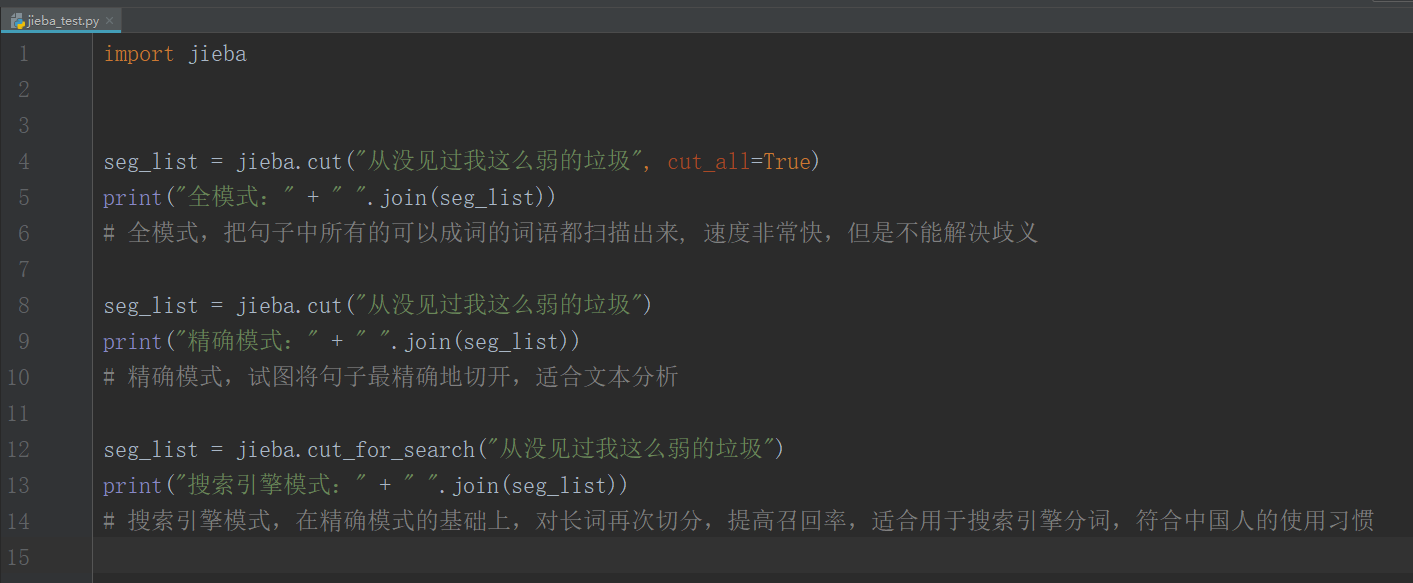
import jieba
seg_list = jieba.cut("从没见过我这么弱的垃圾", cut_all=True)
print("全模式:" + " ".join(seg_list))
# 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
seg_list = jieba.cut("从没见过我这么弱的垃圾")
print("精确模式:" + " ".join(seg_list))
# 精确模式,试图将句子最精确地切开,适合文本分析
seg_list = jieba.cut_for_search("从没见过我这么弱的垃圾")
print("搜索引擎模式:" + " ".join(seg_list))
# 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词,符合中国人的使用习惯
打印结果:
全模式:从没 没见 过 我 这么 弱 的 垃圾
精确模式:从没 见 过 我 这么 弱 的 垃圾
搜索引擎模式:从没 见 过 我 这么 弱 的 垃圾
也可以这样写:
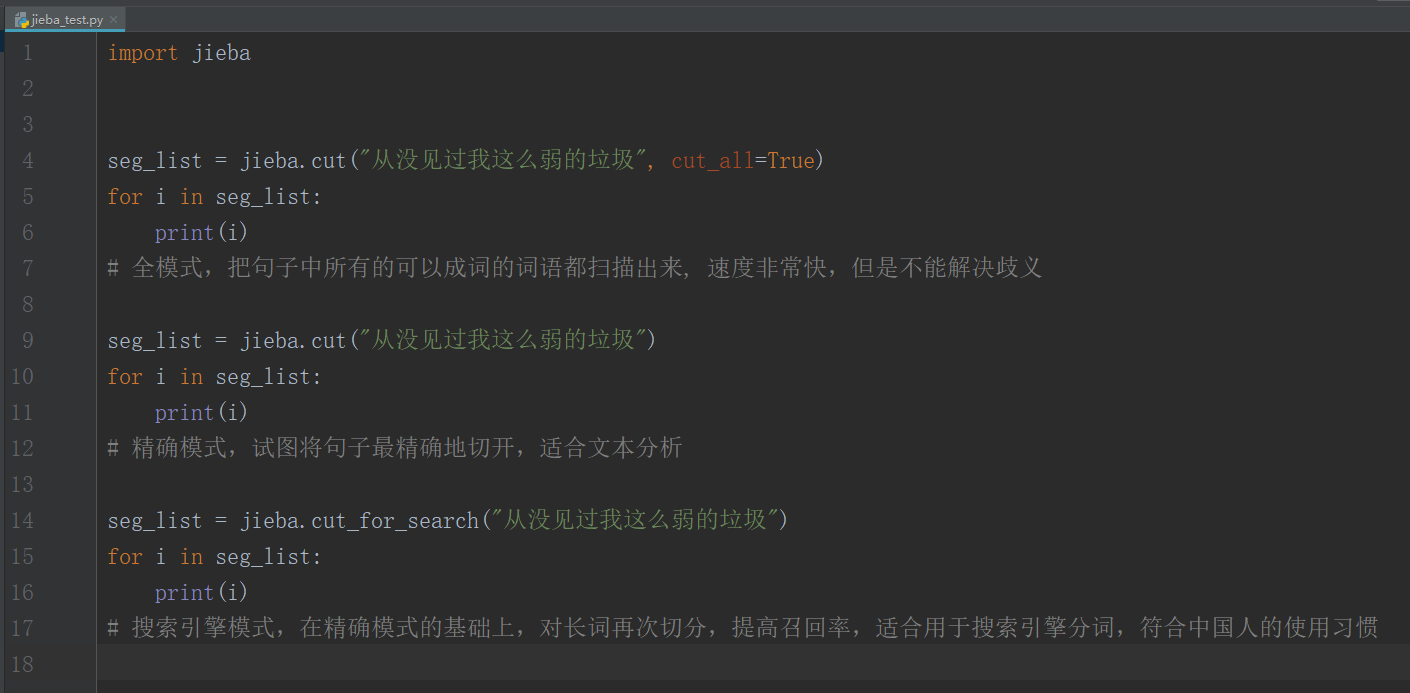
import jieba
seg_list = jieba.cut("从没见过我这么弱的垃圾", cut_all=True)
for i in seg_list:
print(i)
# 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
seg_list = jieba.cut("从没见过我这么弱的垃圾")
for i in seg_list:
print(i)
# 精确模式,试图将句子最精确地切开,适合文本分析
seg_list = jieba.cut_for_search("从没见过我这么弱的垃圾")
for i in seg_list:
print(i)
# 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词,符合中国人的使用习惯
打印结果:
从没
没见
过
我
这么
弱
的
垃圾
从没
见
过
我
这么
弱
的
垃圾
从没
见
过
我
这么
弱
的
垃圾
jieba.cut 方法接受三个输入参数:
1、需要分词的字符串;
2、cut_all 参数用来控制模式,
cut_all=True or False,
默认为False(精确模式);
3、HMM 参数用来控制是否使用HMM模型,
HMM=True or False,
默认为True(新词识别)。
jieba.cut_for_search 方法接受两个参数:
1、需要分词的字符串;
2、是否使用 HMM 模型。
该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的generator,
可以使用 for 循环来获得分词后得到的每一个词语(unicode),
或者用
jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
二、添加自定义的词典:
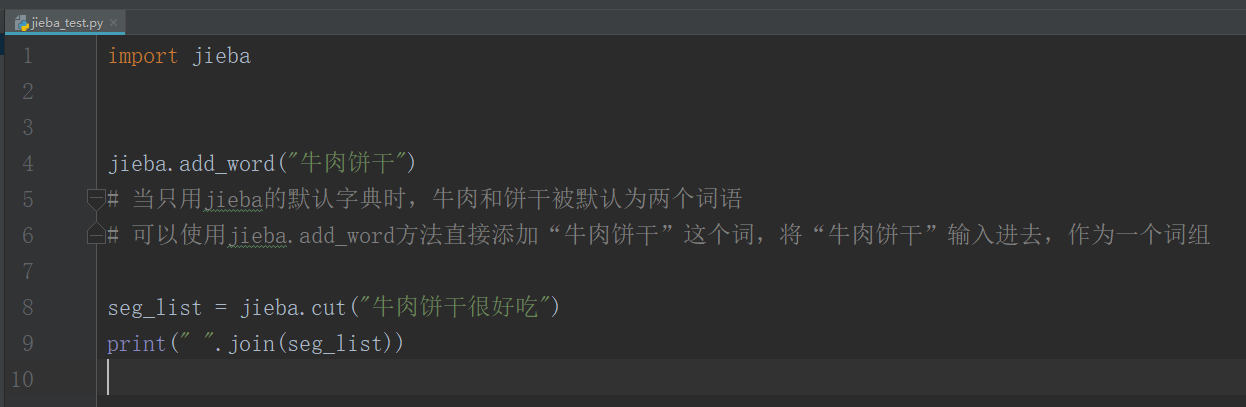
import jieba
jieba.add_word("牛肉饼干")
# 当只用jieba的默认字典时,牛肉和饼干被默认为两个词语
# 可以使用jieba.add_word方法直接添加“牛肉饼干”这个词,将“牛肉饼干”输入进去,作为一个词组
seg_list = jieba.cut("牛肉饼干很好吃")
print(" ".join(seg_list))
打印结果:
牛肉饼干 很 好吃
还可以这样写:
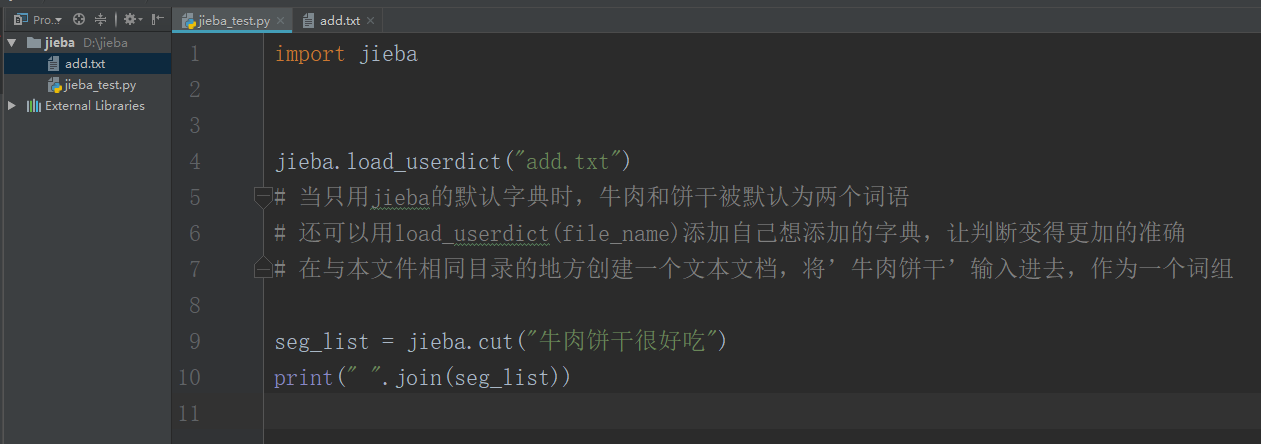
import jieba
jieba.load_userdict("add.txt")
# 当只用jieba的默认字典时,牛肉和饼干被默认为两个词语
# 还可以用load_userdict(file_name)添加自己想添加的字典,让判断变得更加的准确
# 在与本文件相同目录的地方创建一个文本文档,将’牛肉饼干’输入进去,作为一个词组
seg_list = jieba.cut("牛肉饼干很好吃")
print(" ".join(seg_list))
打印结果:
牛肉饼干 很 好吃
三、调整词典:
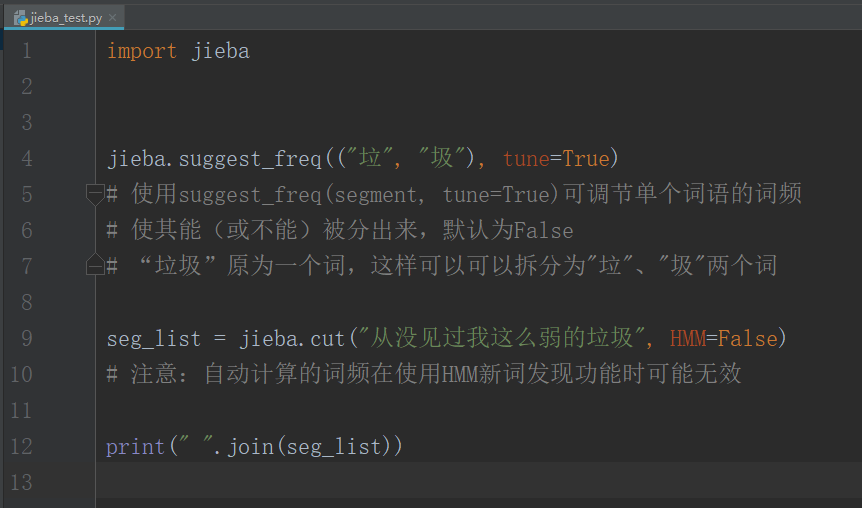
import jieba
jieba.suggest_freq(("垃", "圾"), tune=True)
# 使用suggest_freq(segment, tune=True)可调节单个词语的词频
# 使其能(或不能)被分出来,默认为False
# “垃圾”原为一个词,这样可以可以拆分为"垃"、"圾"两个词
seg_list = jieba.cut("从没见过我这么弱的垃圾", HMM=False)
# 注意:自动计算的词频在使用HMM新词发现功能时可能无效
print(" ".join(seg_list))
打印结果:
从没 见 过 我 这么 弱 的 垃 圾 补充:
1、文件名不可命令为jieba.py
否则会报错:
AttributeError: module 'jieba' has no attribute 'cut' 2、join()方法:
连接字符串数组,
将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
jieba结巴分词的更多相关文章
- Python3.7+jieba(结巴分词)配合Wordcloud2.js来构造网站标签云(关键词集合)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_138 其实很早以前就想搞一套完备的标签云架构了,迫于没有时间(其实就是懒),一直就没有弄出来完整的代码,说到底标签对于网站来说还是 ...
- solr+jieba结巴分词
为什么选择结巴分词 分词效率高 词料库构建时使用的是jieba (python) 结巴分词Java版本 下载 git clone https://github.com/huaban/jieba-ana ...
- python调用jieba(结巴)分词 加入自定义词典和去停用词功能
把语料从数据库提取出来以后就要进行分词啦,我是在linux环境下做的,先把jieba安装好,然后找到内容是build jieba PKG-INFO setup.py test的那个文件夹(我这边是ji ...
- 结巴(jieba)分词
一.介绍: jieba: “结巴”中文分词:做最好的 Python 中文分词组件 “Jieba” (Chinese for “to stutter”) Chinese text segmentatio ...
- python 结巴分词(jieba)详解
文章转载:http://blog.csdn.net/xiaoxiangzi222/article/details/53483931 jieba “结巴”中文分词:做最好的 Python 中文分词组件 ...
- jieba GitHUb 结巴分词
1.GitHub jieba-analysis 结巴分词: https://github.com/fxsjy/jieba 2.jieba-analysis 结巴分词(java版): https://g ...
- python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库 -转载
转载请注明出处 “结巴”中文分词:做最好的 Python 中文分词组件,分词模块jieba,它是python比较好用的分词模块, 支持中文简体,繁体分词,还支持自定义词库. jieba的分词,提取关 ...
- 结巴分词 java 高性能实现,是 huaban jieba 速度的 2倍
Segment Segment 是基于结巴分词词库实现的更加灵活,高性能的 java 分词实现. 变更日志 创作目的 分词是做 NLP 相关工作,非常基础的一项功能. jieba-analysis 作 ...
- 模块 jieba结巴分词库 中文分词
jieba结巴分词库 jieba(结巴)是一个强大的分词库,完美支持中文分词,本文对其基本用法做一个简要总结. 安装jieba pip install jieba 简单用法 结巴分词分为三种模式:精确 ...
随机推荐
- LSOF 安装与使用(功能强大)
Linux上安装: tar zxvf lsof_4.76.tar.gz cd lsof_4.76 ls 00.README.FIRST_4.76 lsof_4.76_src.tar.gz ...
- Jewels and Stones
题目如下 You're given strings J representing the types of stones that are jewels, and S representing the ...
- #leetcode刷题之路35-搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引.如果目标值不存在于数组中,返回它将会被按顺序插入的位置.你可以假设数组中无重复元素. 示例 1:输入: [1,3,5,6], 5输出: ...
- 如何在tornado中以异步的方式调用同步函数
问题 如何在tornado的coroutine中调用同步阻塞的函数 解决方案 使用python内置标准库的concurrent.futures.ThreadPoolExecutor和tornado.c ...
- 常用的JavaScript设计模式(二)Factory(工厂)模式
Factory通过提供一个通用的接口来创建对象,同时,我们还可以指定我们想要创建的对象实例的类型. 假设现在有一个汽车工厂VehicleFactory,支持创建Car和Truck类型的对象实例,现在需 ...
- Julia 1.0 中文文档
欢迎来到Julia 1.0的文档. 请阅读发布博客文章,了解该语言的一般概述以及自Julia v0.6以来的许多更改.请注意,0.7版本与1.0一起发布,以提供1.0版本之前的软件包和代码的升级路径. ...
- Ubuntu Linux TinySerial串口调试助手 可视化界面 安装使用
ubuntu Linux下串口调试助手使用 Tiny Serial为一个开源项目,欢迎大家使用,基于Qt开发的串口调试助手,有一般串口助手的基本功能,更多功能正在完善. Github地址:https: ...
- Python学习:7.文件操作
文件操作 我们曾将听过一个问题,将大象放入冰箱分为三步:1.打开冰箱门,2.将大象放进去,3.关上冰箱门.今天我们要讲的Python文件操作的步骤就像将大象放入冰箱的步骤一样. 使用Python操作文 ...
- PHP变量问题,Bugku变量1
知识点:php正则表达式,php函数,全局变量GLOBALS(注意global和$GLOBALS[]的区别) PHP函数: isset(): 条件判断 get方法传递的args参数是否存在 p ...
- Java学习笔记二十七:Java中的抽象类
Java中的抽象类 一:Java抽象类: 在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就 ...