【CDN+】 Hbase入门 以及Hbase shell基础命令
前言
大数据的基础离不开Hbase, 本文就hbase的基础概念,特点,以及框架进行简介, 实际操作种需要注意hbase shell的使用。
Hbase 基础
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统(可以看成一种新型的分布式数据库),利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBASE介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
HBASE的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBASE是Google Bigtable的开源实现,HBASE利用Hadoop HDFS作为其文件存储系统;利用Hadoop MapReduce来处理HBASE中的海量数据;利用Zookeeper作为协同服务。
普通数据库的短板
1)数据量很大的时候无法存储;
2)没有很好的备份机制;
3)数据达到一定数量开始缓慢,很大的话基本无法支撑;
Hbase 的优点
- 线性扩展,随着数据量增多可以通过节点扩展进行支撑;
- 数据存储在hdfs上,备份机制健全;
- 通过zookeeper协调查找数据,访问速度快。
- 一个表可以有上亿行,上百万列
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索。
- 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
HBASE的架构
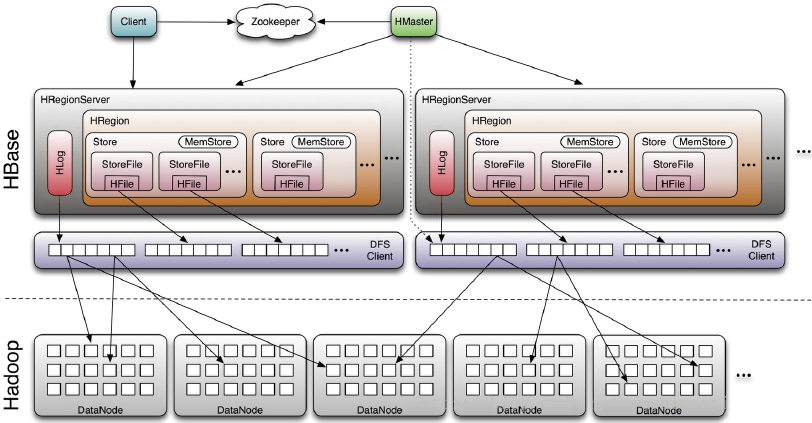
组成部件说明,从上而下:
Client:
- 使用HBase RPC机制与HMaster和HRegionServer进行通信
- Client与HMaster进行管理类操作
- Client与HRegionServer进行数据读写类操作
Zookeeper:
- Zookeeper Quorum存储-ROOT-表地址、HMaster地址
- HRegionServer把自己以Ephedral方式注册到Zookeeper中,HMaster随时感知各个HRegionServer的健康状况
- Zookeeper避免HMaster单点问题
Zookeeper的主要作用:客户端首先联系ZooKeeper子集群(quorum)(一个由ZooKeeper节点组成的单独集群)查找行健。上述过程是通过ZooKeeper获取含有-ROOT-的region服务器名(主机名)来完成的。通过含有-ROOT-的region服务器可以查询到含有.META.表中对应的region服务器名,其中包含请求的行健信息。这两处的主要内容都被缓存下来了,并且都只查询一次。最终,通过查询.META服务器来获取客户端查询的行健数据所在region的服务器名。一旦知道了数据的实际位置,即region的位置,HBase会缓存这次查询的信息,同时直接联系管理实际数据的HRegionServer。所以,之后客户端可以通过缓存信息很好地定位所需的数据位置,而不用再次查找.META.表。
HMaster:
HMaster没有单点问题,HBase可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master在运行
主要负责Table和Region的管理工作:
- 1. 管理用户对表的增删改查操作
- 2. 管理HRegionServer的负载均衡,调整Region分布
- 3. Region Split后,负责新Region的分布
- 4. 在HRegionServer停机后,负责失效HRegionServer上Region迁移
HRegionServer:
HBase中最核心的模块,主要负责响应用户I/O请求,向HDFS文件系统中读写
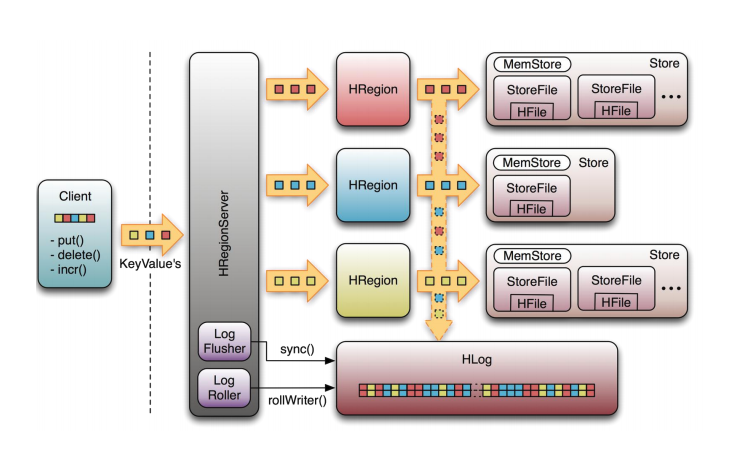
- HRegionServer管理一系列HRegion对象;
- 每个HRegion对应Table中一个Region,HRegion由多个HStore组成;
- 每个HStore对应Table中一个Column Family的存储;
- Column Family就是一个集中的存储单元,故将具有相同IO特性的Column放在一个Column Family会更高效。
可以看到,client访问hbase上的数据并不需要master参与(寻址访问zookeeper和region server,数据读写访问region server),master仅仅维护table和region的元数据信息(table的元数据信息保存在zookeeper上),负载很低。HRegionServer存取一个子表时,会创建一个HRegion对象,然后对表的每个列族创建一个Store实例,每个Store都会有一个MemStore和0个或多个StoreFile与之对应,每个StoreFile都会对应一个HFile,HFile就是实际的存储文件。因此,一个HRegion(表)有多少个列族就有多少个Store。一个HRegionServer会有多个HRegion和一个HLog。
HRegion:
table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。
Region按大小分隔,每个表一般是只有一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阀值(默认256M)时就会分成两个新的region。
每个region由以下信息标识:
- <表名,startRowKey,创建时间>
- 由目录表(-ROOT-和.META.)记录该region的endRowKey
HRegion定位:Region被分配给哪个RegionServer是完全动态的,所以需要机制来定位Region具体在哪个region server。
HBase使用三层结构来定位region:
- 通过zookeeper里的文件/hbase/rs得到-ROOT-表的位置。-ROOT-表只有一个region。
- 通过-ROOT-表查找.META.表的第一个表中相应的region的位置。其实-ROOT-表是.META.表的第一个region;.META.表中的每一个region在-ROOT-表中都是一行记录。
- 通过.META.表找到所要的用户表region的位置。用户表中的每个region在.META表中都是一行记录。
注意:
-ROOT-表永远不会被分隔为多个region,保证了最多需要三次跳转,就能定位到任意的region。client会将查询的位置信息缓存起来,缓存不会主动失效,因此如果client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的region,其中三次用来发现缓存失效,另外三次用来获取位置信息。
table和region的关系
table默认最初只有一个region,随着记录数的不断增加而变大,起初的region会逐渐分裂成多个region,一个region有【startKey, endKey】表示,不同的region会被master分配给相应的regionserver管理。
region是hbase分布式存储和负载均衡的最小单元,不同的region分不到不同的regionServer。
注意:region虽然是分布式存储的最小单元,但并不是存储的最小单元。region是由一个或者多个store组成的,每个store就是一个column family。每个store又由memStore和1至多个store file 组成(memstore到一个阀值会刷新,写入到storefile,有hlog来保证数据的安全性,一个regionServer有且只有一个hlog)
HStore:
HBase存储的核心。由MemStore和StoreFile组成。MemStore是Stored Memory Buffer。
HLog:
引入HLog原因:在分布式系统环境中,无法避免系统出错或者宕机,一旦HRegionServer意外退出,MemStore中的内存数据就会丢失,引入HLog就是防止这种情况。
工作机制:
每个HRegionServer中都会有一个HLog对象,HLog是一个实现Write Ahead Log的类,每次用户操作写入MemStore的同时,也会写一份数据到HLog文件,HLog文件定期会滚动出新,并删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知,HMaster首先处理遗留的HLog文件,将不同region的log数据拆分,分别放到相应region目录下,然后再将失效的region重新分配,领取到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
Hbase shell 基础命令
1. 进入Linux 系统,输入hbase shell 可以进入到hbase的命令行模式
| 名称 | 命令表达式 |
| 查看hbase状态 | status |
| 创建表 | create '表名','列族名1','列族名2','列族名N' |
| 查看所有表 | list |
| 描述表 | describe '表名' |
| 判断表存在 | exists '表名' |
| 判断是否禁用启用表 |
is_enabled '表名' |
| 添加记录 | put '表名','rowkey','列族:列','值' |
| 查看记录rowkey下的所有数据 | get '表名','rowkey' |
| 查看所有记录 | scan '表名' |
| 查看表中的记录总数 | count '表名' |
| 获取某个列族 | get '表名','rowkey','列族:列' |
| 获取某个列族的某个列 | get '表名','rowkey','列族:列' |
| 删除记录 | delete '表名','行名','列族:列' |
| 删除整行 | deleteall '表名','rowkey' |
| 删除一张表 |
先要屏蔽该表,才能对该表进行删除 |
| 清空表 | truncate '表名' |
| 查看某个表某个列中所有数据 | scan '表名',{COLUMNS=>'列族名:列名'} |
| 更新记录 | 就是重新一遍,进行覆盖,hbase没有修改,都是追加 |
具体实例:
1、查看HBase运行状态 status

2、创建表 create <table>,{NAME => <family>, VERSIONS => <VERSIONS>}
创建一个User表,并且有一个info列族

3、查看所有表 list

4、描述表详情 describe 'User'

5、判断表是否存在 exists 'User'

6、启用或禁用表 is_disabled 'User' is_enabled 'User'

7、添加记录,即插入数据,语法:put <table>,<rowkey>,<family:column>,<value>

8、根据rowKey查询某个记录,语法:get <table>,<rowkey>,[<family:column>, ...]

9、查询所有记录,语法:scan <table>,{COLUMNS => [family:column, ...], LIMIT => num}
扫描所有记录

扫描前2条

范围查询

另外,还可以添加TIMERANGE和FILTER等高级功能,STARTROW、ENDROW必须大写,否则报错,查询结果不包含等于ENDROW的结果集。
10、统计表记录数,语法:count <table>, {INTERVAL => intervalNum,CACHE => cacheNum}
INTERVAL设置多少行显示一次及对应的rowkey,默认1000;CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度。

11、删除
删除列

删除整行

删除表中所有数据

12、禁用或启用表
禁用表

启用表

12、删除表
删除前,必须先disable

参考: https://www.cnblogs.com/swordfall/p/8737328.html
https://blog.csdn.net/lukabruce/article/details/80624619
https://www.w3cschool.cn/hbase_doc/
【CDN+】 Hbase入门 以及Hbase shell基础命令的更多相关文章
- windows下使用redis,Redis入门使用,Redis基础命令
windows下使用redis,Redis入门使用,Redis基础命令 >>>>>>>>>>>>>>>> ...
- 运维 04 Shell基础命令(二)
Shell基础命令(二) 查看Linux的发行版 cat /etc/redhat-release cat /etc/os-release 查看系统用户的id信息 id 用户名 id root id ...
- 运维02 Shell基础命令(一)
Shell基础命令(一) Shell 教程 Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁.Shell 既是一种命令语言,又是一种程序设计语言. Shell 是指一种应 ...
- Linux从入门到进阶全集——【第十四集:Shell基础命令】
1,Shell就是命令行执行器 2,作用:将外层引用程序的例如ls ll等命令进行解释成01表示的二进制代码给内核,从而让硬件执行:硬件的执行结果返回给shell,shell解释成我们能看得懂的代码返 ...
- 第二篇:shell基础命令(部分)
目录 一.shell命令规则 二.基础命令详解(部分) ls :列出目录内容 mkdir : 创建目录 rmdir :删除目录 touch:新建文件 mv:修改文件(目录)名.移动路径 cp:复制文件 ...
- HBase集群部署与基础命令
HBase 集群部署 安装 hbase 之前需要先搭建好 hadoop 集群和 zookeeper 集群.hadoop 集群搭建可以参考:https://www.cnblogs.com/javammc ...
- HBase笔记之远程Shell界面命令行无法删除字符的解决方案
方法一: 设置终端退格键为ASCII 127 在XShell的界面中,设置 文件 --> 属性 --> 终端 --> 键盘 --> BACKSPACE键序列,改为ASCII 1 ...
- Shell基础命令(一)
Shell 教程 Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁.Shell 既是一种命令语言,又是一种程序设计语言. Shell 是指一种应用程序,这个应用程序提供了一个 ...
- Git入门(安装及基础命令行操作)
一.安装 1.Mac 在Mac中安装Git的方法不止一种.最简单的要数通过Xcode命令行工具.对于Mavericks(10.9)或更高版本的操作系统,当你第一次尝试在终端执行git命令时,系统会自动 ...
随机推荐
- PS把一张白色背景的图片设为透明
方法一: 1.双击图层缩略图上的小锁图标(注意,这里不要拖动小锁进行删除锁定),弹出“新建图层”,确定 2.右键左侧第四个功能菜单,选择魔棒工具 3.用魔棒工具在白色背景区域点击一下,选中白色区域背景 ...
- HTTP response status
The status code is a 3-digit number: 1xx (Informational): Request received, server is continuing the ...
- web 前端3 javascript基础
JavaScript是一门编程语言,浏览器内置了JavaScript语言的解释器,所以在浏览器上按照JavaScript语言的规则编写相应代码之,浏览器可以解释并做出相应的处理. 一.如何编写 1.J ...
- 在VS Code中使用Jupyter Notebook
一.安装配置 1.在扩展商店中安装官方的Python扩展包 2.系统已经安装了Jupyter Notebook 由于系统上的Python环境是用Anaconda安装的,已经有Jupyter Noteb ...
- Bootstrap selectpicker 强制向下
selectpicker的方向是自适应的,但是有些界面,我们需要强制向下,可以使用属性data-dropup-auto data-dropup-auto="false" 官网上的o ...
- SSM框架—Spring+SpringMVC+MyBatis
1.环境搭建 1.1概念 Spring是一个Java应用的开源框架,Bean/Context/Core/IOC/AOP/MVC等是其重要组件,IOC控制反转,AOP面向切面编程,各种注入方式,实现方式 ...
- 通过document.domain实现跨域访问
通过document.domain实现跨域访问:https://blog.csdn.net/nlznlz/article/details/79506655 前端跨域方法之document.domain ...
- Spring-Boot 整合Dubbo 解决@Reference 注解为null情况
首先检查一下你的spring boot版本是多少? 如果是2.X 不用看了,spring boot 2.x 必定会出现这个问题, 改为 1.5.9 或其他1.x版本,目前生产环境建议使用1.x版本. ...
- 1897. tank 坦克游戏
传送门 显然考虑 $dp$,发现时间只和当前位置和攻击次数有关,设 $F[i][j][k]$ 表示当前位置为 $i,j$ ,攻击了 $k$ 次得到的最大分数 初始 $f[1][1][k]$ 为位置 $ ...
- RequireJS 入门(二)
简介 如今最常用的JavaScript库之一是RequireJS.最近我参与的每个项目,都用到了RequireJS,或者是我向它们推荐了增加RequireJS.在这篇文章中,我将描述RequireJS ...