基于MaxCompute InformationSchema进行冷门表热门表访问分析
一、需求场景分析
在实际的数据平台运营管理过程中,数据表的规模往往随着更多业务数据的接入以及数据应用的建设而逐渐增长到非常大的规模,数据管理人员往往希望能够利用元数据的分析来更好地掌握不同数据表的使用情况,从而优化数据模型。
一个MaxCompute项目中经常使用的表简称为热门表,使用次数较少或者很长时间不使用的表简称为冷门表,本文将介绍如何去通过MaxCompute元数据信息去分析热门表和冷门表。
二、方案设计思路
MaxCompute Information_Schema提供了项目中全量的表元数据信息Tables以及包含访问表的作业明细数据tasks_history,通过汇总各个表被作业访问的次数可以获知不同表被作业使用的频度。
详细步骤如下:
1、热门数据通过获取tasks_history表里的input_tables字段的详细信息,然后通过count统计一定时间分区内的各个表使用次数
2、冷门数据通过tables和tasks_history里的input_tables表的作业汇总数量进行关联、排序,从而统计出各张表在规定时间内的使用次数,正序排列
三、方案实现方法
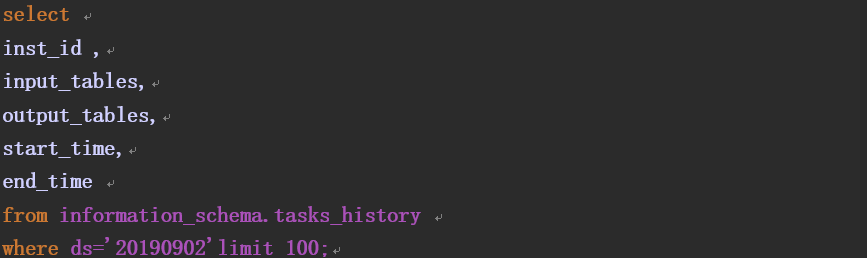
1、获取tasks_history表里的input_tables字段的详细信息。如下图所示:
查询数据的结果如下图所示:
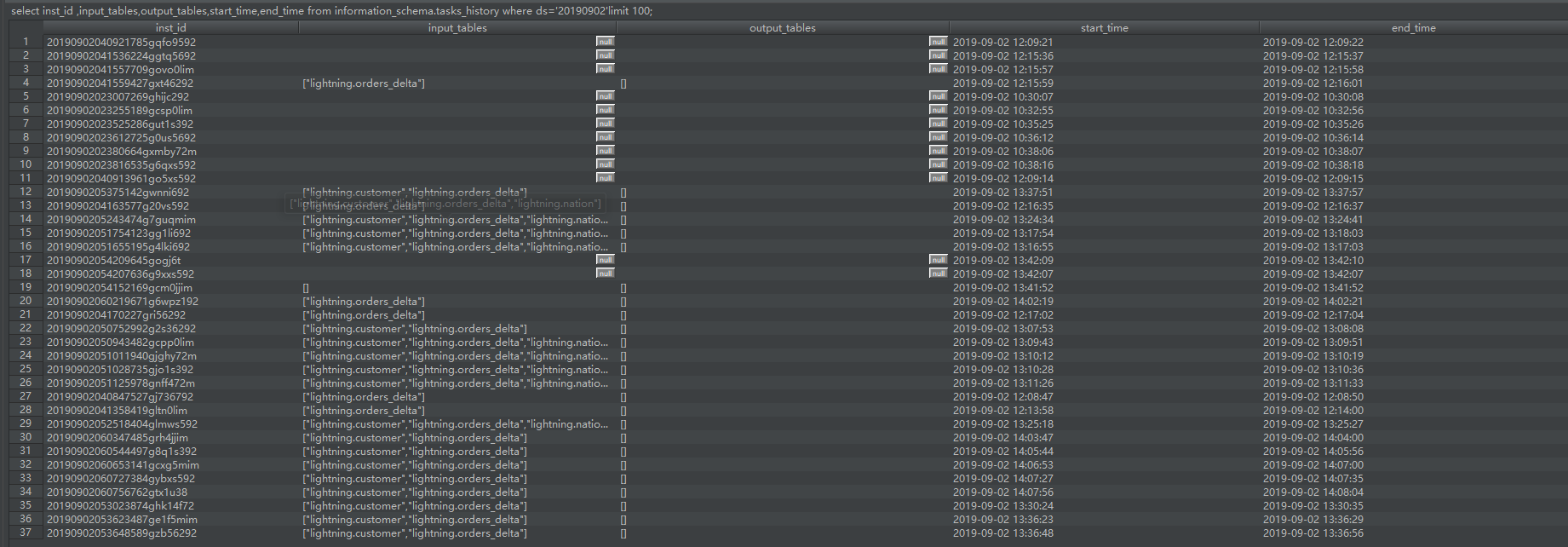
发现在tasks_history表中input_tables字段格式为
["lightning.customer","lightning.orders_delta"]
所以在统计的时候需要对字段进行按逗号分割
注意:案例中的时间分区可以根据需求去调整范围,区间根据实际场景去做相应的调整
例如:Ds>='20190902' and Ds<='20190905'
函数处理如下:

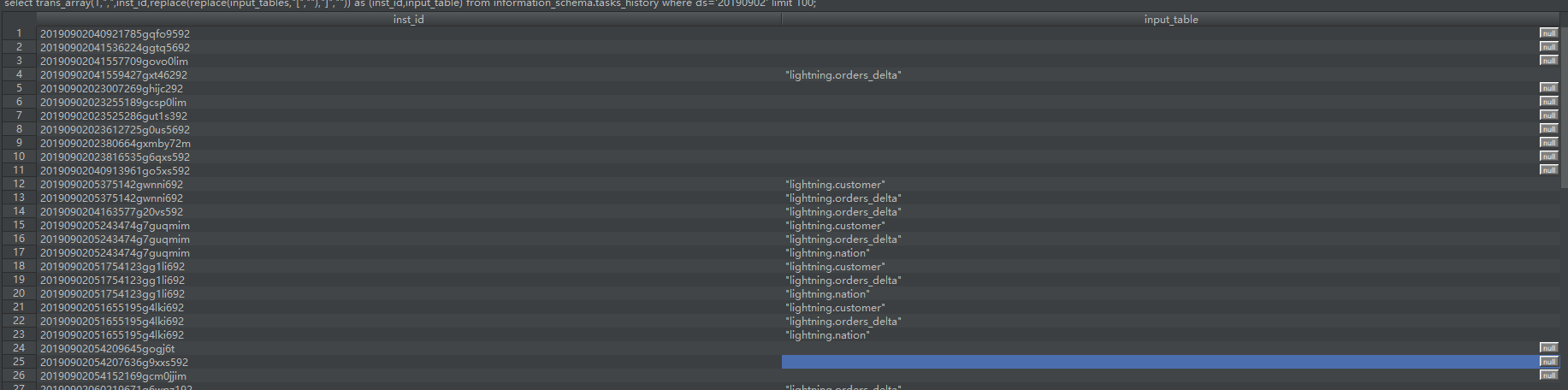
处理结果如下图:
2、统计热门表数据SQL编写:

结果如下图所示:

3、统计冷门表数据SQL编写:
通过tables和tasks_history里的input_tables表的作业汇总数量进行关联、排序,从而统计出各张表在规定时间内的使用次数,正序排列。
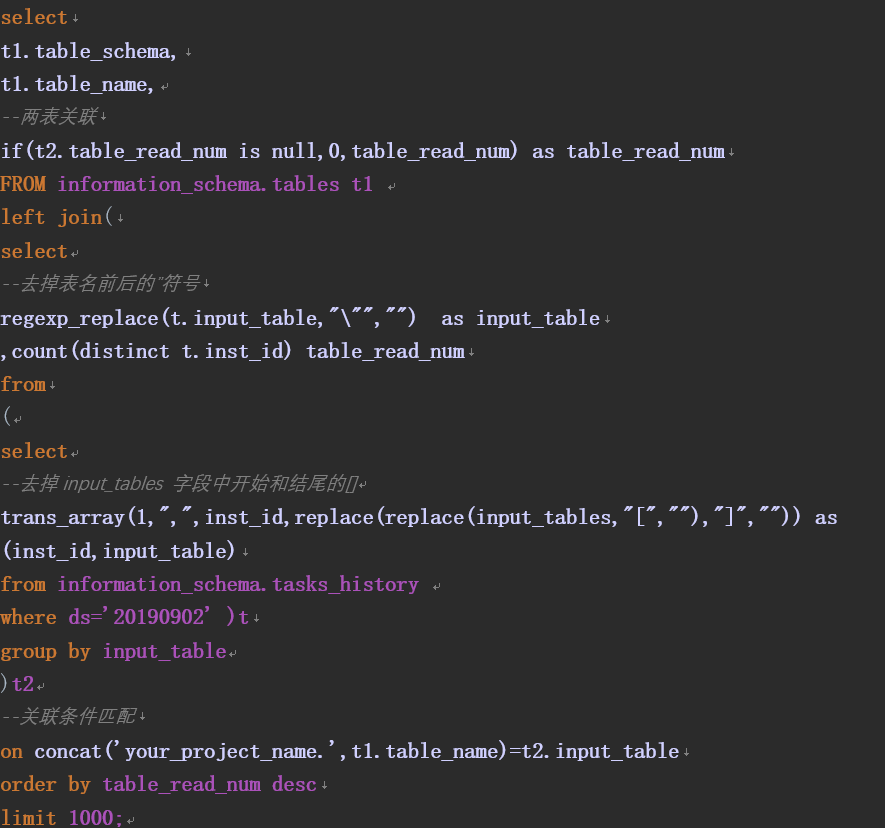
结果如下所示:


所有的表按照使用次数进行排序
即可得到各个表的使用次数排序信息。从而去进行合理化的管理数据表。
注意:SQL中的” your_project_name.”为表名前缀,客户需要参照自己的实际数据去做相应的修改调整。
本文作者:刘-建伟
本文为云栖社区原创内容,未经允许不得转载。
基于MaxCompute InformationSchema进行冷门表热门表访问分析的更多相关文章
- 基于MaxCompute InformationSchema进行血缘关系分析
一.需求场景分析 在实际的数据平台运营管理过程中,数据表的规模往往随着更多业务数据的接入以及数据应用的建设而逐渐增长到非常大的规模,数据管理人员往往希望能够利用元数据的分析来更好地掌握不同数据表的血缘 ...
- 基于MaxCompute打造轻盈的人人车移动端数据平台
摘要: 2019年1月18日,由阿里巴巴MaxCompute开发者社区和阿里云栖社区联合主办的“阿里云栖开发者沙龙大数据技术专场”走近北京联合大学,本次技术沙龙上,人人车大数据平台负责人吴水永从人人车 ...
- 基于MaxCompute的数仓数据质量管理
声明 本文中介绍的非功能性规范均为建议性规范,产品功能无强制,仅供指导. 参考文献 <大数据之路——阿里巴巴大数据实践>——阿里巴巴数据技术及产品部 著. 背景及目的 数据对一个企业来说已 ...
- "《算法导论》之‘线性表’":基于静态分配的数组的顺序表
首先,我们来搞明白几个概念吧(参考自网站数据结构及百度百科). 线性表 线性表是最基本.最简单.也是最常用的一种数据结构.线性表中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外, ...
- MySQL基于左右值编码的树形数据库表结构设计
MySQL基于左右值编码的树形数据库表结构设计 在关系型数据库中设计树形的数据结构一直是一个十分考验开发者能力的,最常用的方案有主从表方案和继承关系(parent_id)方案.主从表方案的最大缺点 ...
- Django框架(十)—— 多表操作:一对一、一对多、多对多的增删改,基于对象/双下划线的跨表查询、聚合查询、分组查询、F查询与Q查询
目录 多表操作:增删改,基于对象/双下划线的跨表查询.聚合查询.分组查询.F查询与Q查询 一.创建多表模型 二.一对多增删改表记录 1.一对多添加记录 2.一对多删除记录 3.一对多修改记录 三.一对 ...
- 基于MaxCompute的媒体大数据开放平台建设
摘要:随着自媒体的发展,传统媒体面临着巨大的压力和挑战,新华智云运用大数据和人工智能技术,致力于为媒体行业赋能.通过媒体大数据开放平台,将媒体行业全网数据汇总起来,借助平台数据处理能力和算法能力,将有 ...
- 使用SparkSql进行表的分析与统计
# 背景 我们的数据挖掘平台对数据统计有比较迫切的需求,而Spark本身对数据统计已经做了一些工作,希望梳理一下Spark已经支持的数据统计功能,后期再进行扩展. # 准备数据 在参考文献6中下载 ...
- Mysql单表访问方法,索引合并,多表连接原理,基于规则的优化,子查询优化
参考书籍<mysql是怎样运行的> 非常推荐这本书,通俗易懂,但是没有讲mysql主从等内容 书中还讲解了本文没有提到的子查询优化内容, 本文只总结了常见的子查询是如何优化的 系列文章目录 ...
随机推荐
- 职位-CHO:CHO
ylbtech-职位-CHO:CHO 首席人力资源官(Chief Human Resource Officer),简称CHO.是具有制定集团化经营的公司人力资源的战略规划,并监督执行,负责建立畅通的沟 ...
- 阶段1 语言基础+高级_1-3-Java语言高级_06-File类与IO流_04 IO字节流_12_练习_文件复制
谁用字节可以读取任何文件. 读取后再写入到D盘去.这就是一个文件的复制. 怎么由C盘到D盘.这里要借助流技术 需要创建两个流,一个读取一个写入 图片复制过来了. 看一下图片的字节数.whilte循环要 ...
- 关于hadoop登陆kerberos时设置环境变量问题的思考
中心思想,设置kerberos环境变量时,发现JDK源码当中的一个问题,故描述如下. 在平时的使用中,如果hadoop集群配置kerberos认证的话,使用java访问hdfs或者hive时,需要先进 ...
- node+express 中安装nodemon实时更新server.js
每次启动node server.js,有一个缺点,每次server.js文件有改动时,必须重新执行指令node server.js,新的代码才会起作用 解决方案1 全局安装 npm install s ...
- 【ABAP系列】SAP 关于出口(user-exit)MV50AFZ1的一些问题
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[ABAP系列]SAP 关于出口(user-ex ...
- 应用安全-安全设备-Waf系列-软Waf-云锁
安装 安装 - Linux 前提:检查selinux状态 - 关闭selinux getenforce #显示为disabled则为关闭 .下载 x86:wget http://download.yu ...
- Collections与Arrays工具类
Collections工具类: 排序操作: void reverse(List list)//反转 void shuffle(List list)//随机排序 void sort(List list) ...
- Oracle数据库用户介绍
Oracle数据库创建的时候,创建了一系列默认的用户,有时候可能我们不小心忘记创建了某个用户,比如SCOTT用户,我们就需要使用Oracle提供的脚本来创建,介绍如下: 1.SYS/change_on ...
- ofbiz框架以及核心原理介绍
1. 什么是Ofbiz Ofbiz(Open for business)是一个开源的,基于J2EE和XML规范的,用于构建大型企业级.跨平台.跨数据库.跨应用服务器的多层.分布式电子商务类WEB应用系 ...
- qemu-kvm使用
创建镜像qemu-img create -f qcow2 test-vm.qcow2 10g 修改镜像大小qemu-img resize test-vm.qcow2 +10G 安装系统 qem ...