大数据笔记(二)——Apache Hadoop的体系结构
一.分布式存储
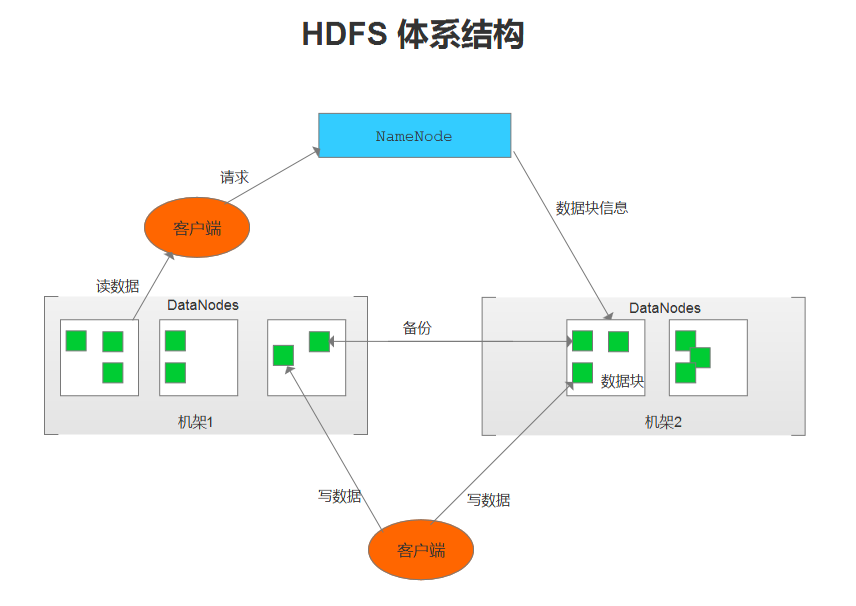
- NameNode(名称节点)
1.维护HDFS文件系统,是HDFS的主节点。
2.接收客户端的请求:上传、下载文件、创建目录等。
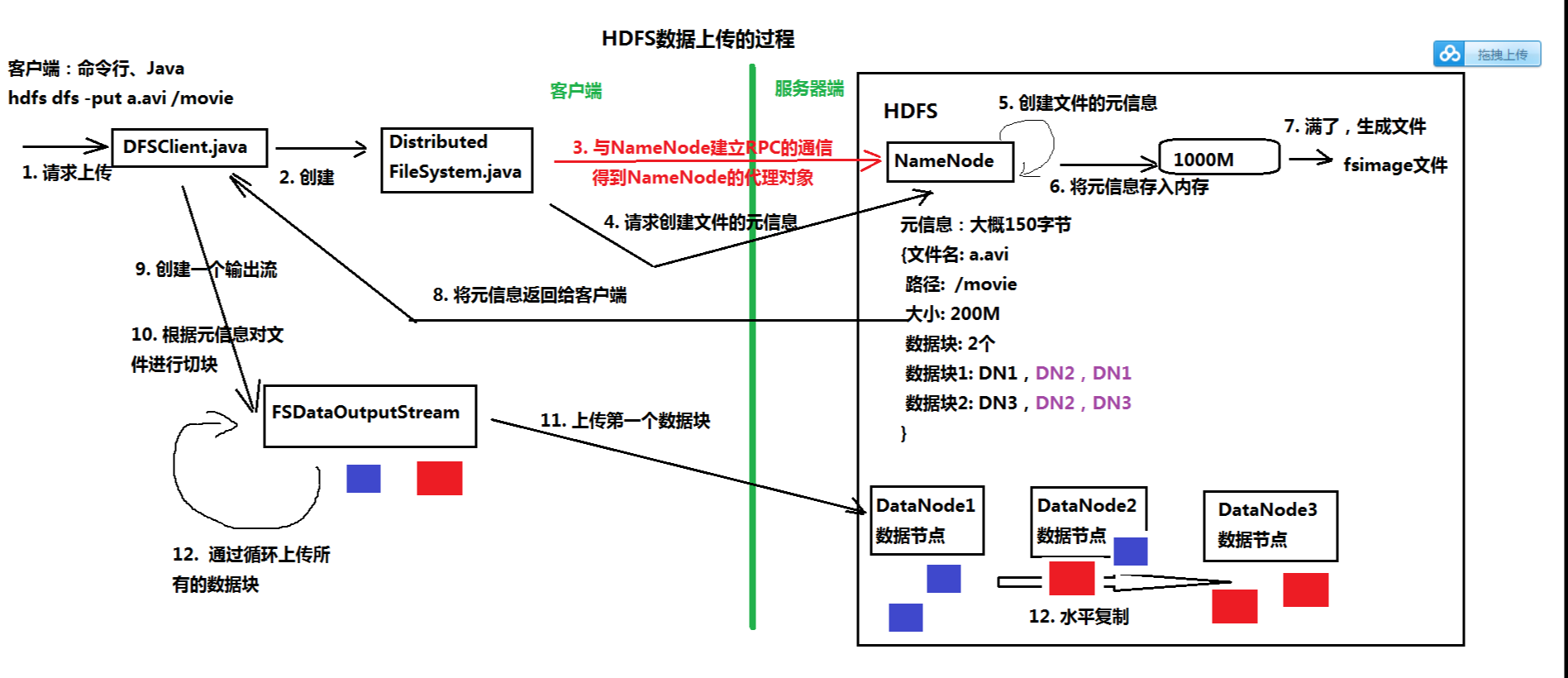
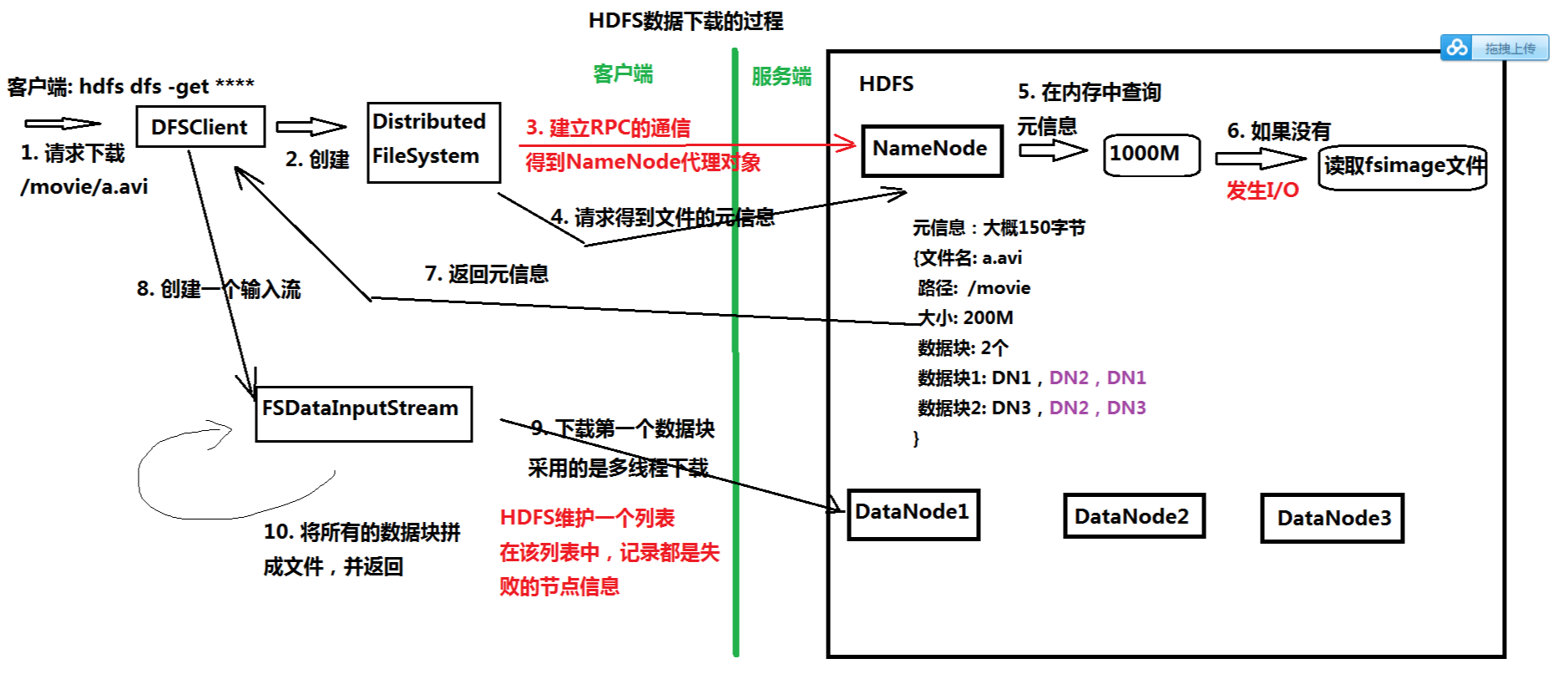
3.记录客户端操作的日志(edits文件),保存了HDFS最新的状态
1)Edits文件保存了自最后一次检查点之后所有针对HDFS文件系统的操作,比如:增加文件、重命名文件、删除目录等
2)保存目录:$HADOOP_HOME/tmp/dfs/name/current
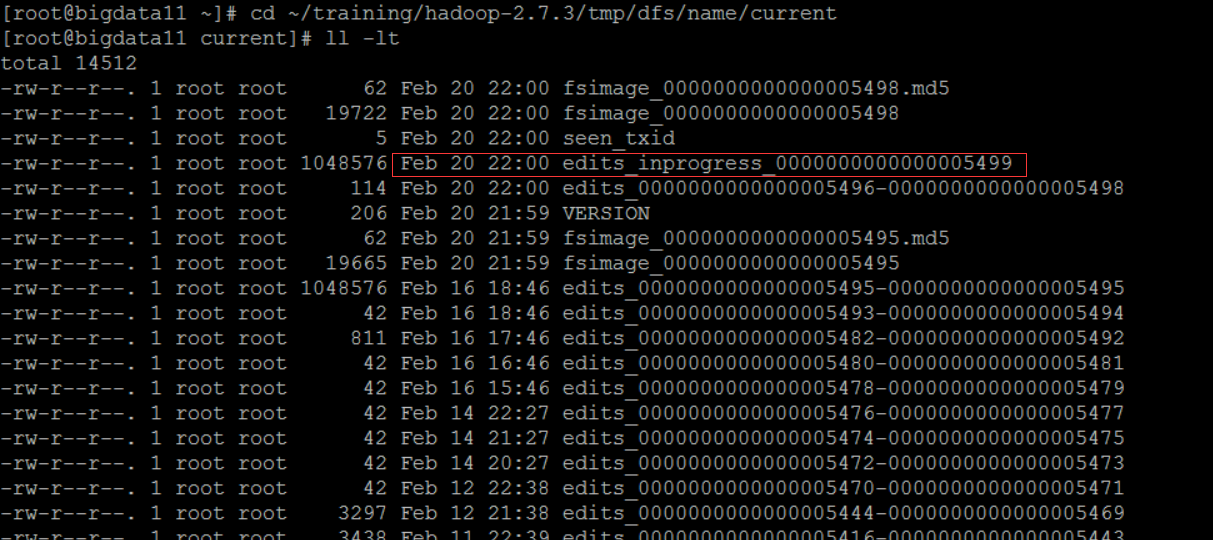
可以使用 hdfs oev -i 命令将日志(二进制)输出为 XML文件
hdfs oev -i edits_inprogress_0000000000000005499 -o ~/temp/log.xml
4.维护文件元信息,将内存中不常用的文件元信息保存在硬盘上(fsimage文件)
1)fsimage是HDFS文件系统存于硬盘中的元数据检查点,里面记录了自最后一次检查点之前HDFS文件系统中所有目录和文件的序列化信息
2)保存目录:edits
3)可以使用 hdfs oev -i 命令将日志(二进制)输出为 XML文件
- DataNode(数据节点)
1.以数据块为单位,保存数据
1)Hadoop1.0的数据块大小:64M
2)Hadoop2.0的数据库大小:128M
2.在全分布模式下,至少两个DataNode节点
3.数据保存的目录:由 hadoop.tmp.dir 参数指定
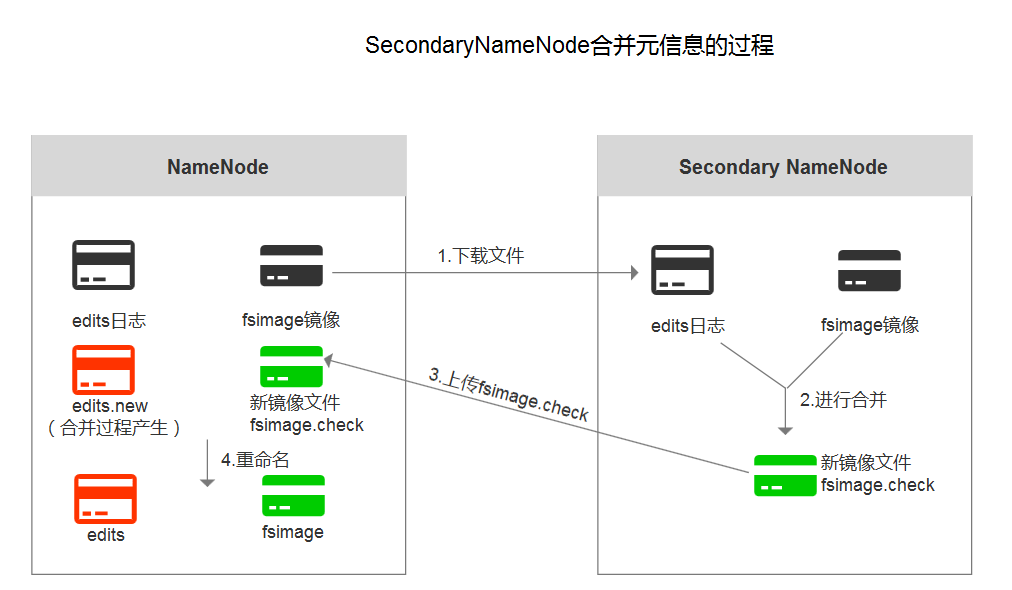
- Secondary NameNode(第二名称节点)
1.主要作用:合并日志
2.合并时机:HDFS发出检查点的时候
3.日志合并过程:
- HDFS存在的问题
1)NameNode单点故障问题
解决方案:Hadoop2.0中,使用Zookeeper实现NameNode的HA功能
2)NameNode压力过大,且内存受限,影响系统扩展性
解决方案:Hadoop2.0中,使用NameNode联盟实现水平扩展
二.YARN:分布式计算(MapReduce)
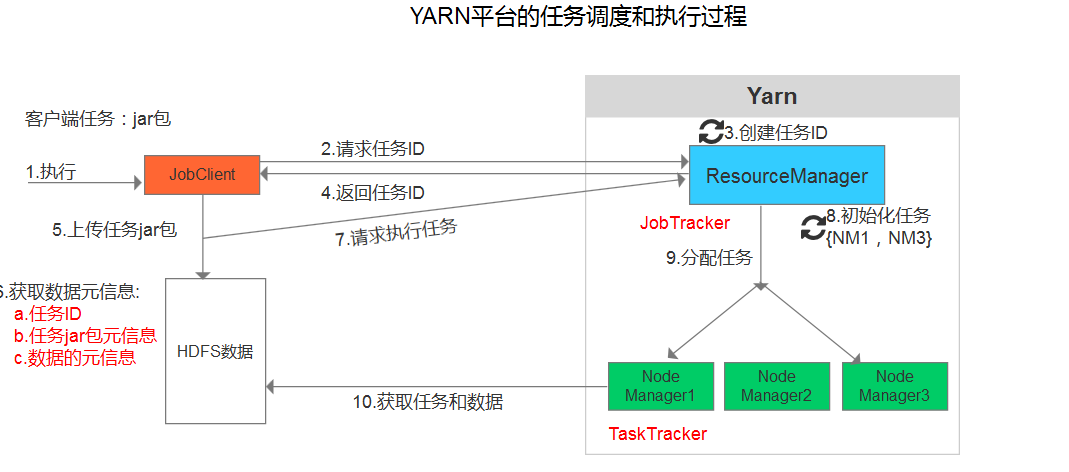
- ResourceManager(资源管理器)
1.接收客户端的请求,执行任务
2.分配资源
3.分配任务
- NodeManager(节点管理器:运行任务 MapReduce)
从 DataNode上获取数据,执行任务
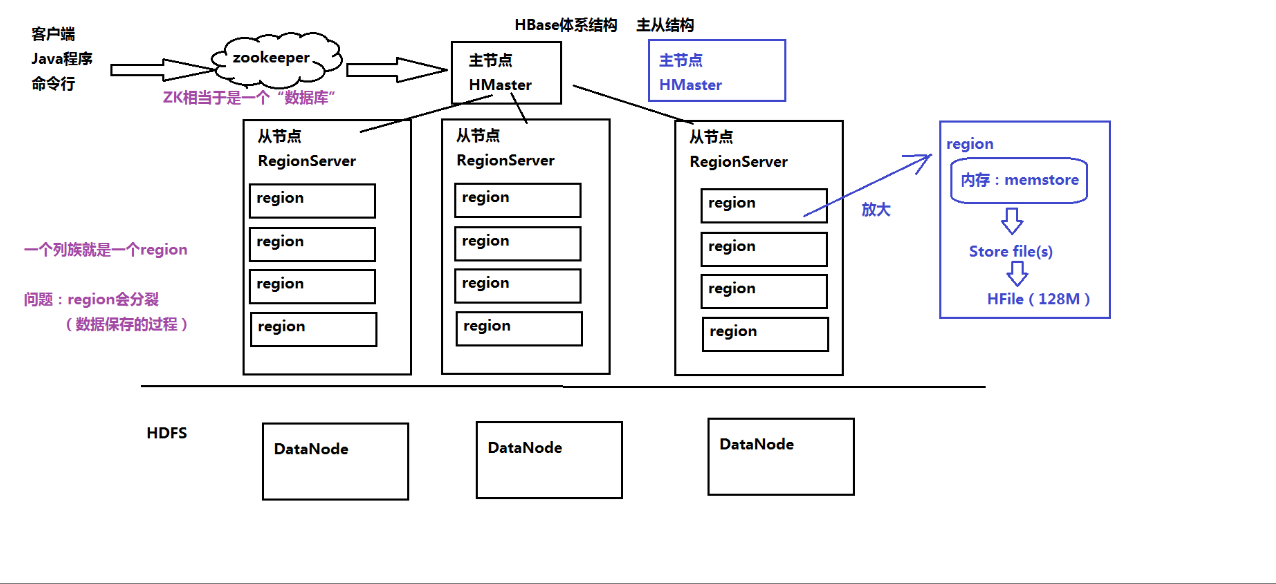
三.HBase的体系结构
大数据笔记(二)——Apache Hadoop的体系结构的更多相关文章
- 大数据笔记13:Hadoop安装之Hadoop的配置安装
1.准备Linux环境 1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip ...
- 大数据软件安装之Hadoop(Apache)(数据存储及计算)
大数据软件安装之Hadoop(Apache)(数据存储及计算) 一.生产环境准备 1.修改主机名 vim /etc/sysconfig/network 2.修改静态ip vim /etc/udev/r ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 玩转大数据系列之Apache Pig高级技能之函数编程(六)
原创不易,转载请务必注明,原创地址,谢谢配合! http://qindongliang.iteye.com/ Pig系列的学习文档,希望对大家有用,感谢关注散仙! Apache Pig的前世今生 Ap ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 阿里巴巴飞天大数据架构体系与Hadoop生态系统
很多人问阿里的飞天大数据平台.云梯2.MaxCompute.实时计算到底是什么,和自建Hadoop平台有什么区别. 先说Hadoop 什么是Hadoop? Hadoop是一个开源.高可靠.可扩展的分布 ...
- 决战大数据之二:CentOS 7 最新JDK 8安装
决战大数据之二:CentOS 7 最新JDK 8安装 [TOC] 修改hostname # hostnamectl set-hostname node1 --static # reboot now 重 ...
- 大数据实时计算工程师/Hadoop工程师/数据分析师职业路线图
http://edu.51cto.com/roadmap/view/id-29.html http://my.oschina.net/infiniteSpace/blog/308401 大数据实时计算 ...
随机推荐
- java基础笔记(7)
Socket编程 通信基础:ip地址(位置).协议(语言).端口(软件程序): java提供网络功能的四大类: InetAddress没有构造函数,不够里面有一些方法是可以返回实例,如: InetAd ...
- RabbitMq学习3-工作队列(Work queues)
工作队列(又称:任务队列——Task Queues)是为了避免等待一些占用大量资源.时间的操作.当我们把任务(Task)当作消息发送到队列中,一个运行在后台的工作者(worker)进程就会取出任务然后 ...
- Composer 的自动加载机制
Composer 的自动加载机制 Composer 提供了四种自动加载方式,分别是 PSR-0.PSR-4.生成 classmap 以及之间包含 files. PSR-0 方式 PSR-0 方式要求目 ...
- 剑指offer-二叉搜索树的后序遍历序列-python
题目描述 输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果.如果是则输出Yes,否则输出No.假设输入的数组的任意两个数字都互不相同. 递归法: 先判断左子树是否存在 再判断右子树是否存 ...
- Animator通过按键切换动画不及时,动画延时切换问题
再unity3D版本为Unity 5.2.1f1 (64-bit),再设置动画切换时有一个Has Exit Time属性,由于勾上了这个的原因
- 如何在github上部署自己的前端项目
很多时候我们想需要一个地址就可以访问自己的前端作品, 但是注册一个服务器和域名是需要花钱,很多小伙伴都不愿意, 其实这种前端静态页面github就可以帮我们预览其效果,而且只要在有网的情况下都可以访问 ...
- linux 深入应用 NFS
以下实验大家用主机名来区分服务器端和客户端, 服务器端为 NFS_Server ip-192.168.1.4: 客户端为 NFS_Client ip-192.168.1.5: 实例一 将/tmp 分享 ...
- 202-基于TI DSP TMS320C6678、Xilinx K7 FPGA XC7K325T的高速数据处理核心板
该DSP+FPGA高速信号采集处理板由我公司自主研发,包含一片TI DSP TMS320C6678和一片Xilinx FPGA K7 XC72K325T-1ffg900.包含1个千兆网口,1个FMC ...
- linux用户管理(useradd、userdel、usermod、groupadd、groupdel、chage、passwd、chpasswd)
一.用户账户配置文件介绍 /etc/passwd 用户账户信息文件/etc/shadow 用户账户密码文件/etc/group 用户组信息文件/etc/gshadow 用户组密码所在文件(基本废弃)/ ...
- Java并发——原子变量和原子操作
很多情况下我们只是需要一个简单的.高效的.线程安全的递增递减方案.注意,这里有三个条件:简单,意味着程序员尽可能少的操作底层或者实现起来要比较容易:高效意味着耗用资源要少,程序处理速度要快:线程安全也 ...