spark 笔记 8: Stage
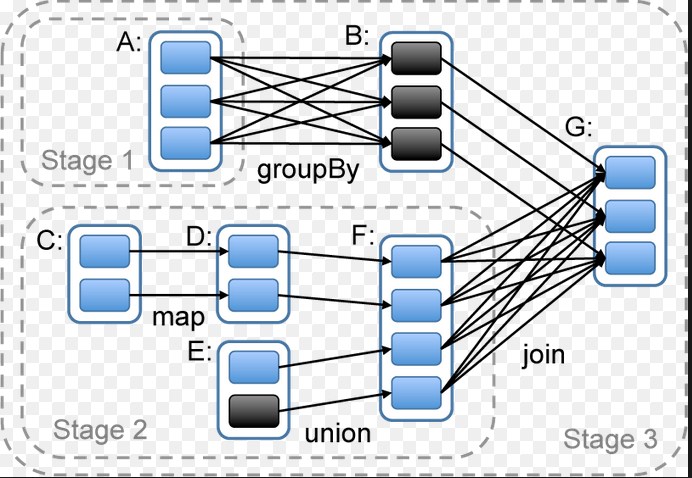
/**
* A stage is a set of independent tasks all computing the same function that need to run as part
* of a Spark job, where all the tasks have the same shuffle dependencies. Each DAG of tasks run
* by the scheduler is split up into stages at the boundaries where shuffle occurs, and then the
* DAGScheduler runs these stages in topological order.
*
* Each Stage can either be a shuffle map stage, in which case its tasks' results are input for
* another stage, or a result stage, in which case its tasks directly compute the action that
* initiated a job (e.g. count(), save(), etc). For shuffle map stages, we also track the nodes
* that each output partition is on.
*
* Each Stage also has a jobId, identifying the job that first submitted the stage. When FIFO
* scheduling is used, this allows Stages from earlier jobs to be computed first or recovered
* faster on failure.
*
* The callSite provides a location in user code which relates to the stage. For a shuffle map
* stage, the callSite gives the user code that created the RDD being shuffled. For a result
* stage, the callSite gives the user code that executes the associated action (e.g. count()).
*
* A single stage can consist of multiple attempts. In that case, the latestInfo field will
* be updated for each attempt.
*
*/
private[spark] class Stage(
val id: Int,
val rdd: RDD[_],
val numTasks: Int,
val shuffleDep: Option[ShuffleDependency[_, _, _]], // Output shuffle if stage is a map stage
val parents: List[Stage],
val jobId: Int,
val callSite: CallSite)
extends Logging {
val isShuffleMap = shuffleDep.isDefined
val numPartitions = rdd.partitions.size
val outputLocs = Array.fill[List[MapStatus]](numPartitions)(Nil)
var numAvailableOutputs = 0
/** Set of jobs that this stage belongs to. */
val jobIds = new HashSet[Int]
/** For stages that are the final (consists of only ResultTasks), link to the ActiveJob. */
var resultOfJob: Option[ActiveJob] = None
var pendingTasks = new HashSet[Task[_]]
def addOutputLoc(partition: Int, status: MapStatus) {
/**
* Result returned by a ShuffleMapTask to a scheduler. Includes the block manager address that the
* task ran on as well as the sizes of outputs for each reducer, for passing on to the reduce tasks.
* The map output sizes are compressed using MapOutputTracker.compressSize.
*/
private[spark] class MapStatus(var location: BlockManagerId, var compressedSizes: Array[Byte])
spark 笔记 8: Stage的更多相关文章
- spark笔记 环境配置
spark笔记 spark简介 saprk 有六个核心组件: SparkCore.SparkSQL.SparkStreaming.StructedStreaming.MLlib,Graphx Spar ...
- Spark 资源调度包 stage 类解析
spark 资源调度包 Stage(阶段) 类解析 Stage 概念 Spark 任务会根据 RDD 之间的依赖关系, 形成一个DAG有向无环图, DAG会被提交给DAGScheduler, DAGS ...
- spark 笔记 15: ShuffleManager,shuffle map两端的stage/task的桥梁
无论是Hadoop还是spark,shuffle操作都是决定其性能的重要因素.在不能减少shuffle的情况下,使用一个好的shuffle管理器也是优化性能的重要手段. ShuffleManager的 ...
- spark 笔记 13: 再看DAGScheduler,stage状态更新流程
当某个task完成后,某个shuffle Stage X可能已完成,那么就可能会一些仅依赖Stage X的Stage现在可以执行了,所以要有响应task完成的状态更新流程. ============= ...
- 大数据学习——spark笔记
变量的定义 val a: Int = 1 var b = 2 方法和函数 区别:函数可以作为参数传递给方法 方法: def test(arg: Int): Int=>Int ={ 方法体 } v ...
- spark 笔记 16: BlockManager
先看一下原理性的文章:http://jerryshao.me/architecture/2013/10/08/spark-storage-module-analysis/ ,http://jerrys ...
- spark 笔记 9: Task/TaskContext
DAGScheduler最终创建了task set,并提交给了taskScheduler.那先得看看task是怎么定义和执行的. Task是execution执行的一个单元. Task: execut ...
- spark 笔记 7: DAGScheduler
在前面的sparkContex和RDD都可以看到,真正的计算工作都是同过调用DAGScheduler的runjob方法来实现的.这是一个很重要的类.在看这个类实现之前,需要对actor模式有一点了解: ...
- spark 笔记 2: Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf ucb关于spark的论文,对spark中核心组件RDD最原始.本质的理解, ...
随机推荐
- html基础知识(总结自www.runoob.com)
HTML属性 属性 描述 class 为html元素定义一个或多个类名(classname)(类名从样式文件引入) id 定义元素的唯一id style 规定元素的行内样式(inline style) ...
- Go项目目录管理
在Go的官网文档How to Write Go Code中,已经介绍了Go的项目目录一般包含以下几个: src 包含项目的源代码文件: pkg 包含编译后生成的包/库文件: bin 包含编译后生成的可 ...
- VirtualBox给CentOS虚拟机挂载磁盘扩大空间
VirtualBox给CentOS虚拟机挂载磁盘扩大空间 楼主,发现虚拟机使用存储空间不够用的情况,需要改虚拟机挂载磁盘,扩容,在网上找了一波资料,于是整合记录操详细作如下: 概要步骤如下: 1.设置 ...
- SAP中MM模块基础数据之Quota Arrangement(配额协议)的解析
有的时候我们的采购部门有这样的需求, 同一颗物料有几个供应商同时供料, 这个时候就涉及到一个问题, 避免出现总是和一家供应商购买物料的情况,我们需求把这些物料按照一定的比列分配给供应商.在SAP系统中 ...
- <现代C++实战30讲>笔记 01 | 堆、栈、RAII:C++里该如何管理资源?
1.堆(heap),动态分配的内存区域,分配之后需手工释放(new, delete, malloc, free) 这种方式需要分配内存,释放内存,因此可能会造成内存泄露,或者内存碎片的问题. 2.栈( ...
- zencart通过产品id 批量添加推荐产品
1.修改 admin/featured.php 查找 pre_add_confirmation 将 pre_add_confirmation 与 break; 之间的代码,用下面的代码替换即可 &l ...
- string::erase
sequence (1) string& erase (size_t pos = 0, size_t len = npos);两个参数都有默认值,传递的唯一参数匹配第一个 character ...
- adb简介
Android 调试桥 (adb) 是一种功能多样的命令行工具,可让您与设备进行通信.adb 命令便于执行各种设备操作(例如安装和调试应用),并提供对 Unix shell(可用来在设备上运行各种命令 ...
- mysql5.7.26部署MHA
前期准备: mysql先部署好GTID主从,然后才部署MHA 1)环境准备(所有节点) #安装依赖包 yum install perl-DBD-MySQL -y #进入安装包存放目录 [root@my ...
- /usr/lib/python2.7/site-packages/requests/__init__.py:91: RequestsDependency
原因:python库中urllib3 (1.22) or chardet (2.2.1) 的版本不兼容 解决如下: [ [root@aaaaaaaaaaaaaaaaaaaa~]# pip uninst ...