机器学习 coursera_ML
在开始看之前,浏览器一直出现缓冲问题,是配置文件设置的不对,最后搞定,高兴!解决方法如下:
1.到C:\Windows\System32\drivers\etc下找到host文件,并以文本方式打开,
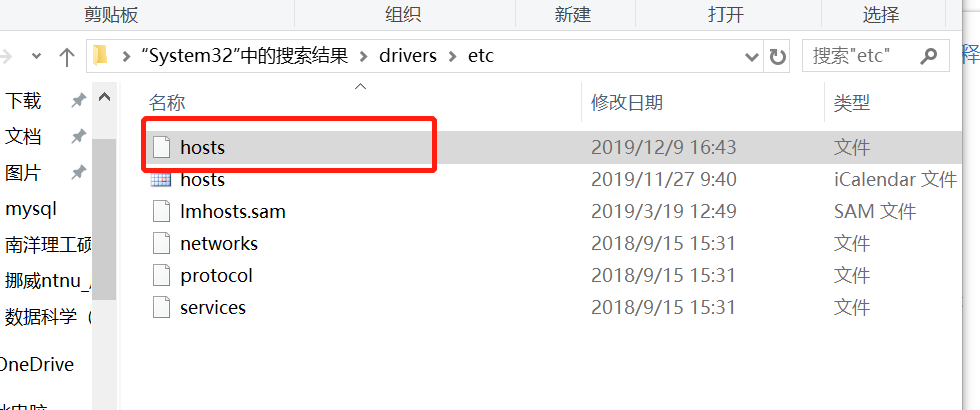
添加如下信息到hosts文件中:
52.84.246.90 d3c33hcgiwev3.cloudfront.net
52.84.246.252 d3c33hcgiwev3.cloudfront.net
52.84.246.144 d3c33hcgiwev3.cloudfront.net
52.84.246.72 d3c33hcgiwev3.cloudfront.net
52.84.246.106 d3c33hcgiwev3.cloudfront.net
52.84.246.135 d3c33hcgiwev3.cloudfront.net
52.84.246.114 d3c33hcgiwev3.cloudfront.net
52.84.246.90 d3c33hcgiwev3.cloudfront.net
52.84.246.227 d3c33hcgiwev3.cloudfront.net
2.刷新浏览器dns地址,ipconfig/flushdns,good! 这里贴出machine-learning of courase的address, maybe friends can learn a lot.
week01(不会django,只能这样)
chapter 00 introduction
structure and usage of machine learning

the definition of ML
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E
supervised learning
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
there are two types of supervised learning, that are regression and classification. one sign is whether the relationship of input and output is continuous.
unsupervised learning
there are no labels for the unsupervised learning, and we hope that the computer can help us to labels some databets.
chapter 01 model and cost function
topic1 模型导入:
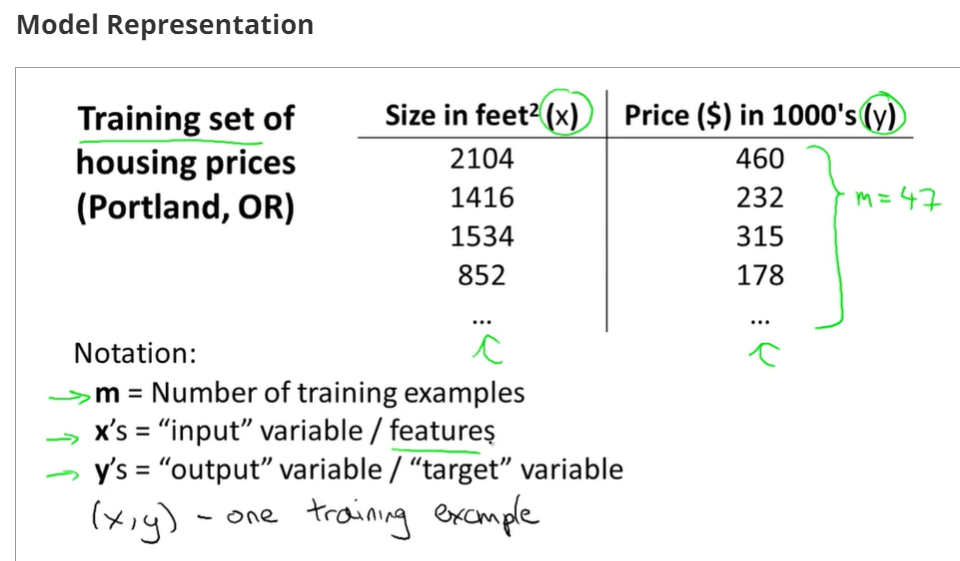
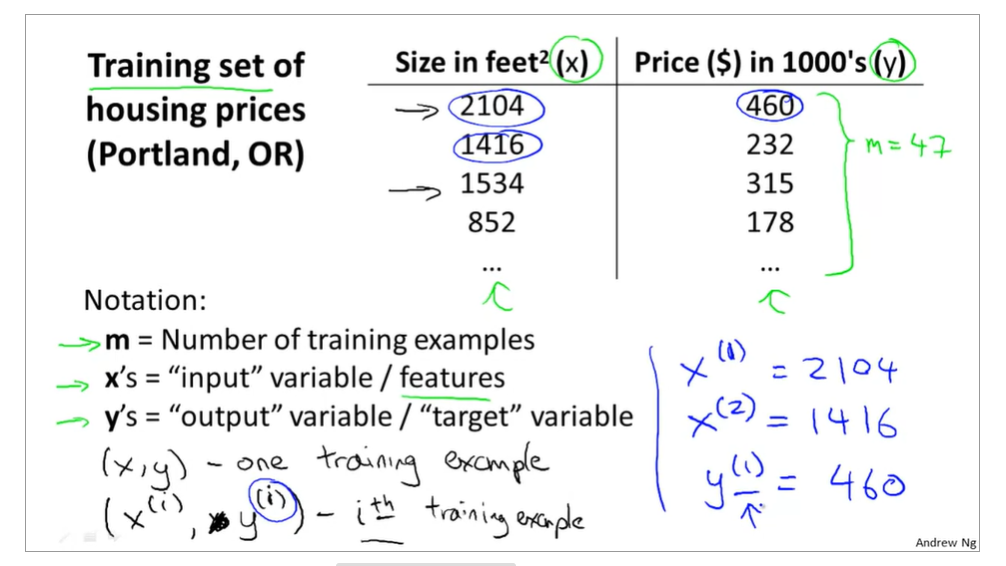
training examples(x(i),y(i)),i=1,2,3...,m,m is trainging set;
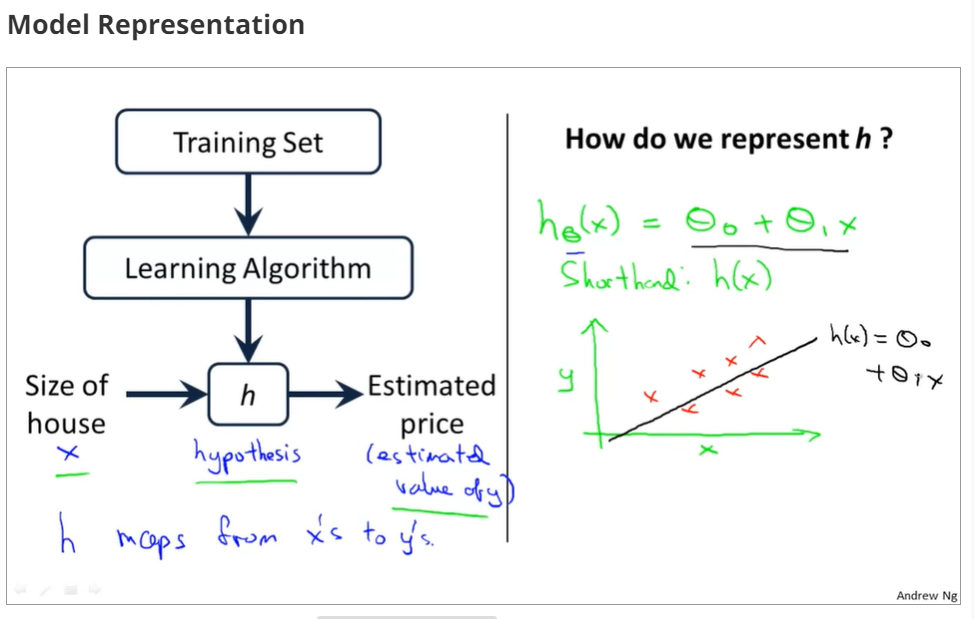
h(x) si a 'good' predictor for the goal of housing price of y,and h(x) here is called hypothesis;
if we are trying to predict the problem continuously, such as the housing price, we call the learning problem a regression problem.
topic2 some figures of linear regression
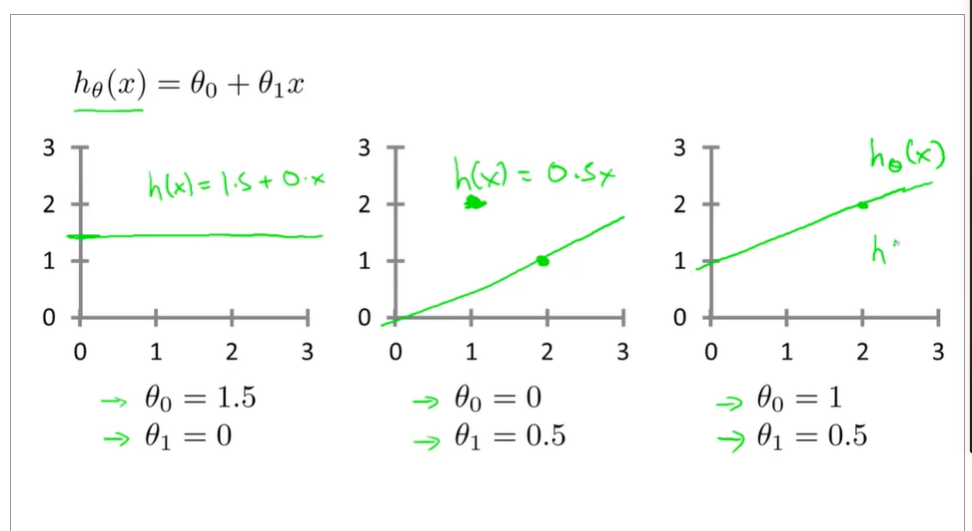
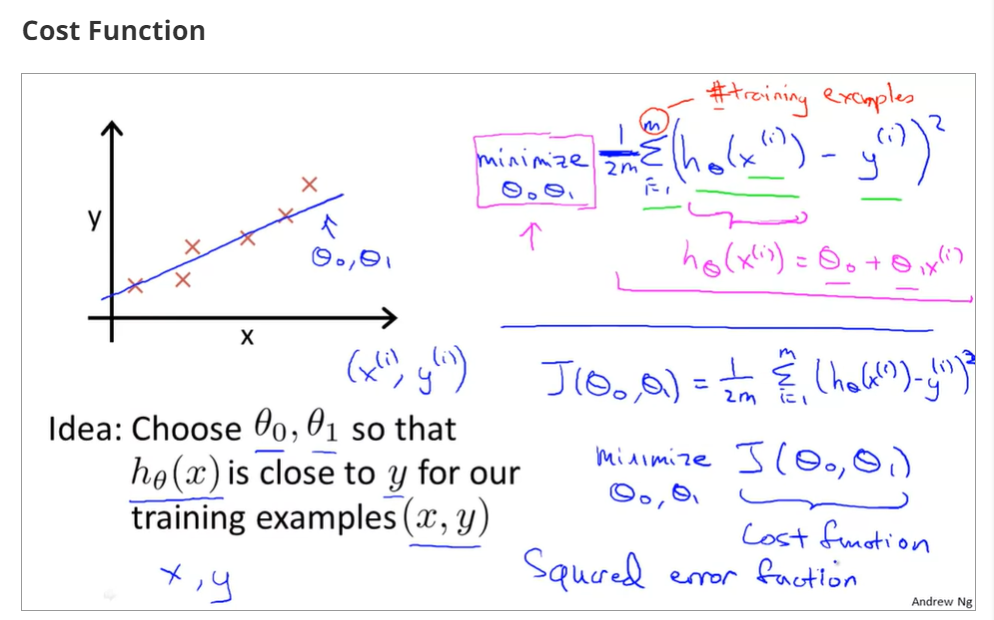
cost function
choose a suitable hθ(x) for making the error with y to the minimum
make a cost function
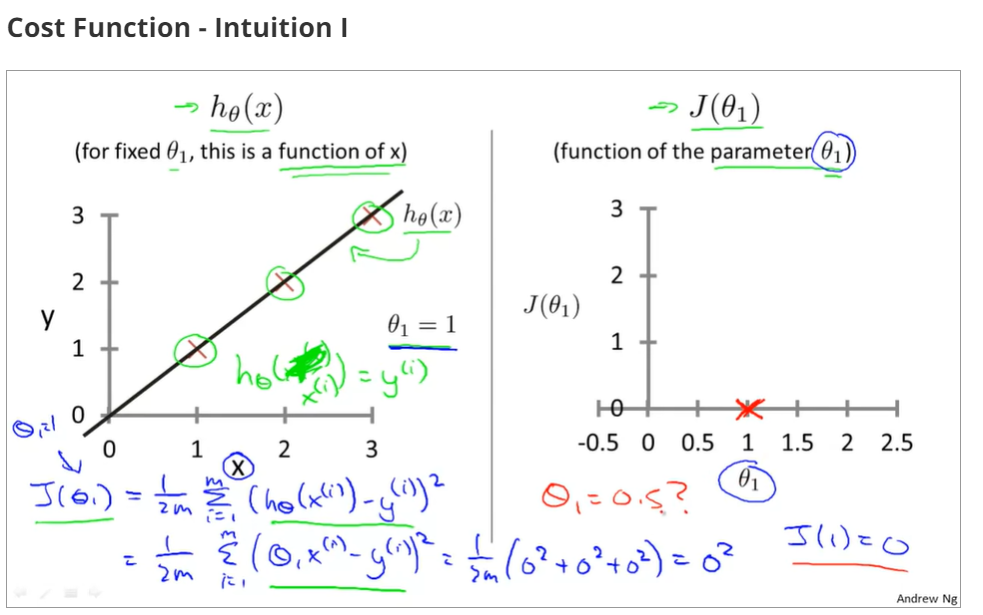
topic3 cost function - intuition I
when θ0=0 and θ1=1,the cost function and function of the parameter is as below
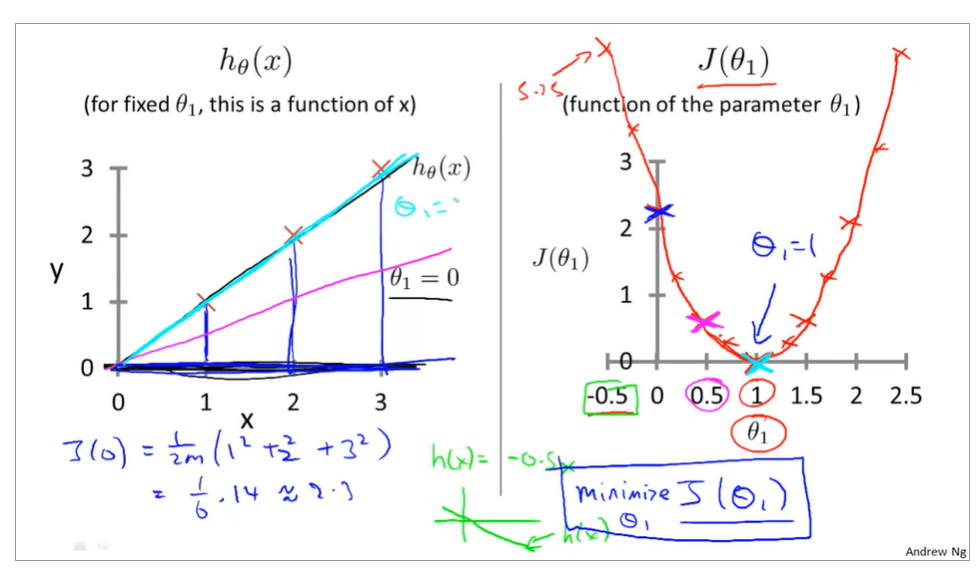
the relationship between the function of hypothesis function and the cost function, that is to say, there are different values of cost function that is corresponding to the the function of hypothesis
topic 4 Intuition II
now, it is fixed values of θ0,θ1,
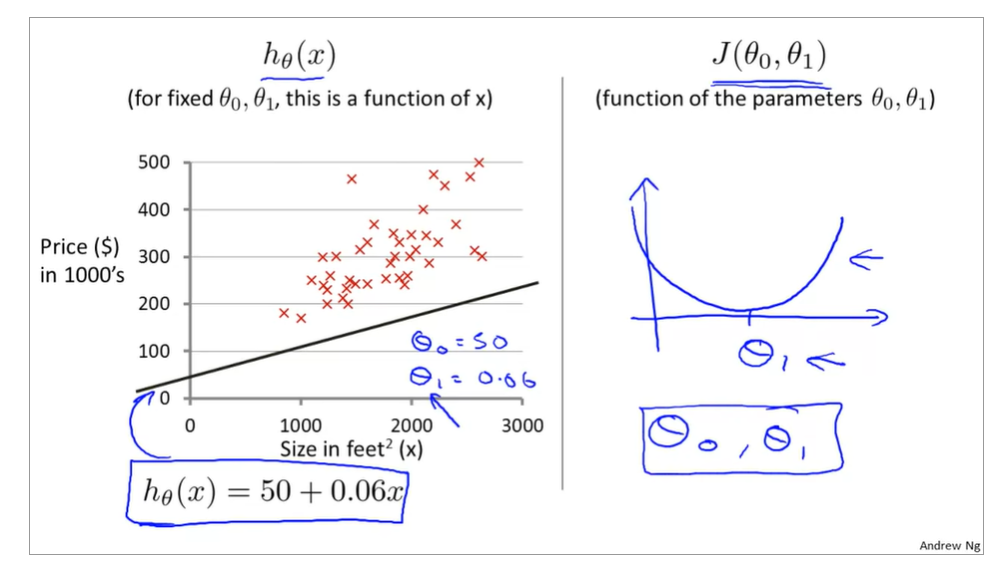
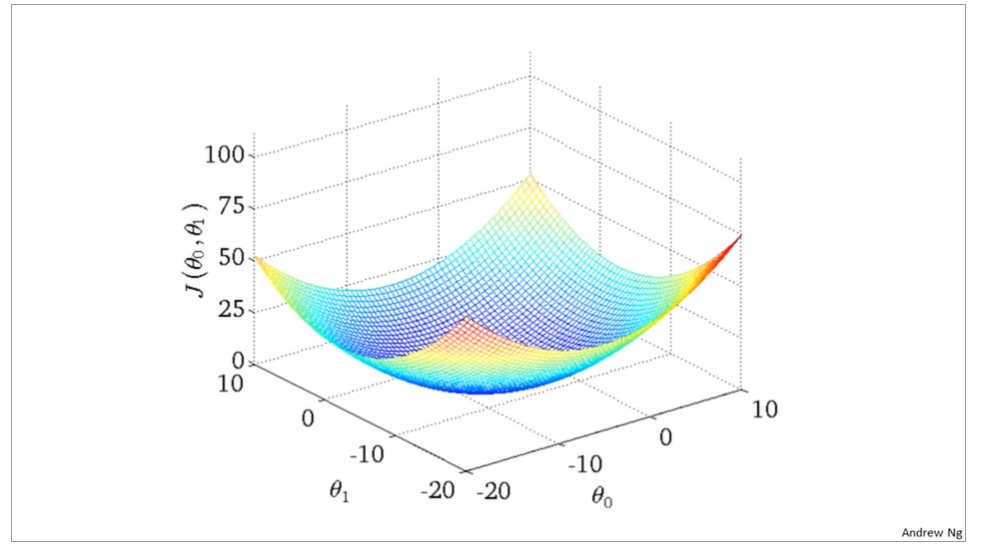
the curve face to the ground is the height of the J(θ0,θ1),we can see the description in the picture as below
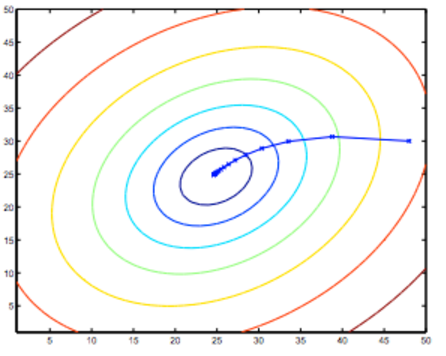
it is also called contour plots or contour figures to the left graph as below, and we can get the minimal result as much as possible,

topic 5 algorithm of function of hypothesis to minimize the cost function of J
the best algorithm is to find a function to make the value of cost function which is a second-order function to the minimum, and then the inner circle point is what we need get. It is also corresonding to the two values θ0 and θ1.

chapter 02 parameter learning
topic 1 gradient descent
introduction

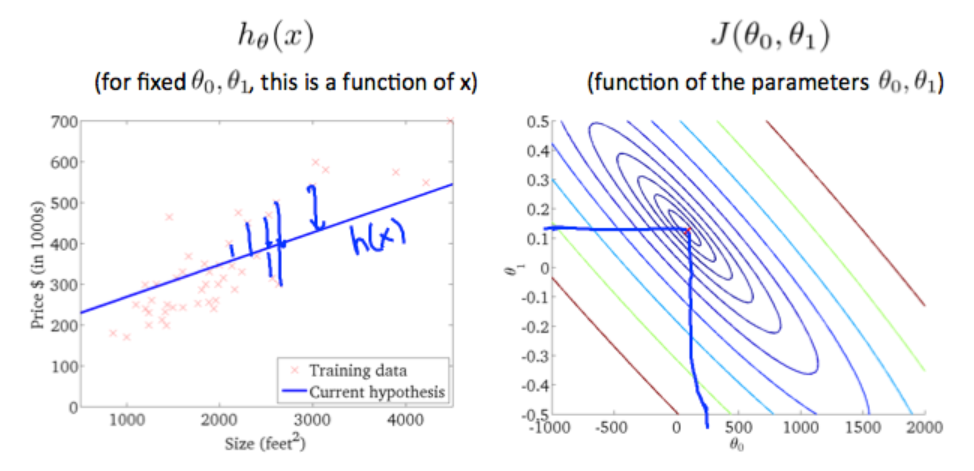
the theory of gradient descent, like a model going down the hill, it bases on the hypothesis function(theta0 and theta1), and the cost function J is bases on the hypothesis function graphed below.
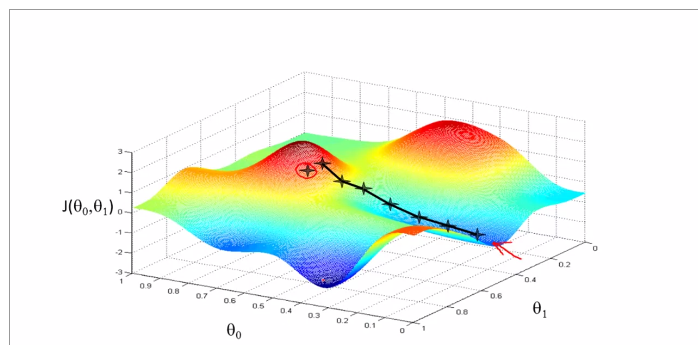
the tangential line to a cost function is the black line which use athe derivative.
alpha is a parameter, which is called learning rate. A small alpha would result in a small step and a larger alpha would result in a larger step. the direction is taken by the partial derivative of J(θ0,θ1)

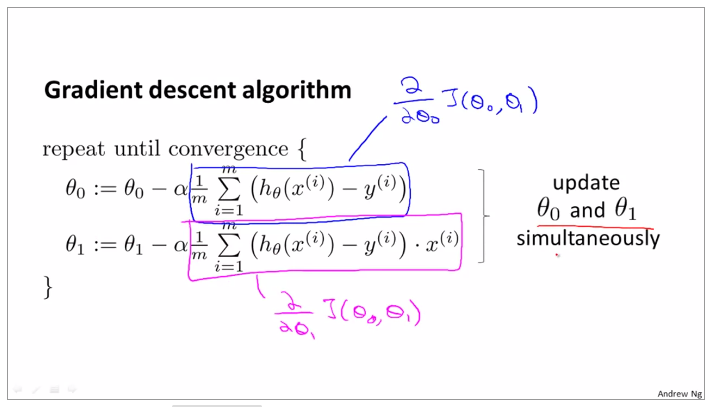
topic 2 OUTLINE OF THE GRADIENT DESCENT ALGORITHM
theta 0 and theta1 need update together, otherwise they will be replaced after operation, such as the line listed for theta 0, and next it is incorrect when replace the value of theta0 in the equation of temp1

topic 3 Gradient Descent Intuition

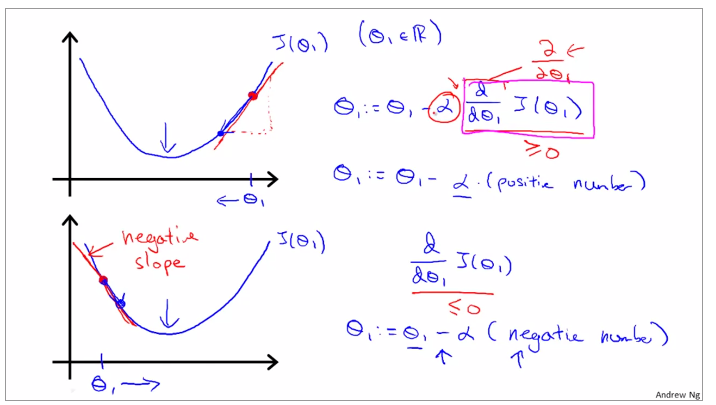
if alpha is to small, gradient descent can be slow; and if alpha is to large, gradient descent can overshoot the minimum. may not be converge or even diverge.
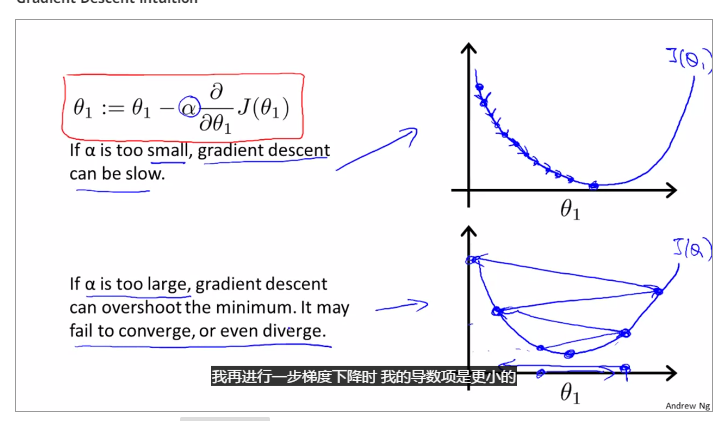
gradient descent can converge to a local minimum, whenever a learning rate alpha
gradient descent will automatically take smaller steps to make the result converge.
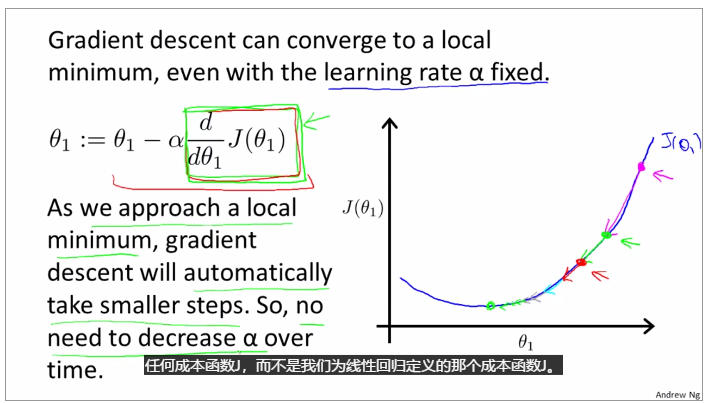
Use gradient descent to assure the change of theta, when the gradient is positive, the gradient descent gradually decrease and when the gradient is negative, the gradient descent gradually increase.
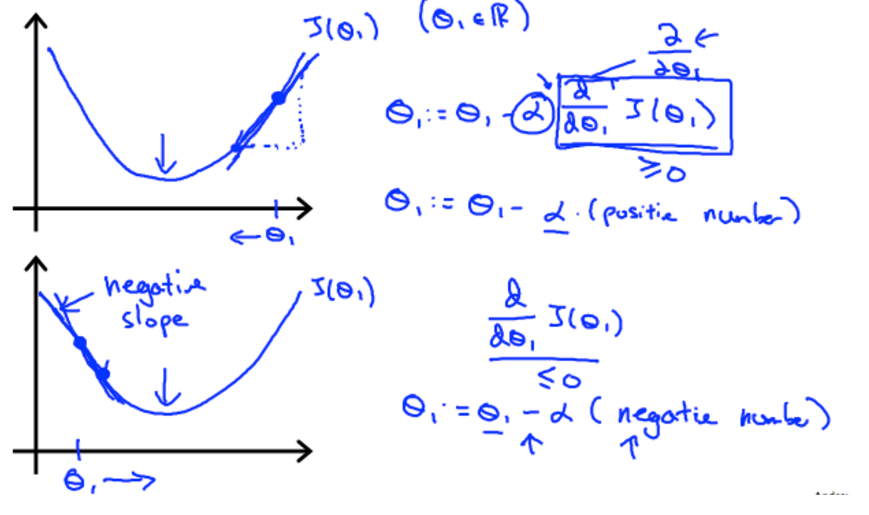
gradient for linear regression
partial derevative for theta0 and theta1

convex function and bowl shape
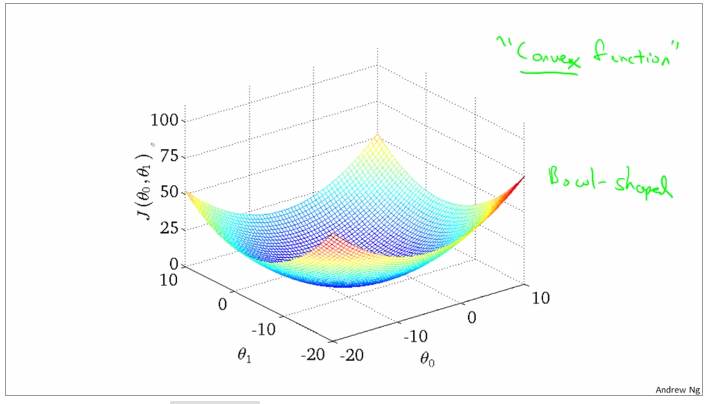
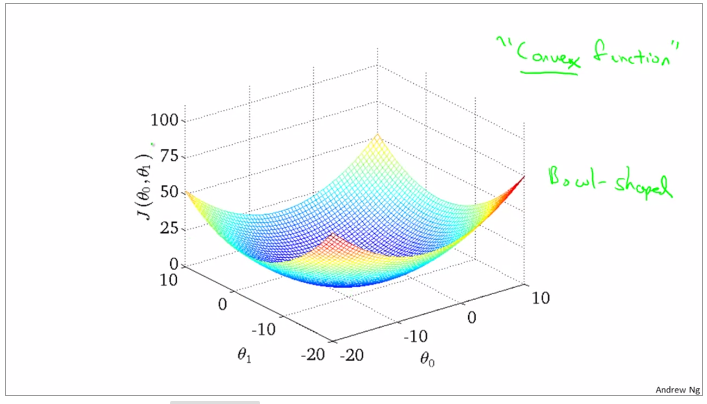

Batch gradient descent: every make full use of the training examples
gradient descent can be subceptible to local minima in general. gradient descent always converges to the global minimum.
review
vector is a matric which is nx1 matrix

R refers to the set of scalar real numbers.
Rn refers to the set of n-dimensional vectors of real numbers.
topic 4 Addition and scalar Multiplication
The knowledge here is similar with linear algebra, possibly there is no necessity to learn it.
topic 5 Matrix vector multiplication
The knowledge here is similar with linear algebra, possibly there is no necessity to learn it.
topic 6 Matrix Multiplication Properties
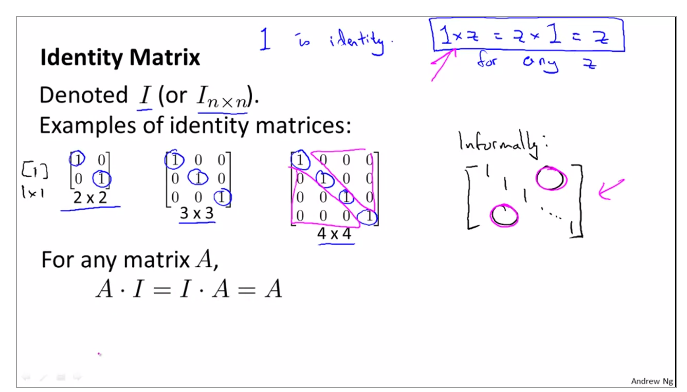
identity matrix
topic 7 review and review Inverse and Transpose of matrix
through computing, Matrix A multiply inverse A is not equal inverse A multiply Matrix A

week02
topic 1 Multiple features(variables)
compute the value xj(i) = value of feature j in ith training sets
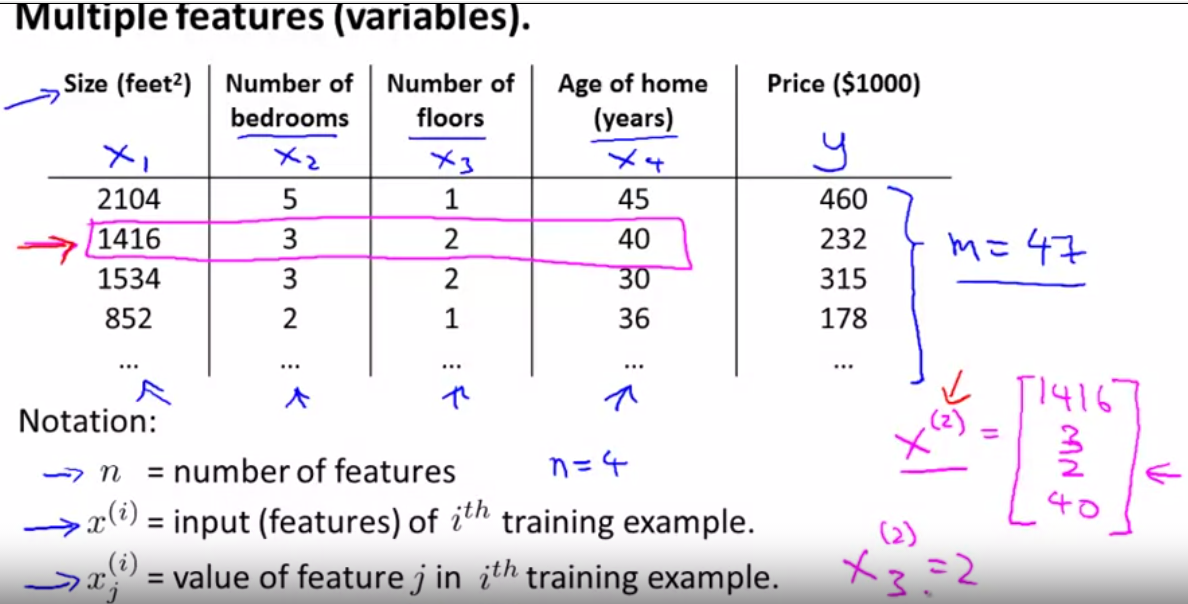
x3(2), x(2) means the line 2 and the x3 means the third number, that is to say it is 2.
put the hypothesis to the n order, that is multivariable form of the hypothesis function

to define the function hθ(x) of the n order, we need to make sense its meaning, there is an example to explain.

topic 2 gradient descent for multiple variables

topic 3 gradient descent in practice 1 - feature scaling
mean normalization

appropriate number of mean normalization can make the gradient descent more quick.
use xi := (xi - ui) / si,
where
is the average of all the values for feature (i) and si is the range of values (max - min), or si is the standard deviation.

is the average of all the values for feature (i) and si is the range of values (max - min), or si is the standard deviation.
topic 4 Graident descent in practice ii - learning rate
how to adjust the parameter of learning rate, it is also a type a debug, so may be use a 3 to multiply the original learning rate to adjust the value to the optimal.

If J(θ) ever increases, then you probably need to decrease α.
when the curve is fluctuent, it needs a smaller learning rate.

To summarize:
If α is too small: slow convergence.
If α is too large: may not decrease on every iteration and thus may not converge.
------------恢复内容结束------------
在开始看之前,浏览器一直出现缓冲问题,是配置文件设置的不对,最后搞定,高兴!解决方法如下:
1.到C:\Windows\System32\drivers\etc下找到host文件,并以文本方式打开,
添加如下信息到hosts文件中:
52.84.246.90 d3c33hcgiwev3.cloudfront.net
52.84.246.252 d3c33hcgiwev3.cloudfront.net
52.84.246.144 d3c33hcgiwev3.cloudfront.net
52.84.246.72 d3c33hcgiwev3.cloudfront.net
52.84.246.106 d3c33hcgiwev3.cloudfront.net
52.84.246.135 d3c33hcgiwev3.cloudfront.net
52.84.246.114 d3c33hcgiwev3.cloudfront.net
52.84.246.90 d3c33hcgiwev3.cloudfront.net
52.84.246.227 d3c33hcgiwev3.cloudfront.net
2.刷新浏览器dns地址,ipconfig/flushdns,good! 这里贴出machine-learning of courase的address, maybe friends can learn a lot.
week01(不会django,只能这样)
chapter 00 introduction
structure and usage of machine learning
the definition of ML
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E
supervised learning
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
there are two types of supervised learning, that are regression and classification. one sign is whether the relationship of input and output is continuous.
unsupervised learning
there are no labels for the unsupervised learning, and we hope that the computer can help us to labels some databets.
chapter 01 model and cost function
topic1 模型导入:
training examples(x(i),y(i)),i=1,2,3...,m,m is trainging set;
h(x) si a 'good' predictor for the goal of housing price of y,and h(x) here is called hypothesis;
if we are trying to predict the problem continuously, such as the housing price, we call the learning problem a regression problem.
topic2 some figures of linear regression
cost function
choose a suitable hθ(x) for making the error with y to the minimum
make a cost function
topic3 cost function - intuition I
when θ0=0 and θ1=1,the cost function and function of the parameter is as below
the relationship between the function of hypothesis function and the cost function, that is to say, there are different values of cost function that is corresponding to the the function of hypothesis
topic 4 Intuition II
now, it is fixed values of θ0,θ1,
the curve face to the ground is the height of the J(θ0,θ1),we can see the description in the picture as below
it is also called contour plots or contour figures to the left graph as below, and we can get the minimal result as much as possible,
topic 5 algorithm of function of hypothesis to minimize the cost function of J
the best algorithm is to find a function to make the value of cost function which is a second-order function to the minimum, and then the inner circle point is what we need get. It is also corresonding to the two values θ0 and θ1.
chapter 02 parameter learning
topic 1 gradient descent
introduction
the theory of gradient descent, like a model going down the hill, it bases on the hypothesis function(theta0 and theta1), and the cost function J is bases on the hypothesis function graphed below.
the tangential line to a cost function is the black line which use athe derivative.
alpha is a parameter, which is called learning rate. A small alpha would result in a small step and a larger alpha would result in a larger step. the direction is taken by the partial derivative of J(θ0,θ1)
topic 2 OUTLINE OF THE GRADIENT DESCENT ALGORITHM
theta 0 and theta1 need update together, otherwise they will be replaced after operation, such as the line listed for theta 0, and next it is incorrect when replace the value of theta0 in the equation of temp1
topic 3 Gradient Descent Intuition
if alpha is to small, gradient descent can be slow; and if alpha is to large, gradient descent can overshoot the minimum. may not be converge or even diverge.
gradient descent can converge to a local minimum, whenever a learning rate alpha
gradient descent will automatically take smaller steps to make the result converge.
Use gradient descent to assure the change of theta, when the gradient is positive, the gradient descent gradually decrease and when the gradient is negative, the gradient descent gradually increase.
gradient for linear regression
partial derevative for theta0 and theta1
convex function and bowl shape
Batch gradient descent: every make full use of the training examples
gradient descent can be subceptible to local minima in general. gradient descent always converges to the global minimum.
review
vector is a matric which is nx1 matrix
R refers to the set of scalar real numbers.
Rn refers to the set of n-dimensional vectors of real numbers.
topic 4 Addition and scalar Multiplication
The knowledge here is similar with linear algebra, possibly there is no necessity to learn it.
topic 5 Matrix vector multiplication
The knowledge here is similar with linear algebra, possibly there is no necessity to learn it.
topic 6 Matrix Multiplication Properties
identity matrix
topic 7 review and review Inverse and Transpose of matrix
through computing, Matrix A multiply inverse A is not equal inverse A multiply Matrix A
week02
topic 1 Multiple features(variables)
compute the value xj(i) = value of feature j in ith training sets
x3(2), x(2) means the line 2 and the x3 means the third number, that is to say it is 2.
put the hypothesis to the n order, that is multivariable form of the hypothesis function
to define the function hθ(x) of the n order, we need to make sense its meaning, there is an example to explain.
topic 2 gradient descent for multiple variables
topic 3 gradient descent in practice 1 - feature scaling
mean normalization
appropriate number of mean normalization can make the gradient descent more quick.
use xi := (xi - ui) / si,where
μi is the average of all the values for feature (i) and s_isi is the range of values (max - min), or s_isi is the standard deviation.
μi is the average of all the values for feature (i) and s_isi is the range of values (max - min), or s_isi is the standard deviation.
------------恢复内容结束------------
------------恢复内容开始------------
在开始看之前,浏览器一直出现缓冲问题,是配置文件设置的不对,最后搞定,高兴!解决方法如下:
1.到C:\Windows\System32\drivers\etc下找到host文件,并以文本方式打开,
添加如下信息到hosts文件中:
52.84.246.90 d3c33hcgiwev3.cloudfront.net
52.84.246.252 d3c33hcgiwev3.cloudfront.net
52.84.246.144 d3c33hcgiwev3.cloudfront.net
52.84.246.72 d3c33hcgiwev3.cloudfront.net
52.84.246.106 d3c33hcgiwev3.cloudfront.net
52.84.246.135 d3c33hcgiwev3.cloudfront.net
52.84.246.114 d3c33hcgiwev3.cloudfront.net
52.84.246.90 d3c33hcgiwev3.cloudfront.net
52.84.246.227 d3c33hcgiwev3.cloudfront.net
2.刷新浏览器dns地址,ipconfig/flushdns,good! 这里贴出machine-learning of courase的address, maybe friends can learn a lot.
week01(不会django,只能这样)
chapter 00 introduction
structure and usage of machine learning
the definition of ML
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E
supervised learning
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
there are two types of supervised learning, that are regression and classification. one sign is whether the relationship of input and output is continuous.
unsupervised learning
there are no labels for the unsupervised learning, and we hope that the computer can help us to labels some databets.
chapter 01 model and cost function
topic1 模型导入:
training examples(x(i),y(i)),i=1,2,3...,m,m is trainging set;
h(x) si a 'good' predictor for the goal of housing price of y,and h(x) here is called hypothesis;
if we are trying to predict the problem continuously, such as the housing price, we call the learning problem a regression problem.
topic2 some figures of linear regression
cost function
choose a suitable hθ(x) for making the error with y to the minimum
make a cost function
topic3 cost function - intuition I
when θ0=0 and θ1=1,the cost function and function of the parameter is as below
the relationship between the function of hypothesis function and the cost function, that is to say, there are different values of cost function that is corresponding to the the function of hypothesis
topic 4 Intuition II
now, it is fixed values of θ0,θ1,
the curve face to the ground is the height of the J(θ0,θ1),we can see the description in the picture as below
it is also called contour plots or contour figures to the left graph as below, and we can get the minimal result as much as possible,
topic 5 algorithm of function of hypothesis to minimize the cost function of J
the best algorithm is to find a function to make the value of cost function which is a second-order function to the minimum, and then the inner circle point is what we need get. It is also corresonding to the two values θ0 and θ1.
chapter 02 parameter learning
topic 1 gradient descent
introduction
the theory of gradient descent, like a model going down the hill, it bases on the hypothesis function(theta0 and theta1), and the cost function J is bases on the hypothesis function graphed below.
the tangential line to a cost function is the black line which use athe derivative.
alpha is a parameter, which is called learning rate. A small alpha would result in a small step and a larger alpha would result in a larger step. the direction is taken by the partial derivative of J(θ0,θ1)
topic 2 OUTLINE OF THE GRADIENT DESCENT ALGORITHM
theta 0 and theta1 need update together, otherwise they will be replaced after operation, such as the line listed for theta 0, and next it is incorrect when replace the value of theta0 in the equation of temp1
topic 3 Gradient Descent Intuition
if alpha is to small, gradient descent can be slow; and if alpha is to large, gradient descent can overshoot the minimum. may not be converge or even diverge.
gradient descent can converge to a local minimum, whenever a learning rate alpha
gradient descent will automatically take smaller steps to make the result converge.
Use gradient descent to assure the change of theta, when the gradient is positive, the gradient descent gradually decrease and when the gradient is negative, the gradient descent gradually increase.
gradient for linear regression
partial derevative for theta0 and theta1
convex function and bowl shape
Batch gradient descent: every make full use of the training examples
gradient descent can be subceptible to local minima in general. gradient descent always converges to the global minimum.
review
vector is a matric which is nx1 matrix
R refers to the set of scalar real numbers.
Rn refers to the set of n-dimensional vectors of real numbers.
topic 4 Addition and scalar Multiplication
The knowledge here is similar with linear algebra, possibly there is no necessity to learn it.
topic 5 Matrix vector multiplication
The knowledge here is similar with linear algebra, possibly there is no necessity to learn it.
topic 6 Matrix Multiplication Properties
identity matrix
topic 7 review and review Inverse and Transpose of matrix
through computing, Matrix A multiply inverse A is not equal inverse A multiply Matrix A
week02
topic 1 Multiple features(variables)
compute the value xj(i) = value of feature j in ith training sets
x3(2), x(2) means the line 2 and the x3 means the third number, that is to say it is 2.
put the hypothesis to the n order, that is multivariable form of the hypothesis function
to define the function hθ(x) of the n order, we need to make sense its meaning, there is an example to explain.
topic 2 gradient descent for multiple variables
topic 3 gradient descent in practice 1 - feature scaling
mean normalization
appropriate number of mean normalization can make the gradient descent more quick.
use xi := (xi - ui) / si,
where
is the average of all the values for feature (i) and si is the range of values (max - min), or si is the standard deviation.
is the average of all the values for feature (i) and si is the range of values (max - min), or si is the standard deviation.
topic 4 Graident descent in practice ii - learning rate
how to adjust the parameter of learning rate, it is also a type a debug, so may be use a 3 to multiply the original learning rate to adjust the value to the optimal.
If J(θ) ever increases, then you probably need to decrease α.
when the curve is fluctuent, it needs a smaller learning rate.
To summarize:
If α is too small: slow convergence.
If α is too large: may not decrease on every iteration and thus may not converge.
------------恢复内容结束------------
在开始看之前,浏览器一直出现缓冲问题,是配置文件设置的不对,最后搞定,高兴!解决方法如下:
1.到C:\Windows\System32\drivers\etc下找到host文件,并以文本方式打开,
添加如下信息到hosts文件中:
52.84.246.90 d3c33hcgiwev3.cloudfront.net
52.84.246.252 d3c33hcgiwev3.cloudfront.net
52.84.246.144 d3c33hcgiwev3.cloudfront.net
52.84.246.72 d3c33hcgiwev3.cloudfront.net
52.84.246.106 d3c33hcgiwev3.cloudfront.net
52.84.246.135 d3c33hcgiwev3.cloudfront.net
52.84.246.114 d3c33hcgiwev3.cloudfront.net
52.84.246.90 d3c33hcgiwev3.cloudfront.net
52.84.246.227 d3c33hcgiwev3.cloudfront.net
2.刷新浏览器dns地址,ipconfig/flushdns,good! 这里贴出machine-learning of courase的address, maybe friends can learn a lot.
week01(不会django,只能这样)
chapter 00 introduction
structure and usage of machine learning
the definition of ML
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E
supervised learning
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
there are two types of supervised learning, that are regression and classification. one sign is whether the relationship of input and output is continuous.
unsupervised learning
there are no labels for the unsupervised learning, and we hope that the computer can help us to labels some databets.
chapter 01 model and cost function
topic1 模型导入:
training examples(x(i),y(i)),i=1,2,3...,m,m is trainging set;
h(x) si a 'good' predictor for the goal of housing price of y,and h(x) here is called hypothesis;
if we are trying to predict the problem continuously, such as the housing price, we call the learning problem a regression problem.
topic2 some figures of linear regression
cost function
choose a suitable hθ(x) for making the error with y to the minimum
make a cost function
topic3 cost function - intuition I
when θ0=0 and θ1=1,the cost function and function of the parameter is as below
the relationship between the function of hypothesis function and the cost function, that is to say, there are different values of cost function that is corresponding to the the function of hypothesis
topic 4 Intuition II
now, it is fixed values of θ0,θ1,
the curve face to the ground is the height of the J(θ0,θ1),we can see the description in the picture as below
it is also called contour plots or contour figures to the left graph as below, and we can get the minimal result as much as possible,
topic 5 algorithm of function of hypothesis to minimize the cost function of J
the best algorithm is to find a function to make the value of cost function which is a second-order function to the minimum, and then the inner circle point is what we need get. It is also corresonding to the two values θ0 and θ1.
chapter 02 parameter learning
topic 1 gradient descent
introduction
the theory of gradient descent, like a model going down the hill, it bases on the hypothesis function(theta0 and theta1), and the cost function J is bases on the hypothesis function graphed below.
the tangential line to a cost function is the black line which use athe derivative.
alpha is a parameter, which is called learning rate. A small alpha would result in a small step and a larger alpha would result in a larger step. the direction is taken by the partial derivative of J(θ0,θ1)
topic 2 OUTLINE OF THE GRADIENT DESCENT ALGORITHM
theta 0 and theta1 need update together, otherwise they will be replaced after operation, such as the line listed for theta 0, and next it is incorrect when replace the value of theta0 in the equation of temp1
topic 3 Gradient Descent Intuition
if alpha is to small, gradient descent can be slow; and if alpha is to large, gradient descent can overshoot the minimum. may not be converge or even diverge.
gradient descent can converge to a local minimum, whenever a learning rate alpha
gradient descent will automatically take smaller steps to make the result converge.
Use gradient descent to assure the change of theta, when the gradient is positive, the gradient descent gradually decrease and when the gradient is negative, the gradient descent gradually increase.
gradient for linear regression
partial derevative for theta0 and theta1
convex function and bowl shape
Batch gradient descent: every make full use of the training examples
gradient descent can be subceptible to local minima in general. gradient descent always converges to the global minimum.
review
vector is a matric which is nx1 matrix
R refers to the set of scalar real numbers.
Rn refers to the set of n-dimensional vectors of real numbers.
topic 4 Addition and scalar Multiplication
The knowledge here is similar with linear algebra, possibly there is no necessity to learn it.
topic 5 Matrix vector multiplication
The knowledge here is similar with linear algebra, possibly there is no necessity to learn it.
topic 6 Matrix Multiplication Properties
identity matrix
topic 7 review and review Inverse and Transpose of matrix
through computing, Matrix A multiply inverse A is not equal inverse A multiply Matrix A
week02
topic 1 Multiple features(variables)
compute the value xj(i) = value of feature j in ith training sets
x3(2), x(2) means the line 2 and the x3 means the third number, that is to say it is 2.
put the hypothesis to the n order, that is multivariable form of the hypothesis function
to define the function hθ(x) of the n order, we need to make sense its meaning, there is an example to explain.
topic 2 gradient descent for multiple variables
topic 3 gradient descent in practice 1 - feature scaling
mean normalization
appropriate number of mean normalization can make the gradient descent more quick.
use xi := (xi - ui) / sj
where μi is the average of all the values for feature (i) and si is the range of values (max - min), or si is the standard deviation.
topic 4 Gradient Descent in Practice II - Learning Rate

to summarize:
if alpha is too small, there is a slow convergence;
if alpha is too large, may not decrease on every iteration and thus may not converge.
topic 5 features and polynomial regression
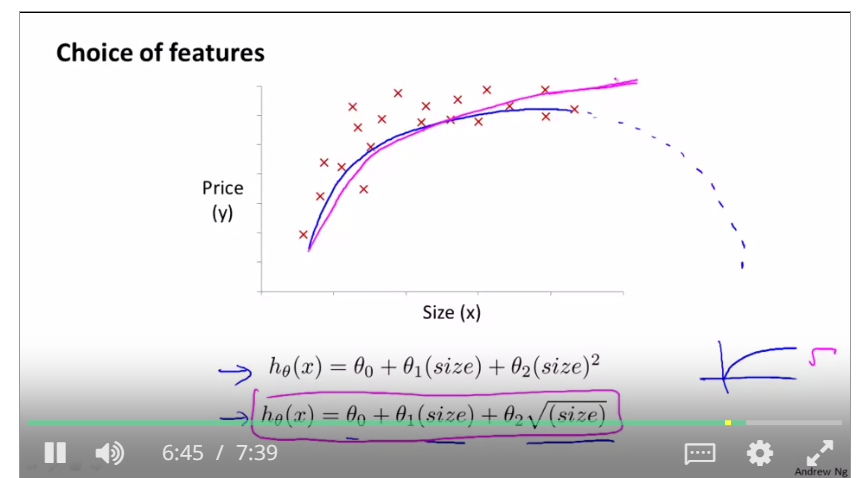
feature scaling is to find a new function that can fit the range of training examples, such as if the price is up to the feets ranging from 1 to 1000, and then the polinomial regression is used to change the type of the original function.

like this, we use two functions to compute the result, and x1 and x2 are that
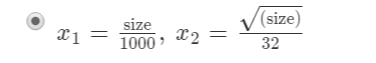
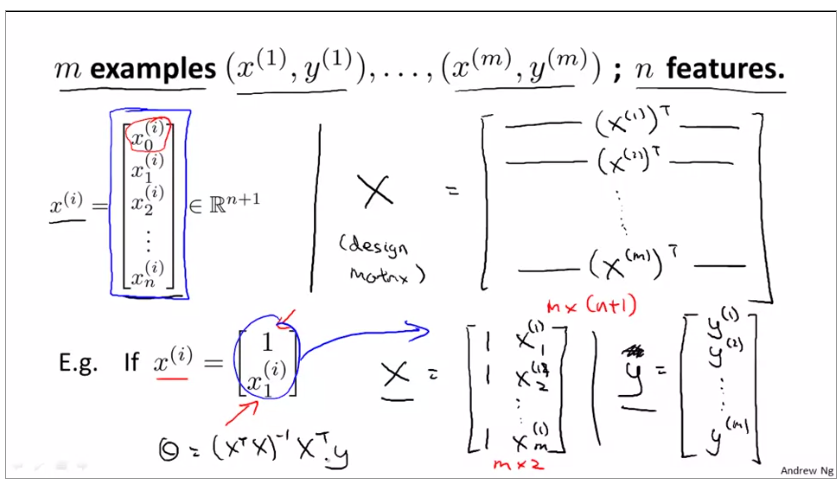
topic 6 Normal equation
for an example of normal equation
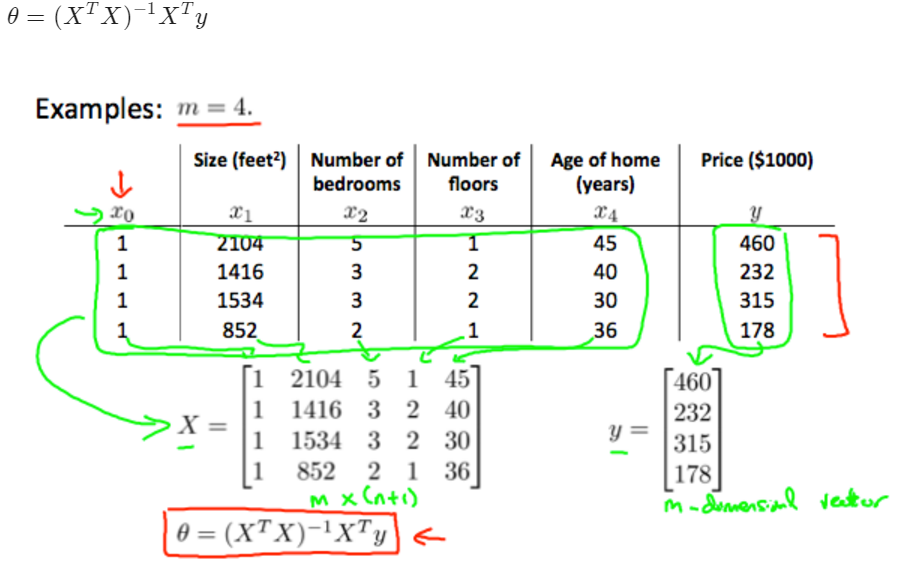
in programming:
x' means transpose X
pinv(x) means inverse Matrix

normal regression formula
the comparasion of the gradient descent and normal regression

topic 7 Normal Equation Noninvertibility

feature scaling: 特征缩放
normalized features:标准化特征
topic 7 practice of octive
some basic operation for octive, it is like some operations in matlab or python.numpy
topic 8 vectorization
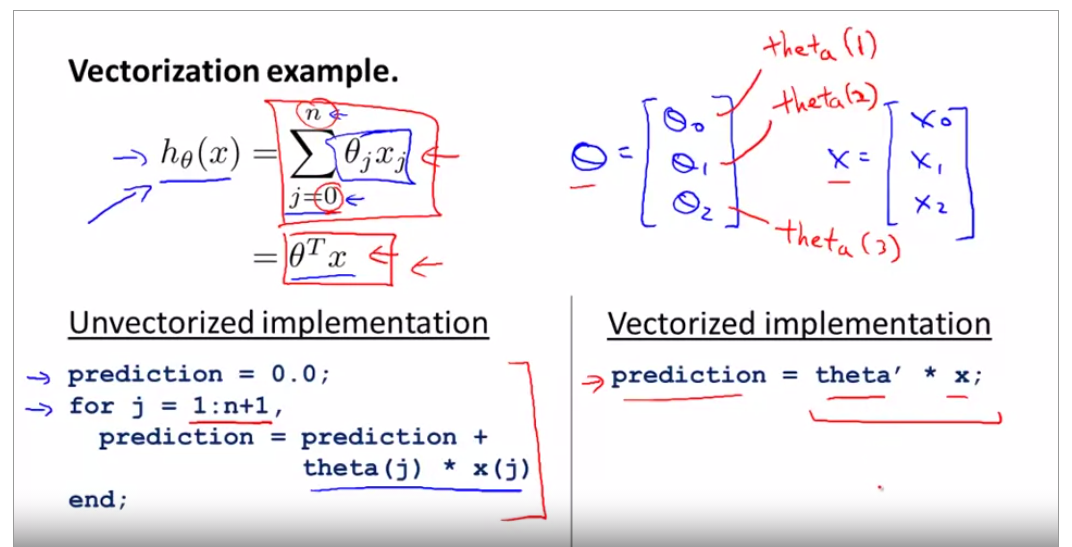
h(theta) is the original sythphasis function relate with theta0 and theta1, now use octave to vectorize it. prediction = theta' * x + theta(j) * x(j)
its programming in C++ below

download octave to programming, GNU octave docs is here.
机器学习 coursera_ML的更多相关文章
- .NET平台开源项目速览(13)机器学习组件Accord.NET框架功能介绍
Accord.NET Framework是在AForge.NET项目的基础上封装和进一步开发而来.因为AForge.NET更注重与一些底层和广度,而Accord.NET Framework更注重与机器 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 借助亚马逊S3和RapidMiner将机器学习应用到文本挖掘
本挖掘典型地运用了机器学习技术,例如聚类,分类,关联规则,和预测建模.这些技术揭示潜在内容中的意义和关系.文本发掘应用于诸如竞争情报,生命科学,客户呼声,媒体和出版,法律和税收,法律实施,情感分析和趋 ...
- Android开发学习之路-机器学习库(图像识别)、百度翻译
对于机器学习也不是了解的很深入,今天无意中在GitHub看到一个star的比较多的库,就用着试一试,效果也还行.比是可能比不上TensorFlow的,但是在Android上用起来比较简单,毕竟Tens ...
- 【NLP】基于机器学习角度谈谈CRF(三)
基于机器学习角度谈谈CRF 作者:白宁超 2016年8月3日08:39:14 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都 ...
- 机器学习实战笔记(Python实现)-08-线性回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-06-AdaBoost
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-05-支持向量机(SVM)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-04-Logistic回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
随机推荐
- IIS是怎么处理多个请求的?
一,假设有一台服务器,它的IIS上部署有一个Web应用程序-S,可以通过浏览器或其他方式进行访问. 假设有A.B.C三台电脑同时访问网站S,IIS接收到3个HTTP请求,然后分别为三个请求 ...
- 【JAVA】增强for循环for(int a : arr)
介绍 这种有冒号的for循环叫做foreach循环,foreach语句是java5的新特征之一,在遍历数组.集合方面,foreach为开发人员提供了极大的方便. foreach语句是for语句的特殊简 ...
- 线程池-连接池-JDBC实例-JDBC连接池技术
线程池和连接池 线程池的原理: 来看一下线程池究竟是怎么一回事?其实线程池的原理很简单,类似于操作系统中的缓冲区的概念,它的流程如下:先启动若干数量的线程,并让这些线程都处于睡眠状态,当客 ...
- hdu 4625 Dice(概率DP)
Dice Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) Total Submi ...
- 前端面试题:不使用loop循环,创建一个长度为100的数组,并且每个元素的值等于它的下标,,怎么实现好?
昨天,看这道题,脑子锈住了,就是没有思路,没看明白是什么意思?⊙﹏⊙|∣今天早上起床,想到需要思考一下这个问题. 当然,我没想明白为什么要这样做?(创建一个长度为100的数组,并且每个元素的值等于它的 ...
- linux常用基本命令 grep awk 待优化
查看centos操作系统版本:cat /etc/centos-release 切换到当前用户主目录:cd 或者cd ~ 创建文件夹/a/b/c:mkdir -pv /a/b/c.如果/a/b/c的父目 ...
- [14th CSMO Day 1 <平面几何>]
关于LowBee苦思冥想的结果(仅供参考):
- H700关闭Direct PD Mapping
Attached Enclosure doesn't support in controller's Direct mapping modePlease contact your system sup ...
- UE4 中的Blutilities
该功能是为编辑器中的简单扩展功能而设置的. 一般而言用蓝图在编辑器中做功能扩展都会用到Construction Script,但该功能有一些缺陷: 首先在actor发生任何变化(包括Transform ...
- 《数据结构与算法(C语言版)》严蔚敏 | 第四章课本案例
//二叉树的顺序存储表示 #define MAXTSIZE 100 typedef TElemtype SqBiTree[MAXTSIZE]; SqBiTree bt; //二叉树的二叉链表存储表示 ...