《Hadoop学习之路》学习实践二——配置idea远程调试hadoop
背景:在上篇文章中按照大神“扎心了老铁”的博客,在服务器上搭建了hadoop的伪分布式环境。大神的博客上是使用eclipse来调试,但是我入门以来一直用的是idea,eclipse已经不习惯,于是便摸索着配置了idea远程调试hadoop的环境。
步骤一:
下载与服务器上的hadoop同版本的hadoop安装包,我下载的是hadoop-2.7.7.tar.gz,下载后解压到某个目录,比如D:\Software\hadoop-2.7.7,不需要其他配置和安装
步骤二:
下载hadooop.dll和winutils.exe,这两个文件主要是调试运行的时候要用,不然运行会报错。我是在网上下载的2.7.x版本的压缩包。解压后放置在D:\Software\hadoop-2.7.7/bin/文件夹下:
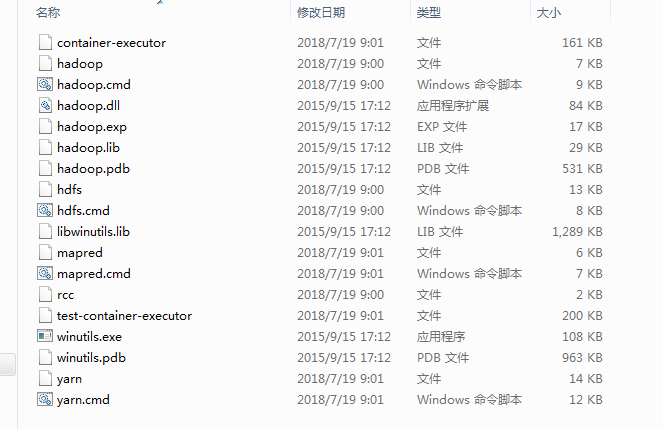
同时将hadoop.dll文件复制到C:\Windows\System32下,并且重启电脑,否则会报错
Exception in thread "main"java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
步骤三:
配置系统环境变量:
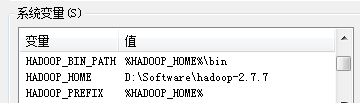
配置环境变量Path,在现有Path后追加 %HADOOP_HOME%\bin;%HADOOP_HOME%\sbin;
步骤四:
在idea中新建一个maven项目,配置pom.xml依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.7</version>
</dependency> </dependencies>
步骤五:将服务器上集群中hadoop/etc/hadoop/下的core-site.xml和hdfs-site.xml和log4j.properties配置复制到idea项目下的resources路径下
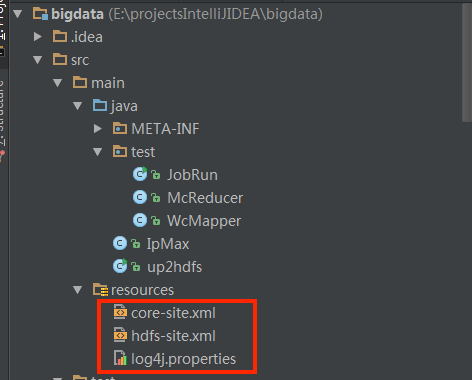
注意1:core-site.xml中的fs.defaultFS的值的ip不可用localhost,否则服务器不暴露ip,从PC本地上无法连上hadoop服务;ip在服务器和本地同步修改,服务器端修改后需重启hadoop服务
步骤六:代码测试
测试1-网上的hdfs读写的例子up2hdfs.java,直接运行即可
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils; import java.io.*;
import java.net.URI; public class up2hdfs { private static String HDFSUri = "hdfs://10.164.96.220:9000"; /**
* 1、获取文件系统
*
* @retrun FileSystem 文件系统
*/ public static FileSystem getFileSystem(){ //读取配置文件
Configuration conf = new Configuration(); //文件系统
FileSystem fs = null;
String hdfsUri = HDFSUri;
if (StringUtils.isBlank(hdfsUri)){
//返回默认文件系统,如果在hadoop集群下运行,使用此种方法可直接获取默认文件系统;
try{
fs = FileSystem.get(conf);
}catch(IOException e){
e.printStackTrace();
}
}else{
//返回指定的文件系统,如果在本地测试,需要此种方法获取文件系统;
try{
URI uri = new URI(hdfsUri.trim());
fs = FileSystem.get(uri,conf);
} catch (Exception e) {
e.printStackTrace();
}
}
return fs ;
} /**
* 2、创建文件目录
* @param path 文件路径
*/
public static void mkdir(String path){ try {
FileSystem fs = getFileSystem();
System.out.println("FilePath"+path);
//创建目录
fs.mkdirs(new Path(path));
//释放资源
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
} /**
* 3、判断目录是否存在
*
* @param filePath 目录路径
* @param create 若不存在是否创建
*
*/
public static boolean existDir(String filePath,boolean create){ boolean flag = false; if (StringUtils.isNotEmpty(filePath)){
return flag;
} try{
Path path = new Path(filePath);
//FileSystem对象
FileSystem fs = getFileSystem();
if (create){
if (!fs.exists(path)){
fs.mkdirs(path);
}
} if (fs.isDirectory(path)){
flag = true;
} }catch (Exception e){
e.printStackTrace(); } return flag; } /**
* 4、本地文件上传至HDFS
*
* @param srcFile 源文件路径
* @param destPath 目的文件路径
*/ public static void copyFileToHDFS(String srcFile,String destPath) throws Exception{ FileInputStream fis = new FileInputStream(new File(srcFile));//读取本地文件
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(URI.create(HDFSUri+destPath),config);
OutputStream os = fs.create(new Path(destPath));
//cpoy
IOUtils.copyBytes(fis,os,4096,true); System.out.println("copy 完成 ......");
fs.close();
} /**
* 5、从HDFS下载文件到本地
*
* @param srcFile 源文件路径
* @param destPath 目的文件路径
*
*/
public static void getFile(String srcFile,String destPath)throws Exception{ //HDFS文件地址
String file = HDFSUri+srcFile;
Configuration config = new Configuration();
//构建filesystem
FileSystem fs = FileSystem.get(URI.create(file),config);
//读取文件
InputStream is = fs.open(new Path(file));
IOUtils.copyBytes(is,new FileOutputStream(new File(destPath)),2048,true);
System.out.println("下载完成......");
fs.close();
} /**
* 6、删除文件或者文件目录
*
* @param path
*/
public static void rmdir(String path){ try {
//返回FileSystem对象
FileSystem fs = getFileSystem(); String hdfsUri = HDFSUri;
if (StringUtils.isNotBlank(hdfsUri)){ path = hdfsUri+path;
}
System.out.println("path"+path);
//删除文件或者文件目录 delete(Path f)此方法已经弃用
System.out.println(fs.delete(new Path(path),true)); fs.close();
} catch (Exception e) {
e.printStackTrace();
} } /**
* 7、读取文件的内容
*
* @param filePath
* @throws IOException
*/
public static void readFile(String filePath)throws IOException{ Configuration config = new Configuration();
String file = HDFSUri+filePath;
FileSystem fs = FileSystem.get(URI.create(file),config);
//读取文件
InputStream is =fs.open(new Path(file));
//读取文件
IOUtils.copyBytes(is, System.out, 2048, false); //复制到标准输出流
fs.close();
} /**
* 主方法测试
*/
public static void main(String[] args) throws Exception {//200 //连接fs FileSystem fs = getFileSystem();
System.out.println(fs.getUsed());
//创建路径
mkdir("/dit2");
//验证是否存在
System.out.println(existDir("/dit2",false));
//上传文件到HDFS
copyFileToHDFS("G:\\testFile\\HDFSTest.txt","/dit/HDFSTest.txt");
//下载文件到本地
getFile("/dit/HDFSTest.txt","G:\\HDFSTest.txt");
// getFile(HDFSFile,localFile);
//删除文件
rmdir("/dit2");
//读取文件
readFile("/dit/HDFSTest.txt");
} }
测试2-网上的mapreduce的例子
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer; public class WcMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// IntWritable one=new IntWritable(1);
String line=value.toString();
StringTokenizer st=new StringTokenizer(line);
//StringTokenizer "kongge"
while (st.hasMoreTokens()){
String word= st.nextToken();
context.write(new Text(word),new IntWritable(1)); //output
}
}
}
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException; /**
* Created by iespark on 2/26/16.
*/
public class McReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> iterable, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable i:iterable){
sum=sum+i.get();
}
context.write(key,new IntWritable(sum));
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* Created by iespark on 2/26/16.
*/
public class JobRun {
public static void main(String[] args){
System.setProperty("hadoop.home.dir", "D:\\Software\\hadoop-2.7.7");
Configuration conf=new Configuration();
try{
Job job = Job.getInstance(conf, "word count");
// Configuration conf, String jobName;
job.setJarByClass(JobRun.class);
job.setMapperClass(WcMapper.class);
job.setReducerClass(McReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//解决No job jar file set. User classes may not be found. See Job or Job#setJar(String)报错的问题
// job.setJar("E:\\idea2017workspace\\myhadoop\\out\\artifacts\\myhadoop_jar\\myhadoop.jar"); FileInputFormat.addInputPath(job,new Path(args[0]));
FileSystem fs= FileSystem.get(conf);
Path op1=new Path(args[1]);
if(fs.exists(op1)){
fs.delete(op1, true);
System.out.println("存在此输出路径,已删除!!!");
}
FileOutputFormat.setOutputPath(job,op1);
System.exit(job.waitForCompletion(true)?0:1);
}catch (Exception e){
e.printStackTrace();
}
}
}
JobRun.java运行时需要输入参数,hdfs计算输入和输出的路径,或者在run configurations中配置,如下图,注意路径的hdfs地址需要为core-site.xml中的地址
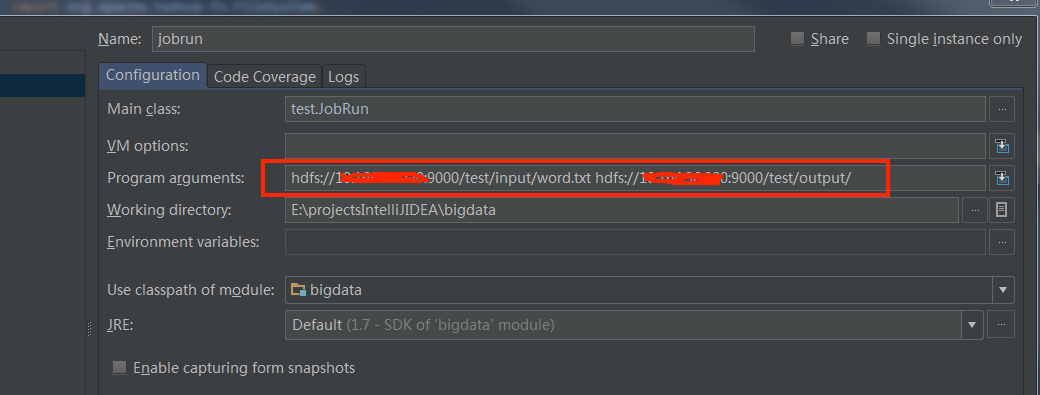
《Hadoop学习之路》学习实践二——配置idea远程调试hadoop的更多相关文章
- Hadoop学习之配置Eclipse远程调试Hadoop
构建完毕Hadoop项目后,接下来就应该跟踪Hadoop的运行情况,比方在命令行运行hadoop namenode–format时运行了Hadoop的那些代码.当然也能够直接通过阅读源码的方式来做到这 ...
- IDEA远程调试hadoop程序
远程调试Hadoop各组件 Hadoop学习之配置Eclipse远程调试Hadoop IDEA远程调试hadoop Hadoop 研发之远程调试详细剖析--WordCount V2.0 eclipse ...
- 远程调试Hadoop
远程调试对应用程序开发十分有用,那如何调试Hadoop源码?这里介绍如何用IDE远程调试Hadoop源码.本文以IntelliJ IDEA作为IDE,以调试Jobhistory WEB UI代码为例进 ...
- eclipse/intellij idea 远程调试hadoop 2.6.0
很多hadoop初学者估计都我一样,由于没有足够的机器资源,只能在虚拟机里弄一个linux安装hadoop的伪分布,然后在host机上win7里使用eclipse或Intellj idea来写代码测试 ...
- eclipse远程调试Hadoop
环境需求: 系统:window 10 eclipse版本:Mars Hadoop版本:2.6.0 资源需求:解压后的Hadoop-2.6.0,原压缩包自行下载:下载地址 丑话前头说: 以下的操作中,e ...
- 远程调试hadoop各组件
远程调试对应用程序开发十分有用.例如,为不能托管开发平台的低端机器开发程序,或在专用的机器上(比如服务不能中断的 Web 服务器)调试程序.其他情况包括:运行在内存小或 CUP 性能低的设备上的 Ja ...
- FastAPI 学习之路(十二)接口几个额外信息和额外数据类型
系列文章: FastAPI 学习之路(一)fastapi--高性能web开发框架 FastAPI 学习之路(二) FastAPI 学习之路(三) FastAPI 学习之路(四) FastAPI 学习之 ...
- Hadoop学习之路(八)在eclispe上搭建Hadoop开发环境
一.添加插件 将hadoop-eclipse-plugin-2.7.5.jar放入eclipse的plugins文件夹中 二.在Windows上安装Hadoop2.7.5 版本最好与Linux集群中的 ...
- Git学习之路(5)- 同步到远程仓库及多人协作问题
▓▓▓▓▓▓ 大致介绍 我们写好文件后添加到版本库,但是这样还没有做完,我们还需要将它同步到GitHub的远程仓库上,这里就以我们刚开始的drag项目为例,我们在Git学习之路(2)-安装GIt和创建 ...
随机推荐
- 面试题40:最小(大)的K个数
剑指offer40题,同时这也是面试高发题目 2019.4 蚂蚁金服问道:求1000万个数据中的前K个数. 思路: 1.直接上排序算法,然后我们就取排好顺序的前K个即可.但是单考虑快排,时间复杂度也要 ...
- HTML段落,换行,字符实体
HTML段落,换行,字符实体 html段落 <p>标签定义一个文本段落,一个段落含有默认的上下间距,段落之间会用这种默认间距隔开,代码如下: <!DOCTYPE html> & ...
- python 装饰器 第八步:使用类来作为装饰器参数
#第八步:使用类作为装饰器参数 #装饰器使用的操作类 class Wish: #祈求方法 def before(): print('饭前洗洗手') #还愿方法 def after(): print(' ...
- Python多进程、多线程和协程简介
一.进程和线程 进程是一个执行中的程序.每个进程都拥有自己的地址空间.内存.数据栈以及其他用于跟踪执行的辅助数据.在单核CPU系统中的多进程,内存中可以有许多程序,但在给定一个时刻只有一个程序在运行: ...
- Spring 常犯的十大错误,打死都不要犯!
原文:https://www.toptal.com/spring/top-10-most-common-spring-framework-mistakes 作者:Toni Kukurin,译者:万想 ...
- 初识Flink-从WorldCount开始
Apache Flink是一个用于分布式流和批处理数据处理的开源平台.Flink的核心是流数据流引擎,为数据流上的分布式计算提供数据分发,通信和容错.Flink在流引擎之上构建批处理,覆盖本机迭代支持 ...
- js转换成布尔类型boolean
/** * js转换成布尔值 * a.转换方法:Boolean(var) * b.数字转换成布尔,除了0与NaN,其余都是true * c.字符串转换成布尔,除了空串"",其余都是 ...
- ARM-LINUX学习记录
1:调用C语言函数之前会有一段汇编代码在前面执行来完成软硬件方面的初始化.比如:关闭看门狗:初始化时钟:设置堆栈:调用main函数等.在学习51单片机时候这些操作是由开发环境(如KEIL)在编译C代码 ...
- 【串线篇】SQL映射文件EmployeeDao.xml事项
Dao.xml或者说是mapper.xml一个意思 id:方法名,相当于这个配置是对于某个方法的实现 ,参数类型不用写,()也不用写 resultType:指定方法运行后的返回值类型全类名:(查询操作 ...
- githup上传项目到仓库
1.有了自己的账号 2.创建一个新的项目,填写项目名称,描述 填写完成点击create repository 3.复制生成的https链接接下来用到 4.进入到你的项目所在目录右键git bash打开 ...