【Hadoop】Seondary NameNode不是备份NameNode!!
昨天和舍友聊天时无意中提起Secondary NameNode,他说这是备用NameNode。我当时就有点疑惑。。之后查阅了相关资料和博客,算是基本理解了什么是Secondary NameNode。
1. HDFS为什么要加入Secondary NameNode?
翻看《Hadoop权威指南》,书上明确写道NameNode存在单点损坏问题,Hadoop为了提高NameNode的容错,提供了以下两种机制:
- 备份组成文件系统元数据的文件
- 运行一个辅助NameNode
这里提到的辅助NameNode也就是我们要分析的Secondary NameNode
2. Secondary NameNode的真正作用
(1)首先,我们先了解以下NameNode的相关概念:HDFS集群中有两种节点,DataNode(工作节点)和NameNode(管理结点),NameNode主要功能如下:
- 管理文件系统的命名空间(NameSpace);
- 维护文件系统树(FileSystem Tree)以及整棵树内所有的文件和目录(这些信息称为NameNode的MetaData)
- 记录每个文件中各个块所在的数据结点信息(不永久保存,启动时重建)
(2)NameNode的 MetaData 以两种形式永久保存在本地磁盘上:
- 命名空间镜像文件(fsimage):保存HDFS的最新状态(截止到 fsimage 文件创建时的最新状态)
- 编辑日志文件(edits):自fsimage创建后NameSpace的操作日志
(3)当NameNode 启动时,需要合并fsimage和edits文件,按照edits文件内容将fsimage进行更行,从而得到HDFS的最新状态。实际应用中,NameNode很少重新启动。假如存在一个庞大的集群,且关于HDFS的操作相当频繁与复杂,那么就会产生一个非常大的edits文件用于记录操作,这就带来了以下问题:
- edits文件过大会带来管理问题;
- 一旦需要重启HDFS时,就需要花费很长一段时间对edits和fsimage进行合并,这就导致HDFS长时间内无法启动;
- 如果NameNode挂掉了,会丢失部分操作记录(这部分记录存储在内存中,还未写入edits);
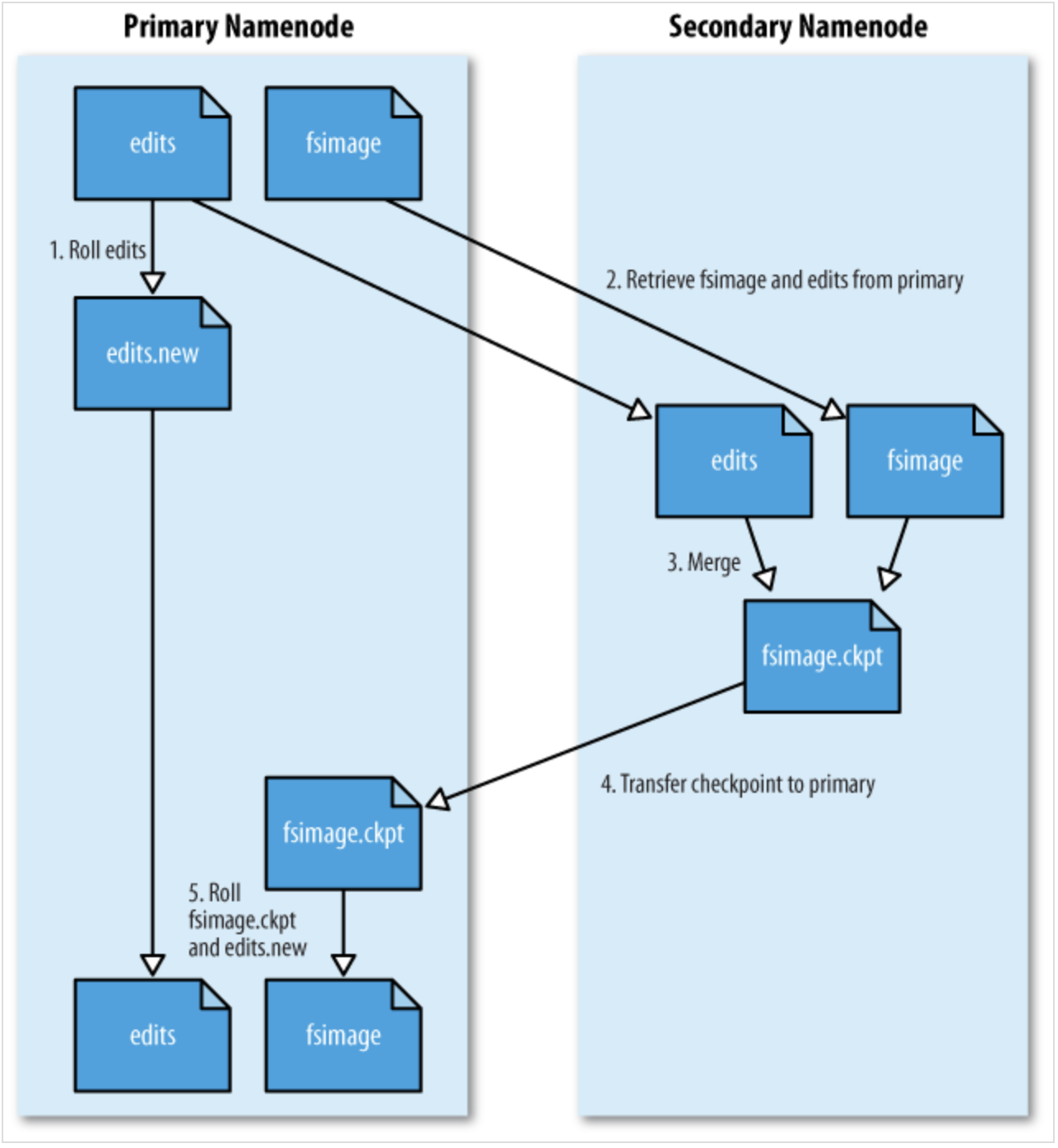
(4)此时,Secondary NameNode(SN)就要发挥它的作用了:合并edits文件,防止edits文件持续增长。具体步骤如下:
- SN向NameNode发送请求;
- NamoNode收到请求,暂停写入edits;
- log记录产生一个edits.new的文件;
- SN从NameNode获取元数据,然后对edits和fsimage进行合并(将edits内容更新到fsimage),产生一个新的fsimage,将其发送给NameNode;
- NameNode收到后,将之前的fsimage文件进行覆盖;
- NameNode删除之前的edits文件,将edits.new重命名为edits;
这样就可以避免edits文件的持续增长,也就解决上述几个问题。
3. Secondary NameNode何时读取元数据(checkpoint)
(1)达到最大时间间隔
参数 fs.checkpoint.period:规定两次checkpoint的最大时间间隔
(2)edits文件的最大尺寸
参数 fs.checkpoint.size:当NameNode上的edits文件超过该尺寸,无论是否达到最大时间间隔,都强制执行checkpoint
4. CheckNode的诞生
由于Secondary NameNode总是让人“望文生义”,带来理解上的偏差,Hadoop 1.0.4之后推荐不再使用Secondary NameNod,而是其替代版CheckNode。二者功能、配置完全相同,只是执行命令有所不同
总结:
1. Secondary NameNode用于定期合并与编辑edits和fsimage文件,防止NameNode的edits文件增长过大;
2. Secondary nameNode一般运行在另一台物理机,因为其内存大小需求与NameNode一致;
3. Secondary NameNode更像是NameNode的辅助工具,而不是备用NameNode
【Hadoop】Seondary NameNode不是备份NameNode!!的更多相关文章
- Hadoop分布式集群部署(单namenode节点)
Hadoop分布式集群部署 系统系统环境: OS: CentOS 6.8 内存:2G CPU:1核 Software:jdk-8u151-linux-x64.rpm hadoop-2.7.4.tar. ...
- 高可用hadoop的hdfs启动的时候namenode启动不了
启动的时候,一直要求输入namenode密码: 查看namenode的日志如下: 2019-03-28 18:38:08,961 INFO org.apache.hadoop.ipc.Client: ...
- Hadoop源码学习笔记之NameNode启动场景流程一:源码环境搭建和项目模块及NameNode结构简单介绍
最近在跟着一个大佬学习Hadoop底层源码及架构等知识点,觉得有必要记录下来这个学习过程.想到了这个废弃已久的blog账号,决定重新开始更新. 主要分以下几步来进行源码学习: 一.搭建源码阅读环境二. ...
- 安装部署Apache Hadoop (完全分布式模式并且实现NameNode HA和ResourceManager HA)
本节内容: 环境规划 配置集群各节点hosts文件 安装JDK1.7 安装依赖包ssh和rsync 各节点时间同步 安装Zookeeper集群 添加Hadoop运行用户 配置主节点登录自己和其他节点不 ...
- Hadoop源码学习笔记之NameNode启动场景流程二:http server启动源码剖析
NameNodeHttpServer启动源码剖析,这一部分主要按以下步骤进行: 一.源码调用分析 二.伪代码调用流程梳理 三.http server服务流程图解 第一步,源码调用分析 前一篇文章已经锁 ...
- hadoop报错java.io.IOException: Incorrect configuration: namenode address dfs.namenode.servicerpc-address or dfs.namenode.rpc-address is not configured
不多说,直接上干货! 问题详情 问题排查 spark@master:~/app/hadoop$ sbin/start-all.sh This script is Deprecated. Instead ...
- Hadoop源码学习笔记之NameNode启动场景流程三:FSNamesystem初始化源码剖析
上篇内容分析了http server的启动代码,这篇文章继续从initialize()方法中按执行顺序进行分析.内容还是分为三大块: 一.源码调用关系分析 二.伪代码执行流程 三.代码图解 一.源码调 ...
- namenode无法启动(namenode格式化失败)
格式化namenode root@node04 bin]# sudo -u hdfs hdfs namenode –format 16/11/14 10:56:51 INFO namenode.Nam ...
- hdfs namenode -initializeSharedEdits 和 hdfs namenode -bootstrapStandby
hdfs namenode -initializeSharedEdits 将所有journal node的元文件的VERSION文件的参数修改成与namenode的元数据相同 hdfs namenod ...
随机推荐
- 【原创】多字节版本下MFC控件处理字符集的BUG
工程项目属性: 字符集:多字节 stdafx.h文件中添加: #pragma comment(linker,"/manifestdependency:\"type='win32' ...
- Linux系统如何禁止普通用户切换root?
Linux系统如何禁止普通用户切换root? 在上正文之前,我们先将一些基础的Linux用户以及用户组的相关命令: 1.添加用户 useradd [-g group] [-d user_home_di ...
- Segmentation fault(Core Dump)
Segmentation fault 这个提示还是比较常见的,这个提示就是段错误,这是翻译还是十分恰当的. Core Dump 有的时候给我们呈现的翻译很有趣是”吐核“,但是实际上比较贴切的翻译是核心 ...
- Mybatis resultMap灵活用法(使用子查询)
### 背景查询广州每个景点的总流量,和每个景点每日流量 #### 数据表 t_广州|唯一标识id|地点place|流量counts|日期date||:---:|:---:|:---:|:---:|| ...
- 记录一次没有收集直方图优化器选择全表扫描导致CPU耗尽
场景:数据库升级第二天,操作系统CPU使用率接近100%. 查看ash报告: 再看TOP SQL 具体SQL: select count(1) as chipinCount, sum(bets) as ...
- 更新UI放在主线程的原因
1.在子线程中是不能进行UI 更新的,而可以立刻更新的原因是:子线程代码执行完毕了,又自动进入到了主线程,这中间的时间非常的短,让我们误以为子线程可以更新UI.如果子线程一直在运行,则无法更新UI,因 ...
- c/c++面试指导---c语法总结
任何一门学科或者专业在学习的过程中都要把握总结框架,大家在面试c/c++职位过程中要应对各种企业的面试,回答企业面试官的各种技术问题.如何应对各种各样的关于c/c++的企业面试题目,从各种繁杂的题目中 ...
- 创建在类路径资源[applicationcontext]中定义名为“工厂”的bean时出错。:在设置bean属性“dataSource”时,无法解析对bean“dataSource”的引用;嵌套异常是org.springframe .beans.factory。BeanCreationException:创建名为“数据源”的bean时出错,该名称是在类路径资源[applicationcontext
控制台报错: 创建在类路径资源[applicationcontext]中定义名为“工厂”的bean时出错.:在设置bean属性“dataSource”时,无法解析对bean“dataSource”的引 ...
- Ubantu 更新时间方法
1.首先查看时区: swfsadmin@swfsubuntu:~$ date -RTue, 17 Dec 2013 18:23:01 +0800 如果要修改时区,执行sudo tzselect 2.选 ...
- js实现所有异步请求全部加载完毕后,loading效果消失
在实际开发中,一定有情况是这样的,一个页面我们有多个地方请求了ajax,在这种情况下,我们要实现数据没来之前出现我们炫酷的loading效果,而且要等到所有的ajax都请求完毕后,才让我们的loadi ...