K-means聚类算法与EM算法
K-means聚类算法
K-means聚类算法也是聚类算法中最简单的一种了,但是里面包含的思想却不一般。
聚类属于无监督学习。在聚类问题中,给我们的训练样本是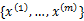 ,每个
,每个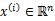 ,没有了y。
,没有了y。
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
1、 随机选取k个聚类质心点(cluster centroids)为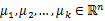 。
。
2、 重复下面过程直到收敛 {
对于每一个样例i,计算其应该属于的类
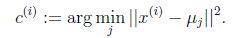
对于每一个类j,重新计算该类的质心
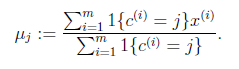
}
K是我们事先给定的聚类数, 代表样例i与k个类中距离最近的那个类,
代表样例i与k个类中距离最近的那个类, 的值是1到k中的一个。质心
的值是1到k中的一个。质心 代表我们对属于同一个类的样本中心点的猜测,重复迭代第一步和第二步直到质心不变或者变化很小。
代表我们对属于同一个类的样本中心点的猜测,重复迭代第一步和第二步直到质心不变或者变化很小。
K-means面对的第一个问题是如何保证收敛,前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数(distortion function)如下:

J函数表示每个样本点到其质心的距离平方和。
K-means是要将J调整到最小。
假设当前J没有达到最小值,那么首先可以固定每个类的质心 ,调整每个样例的所属的类别
,调整每个样例的所属的类别 来让J函数减少,同样,固定
来让J函数减少,同样,固定 ,调整每个类的质心
,调整每个类的质心 也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,
也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时, 和c也同时收敛。
和c也同时收敛。
由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的 和c输出。
和c输出。
下面累述一下K-means与EM的关系:
首先回到初始问题,我们目的是将样本分成K个类,其实说白了就是求一个样本例的隐含类别y,然后利用隐含类别将x归类。由于我们事先不知道类别y,那么我们首先可以对每个样例假定一个y吧,但是怎么知道假定的对不对呢?怎样评价假定的好不好呢?
我们使用样本的极大似然估计来度量,这里就是x和y的联合分布P(x,y)了。如果找到的y能够使P(x,y)最大,那么我们找到的y就是样例x的最佳类别了,x顺手就聚类了。但是我们第一次指定的y不一定会让P(x,y)最大,而且P(x,y)还依赖于其他未知参数,当然在给定y的情况下,我们可以调整其他参数让P(x,y)最大。但是调整完参数后,我们发现有更好的y可以指定,那么我们重新指定y,然后再计算P(x,y)最大时的参数,反复迭代直至没有更好的y可以指定。
这个过程有几个难点:
第一怎么假定y?是每个样例硬指派一个y还是不同的y有不同的概率,概率如何度量。
第二如何估计P(x,y),P(x,y)还可能依赖很多其他参数,如何调整里面的参数让P(x,y)最大。
EM算法的思想:E步就是估计隐含类别y的期望值,M步调整其他参数使得在给定类别y的情况下,极大似然估计P(x,y)能够达到极大值。然后在其他参数确定的情况下,重新估计y,周而复始,直至收敛。
从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量 ,M步更新其他参数
,M步更新其他参数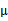 来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
EM算法就是这样,假设我们想估计知道A和B两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
EM的意思是“Expectation Maximization”
http://blog.csdn.net/zouxy09/article/details/8537620
K-means聚类算法与EM算法的更多相关文章
- MM 算法与 EM算法概述
1.MM 算法: MM算法是一种迭代优化方法,利用函数的凸性来寻找它们的最大值或最小值. MM表示 “majorize-minimize MM 算法” 或“minorize maximize MM 算 ...
- 机器学习优化算法之EM算法
EM算法简介 EM算法其实是一类算法的总称.EM算法分为E-Step和M-Step两步.EM算法的应用范围很广,基本机器学习需要迭代优化参数的模型在优化时都可以使用EM算法. EM算法的思想和过程 E ...
- 【机器学习】K-means聚类算法与EM算法
初始目的 将样本分成K个类,其实说白了就是求一个样本例的隐含类别y,然后利用隐含类别将x归类.由于我们事先不知道类别y,那么我们首先可以对每个样例假定一个y吧,但是怎么知道假定的对不对呢?怎样评价假定 ...
- Python实现机器学习算法:EM算法
''' 数据集:伪造数据集(两个高斯分布混合) 数据集长度:1000 ------------------------------ 运行结果: ---------------------------- ...
- 机器学习十大算法之EM算法
此文已由作者赵斌授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 由于目前论坛的Markdown不支持Mathjax,数学公式没法正常识别,文章只能用截图上传了... ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- EM 算法-对鸢尾花数据进行聚类
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍过K 均值算法,它是一种聚类算法.今天介绍EM 算法,它也是聚类算法,但比K 均值算法更加灵活强大. ...
- EM算法(1):K-means 算法
目录 EM算法(1):K-means 算法 EM算法(2):GMM训练算法 EM算法(3):EM算法运用 EM算法(4):EM算法证明 EM算法(1) : K-means算法 1. 简介 K-mean ...
- 极大似然估计、贝叶斯估计、EM算法
参考文献:http://blog.csdn.net/zouxy09/article/details/8537620 极大似然估计 已知样本满足某种概率分布,但是其中具体的参数不清楚,极大似然估计估计就 ...
随机推荐
- 为什么我要放弃javaScript数据结构与算法(第十章)—— 排序和搜索算法
本章将会学习最常见的排序和搜索算法,如冒泡排序.选择排序.插入排序.归并排序.快速排序和堆排序,以及顺序排序和二叉搜索算法. 第十章 排序和搜索算法 排序算法 我们会从一个最慢的开始,接着是一些性能好 ...
- C# 面试题 (二)
1. 什么是C#? C#是微软公司发布的一种面向对象的.运行于.NET Framework之上的高级程序设计语言.C#是一种安全的.稳定的.简单的.优雅的,由C和C++衍生出来的面向对象的编程语言. ...
- Linux getcwd()的实现
通过getcwd()可以获取当前工作目录. #include <unistd.h> char *getcwd(char *cwdbuf, size_t size); 成功调用返回指向cwd ...
- 武汉Uber优步司机奖励政策(12月21日-12.27日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- Python:pickle模块学习
1. pickle模块的作用 将字典.列表.字符串等对象进行持久化,存储到磁盘上,方便以后使用 2. pickle对象串行化 pickle模块将任意一个python对象转换成一系统字节的这个操作过程叫 ...
- maven的两种打包方式
1.maven目前在web上面的使用方式很普遍,而打包的方式也存在很多方式 2.因为涉及一个项目调用另外一个项目的包,并将另外一个项目打成jar的形式便于管理 3.maven打包第一种方式: 将项目检 ...
- xencenter迁移云主机方法
问题:POOL中计算节点内存不足. 解决方法:1.为计算节点添加内存(费用高)2.将部分资源迁移到其它POOL中. 方法: 1.选择要迁移的虚拟机 2.选择保存路径 这里可以看到可以批量导出: 注意: ...
- Qt-QML-Slider-滑块-Style
感觉滑块这个东西,可以算是一个基本模块了,在我的项目中也有这个模块,今天我将学一下一下滑块的使用以及美化工作. 想学习滑块,那就要先建立一个滑块,新建工程什么的这里就省略了,不会的可以看我前面的几篇文 ...
- html简约风用户登录界面网页制作html5-css-jquary-学习模版
2018--12-12 喜迎双十二,咳咳,,,,我不是打广告哈,购物的节日也不要忘记学习. 大家好,我又来了. 今天抽出来空把自己的学习心得给大家分享,这是一个可开发可扩展的用户登录界面,用于开发学习 ...
- 数据库Mysql的学习(七)-自定义函数和流程控制
DELIMITER // (设置结束符 其实我也不太明白为啥要这样 记住就行把) CREATE FUNCTION ym_date(mydate DATE) (创建函数 函数名字(参数)) ) (指定函 ...