Hadoop Pig
Pig包括两部分:
- 用于描述数据流的语言,称为Pig Latin。
- 用于执行Pig Latin程序的执行环境,当前有两个环境:单JVM中的本地执行环境和Hadoop集群上的分布式执行环境。
Pig内部,每个操作或变换是对输入进行数据处理,然后产生输出结果,这些变换操作被转换成一系列MapReduce作业,Pig让程序员不需要知道这些转换具体是如何进行的,这样工程师可以将精力集中在数据上,而非执行的细节上。
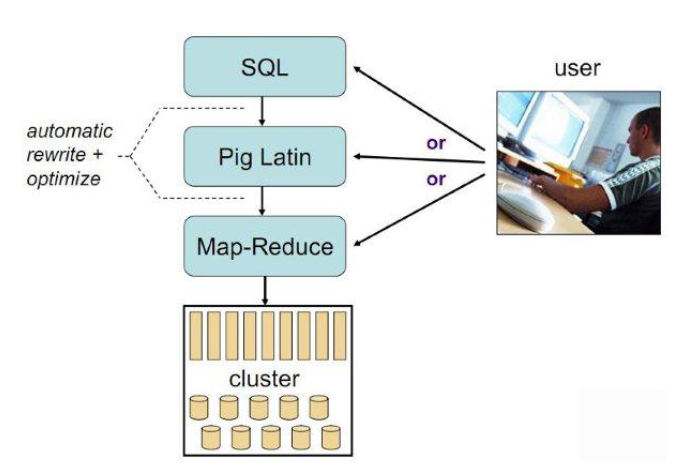
Pig可以看做hadoop的客户端软件,可以连接到hadoop集群进行数据分析的工作
Pig方便不熟悉java的用户,使用一种较为简便的类似SQL的面向数据流的语言piglatin进行数据处理
Pig Latin可以进行排序,过滤,求和,分组,关联等操作,还可以自定义函数,是一种面向数据分析的轻量级脚本语言
Pig可以看做pig latin到map-reduce的映射器
Pig安装
cp pig-0.16..tar.gz /home/hdp/
tar -zxvf pig-0.16..tar.gz
mv pig-0.16. pig
切换root设置环境变量
export PIG_INSTALL=/home/hdp/pig
export PATH=$PATH:$PIG_INSTALL/bin
source /etc/profile
本地模式(所有文件和执行过程都在本地,一般用于测试程序)
pig -x local
grunt>
Mapreduce模式
实际工作模式,在MapReduce模式下,Pig将查询翻译为MapReduce作业,然后在Hadoop集群上执行。Pig版本和Hadoop版本间有要求
切换root设置环境变量设置设置下HADOOP_HOME和PATH(一般装完hadoop之后都已经有了)
export PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop
export HADOOP_HOME=/home/hdp/hadoop
准备文件
hadoop dfs -mkdir /test
hadoop dfs -put ./LICENSE.txt /test
hadoop dfs -ls /test
pig -x mapreduce
grunt>
grunt> ls /
hdfs://mycluster/test <dir>
grunt> ls /test
hdfs://mycluster/test/LICENSE.txt<r 1> 84853
grunt>cat /test/LICENSE.txt grunt>copyToLOcal /test/LICENSE.txt ttt
grunt>sh /usr/jdk1.7.0_80/bin/jps
Pig数据模型
Bag:表
Tuple:行,记录
Field:属性
Pig不要求同一个bag里的哥哥tuple有相同数量或者相同类型的field
PigLatin
Load:载入数据的方法
foreach:逐行扫描进行某种处理
filter:过滤行
dump:把结果显示到屏幕
store:把结果保存到文件
一个实例:为天气温度数据集编写脚本计算一年中的最高纪录

第二个例子,统计每个ip的出现次数
数据源,网站log文件,已经上传到hdfs

grunt> A = LOAD '/test/access_log.txt' USING PigStorage(' ') AS (ip,others);
grunt> B = FOREACH A GENERATE ip;
grunt> C = FOREACH (GROUP B BY ip) GENERATE group AS ip,COUNT(B);
grunt> E = ORDER D by amount DESC,ip;
grunt> DUMP E;
(218.20.24.203,)
(221.194.180.166,)
(119.146.220.12,)
(117.136.31.144,)
(121.28.95.48,)
(113.109.183.126,)
(182.48.112.2,)
(120.84.24.200,)
(61.144.125.162,)
(27.115.124.75,)
(115.236.48.226,)
(59.41.62.100,)
(89.126.54.40,)
(114.247.10.132,)
(125.46.45.78,)
(220.181.94.221,)
(218.19.42.168,)
(118.112.183.164,)
(116.235.194.89,)
(114.43.237.117,)
(61.155.206.81,)
(202.108.18.253,)
(218.107.55.254,)
(14.213.176.184,)
(121.14.162.28,)
(123.150.182.147,)
(121.14.162.124,)
(123.150.182.180,)
(222.73.191.55,)
(27.9.110.75,)
(116.30.81.181,)
(116.7.101.166,)
(27.188.55.59,)
(220.178.27.142,)
(183.31.209.149,)
(192.250.46.129,)
(118.118.150.192,)
(124.74.27.218,)
(203.208.60.225,)
(203.208.60.227,)
(203.208.60.226,)
(112.4.2.51,)
(14.217.19.126,)
(59.108.111.207,)
(210.51.195.5,)
(218.31.116.143,)
(61.164.101.246,)
(117.136.31.147,)
(218.202.106.203,)
(117.136.12.6,)
(61.154.14.122,)
(99.76.10.239,)
(182.204.8.4,)
(59.151.120.38,)
(112.224.3.119,)
(180.168.111.114,)
(117.136.20.78,)
(122.89.138.26,)
(119.164.105.9,)
(116.116.8.161,)
(113.57.218.226,)
(114.248.114.208,)
(124.128.220.146,)
(71.45.41.139,)
(211.137.59.33,)
(211.140.5.103,)
(221.236.79.251,)
(121.28.205.250,)
(60.2.99.33,)
(211.139.92.11,)
(117.136.2.237,)
(123.147.244.39,)
(124.132.106.179,)
(211.137.199.56,)
(211.140.5.100,)
(117.136.12.192,)
(117.136.24.85,)
(117.136.8.11,)
(1.192.138.149,)
(183.12.74.40,)
(222.128.144.26,)
(59.151.120.36,)
(61.163.236.155,)
(117.136.10.141,)
(117.136.16.201,)
(117.136.23.238,)
(117.136.32.23,)
(218.89.132.133,)
(111.226.162.122,)
(218.213.137.2,)
(60.247.116.29,)
(110.16.198.88,)
(114.224.177.194,)
(121.41.128.23,)
(218.1.102.166,)
(61.164.72.118,)
(112.246.185.253,)
(114.98.146.181,)
(116.231.109.204,)
(120.68.17.229,)
(121.31.62.3,)
(124.238.242.47,)
(175.171.179.121,)
(180.95.186.78,)
(211.139.163.168,)
(220.191.226.141,)
(59.61.141.119,)
(111.161.72.31,)
(112.64.190.54,)
(117.136.15.96,)
(125.77.31.163,)
...
...
Pig适用场景
Pig并不适合所有的数据处理任务,和MapReduce一样,它是为数据批处理而设计的,如果想执行的查询只涉及一个大型数据集的一小部分数据,Pig的实现不会很好,因为它要扫描整个数据集或其中很大一部分。
随着新版本发布,Pig的表现和原生MapRedece程序差距越来越小,因为Pig的开发团队使用了复杂、精巧的算法来实现Pig的关系操作。除非你愿意花大量时间来优化Java MapReduce程序,否则使用Pig Latin来编写查询的确能帮你节约时间。
附录:
执行Pig程序的方法
- 脚本:Pig可以运行包含Pig命令的脚本文件,例如,pig script.pig,对于很短的脚本可以通过使用-e选项直接在命令行中输入脚本字符串。
- Grunt:Pig shell,就是上文的运行模式
- 嵌入式方法:也可以在Java中运行Pig程序,和使用JDBC运行SQL程序很像,详情:https://wiki.apache.org/pig/EmbeddedPig
Pig与RDBMS、Hive比较
- Pig Latin是一种数据流编程语言,而SQL是一种描述性编程语言。换句话说,Pig程序是相对于输入的一步步操作,其中每一步是对数据的一个简答的变换。相反,SQL语句是一个约束的集合,这些约束的集合在一起,定义了输出。
- 示例也可以看出,Pig其实是对Java的Mapreduce的封装,进一步的抽象,运行的也是java程序,并在此基础上提供其他特性。
- Hive介于Pig和传统RDBMS(关系数据库管理系统Relational Database Management System)之间,Hive的设计目的是让精通SQL既能的分析师能够在存放在HDFS的大规模数据集上运行查询。
- Hive在很多方面和传统数据库类似,但是它底层对HDFS和MapReduce的依赖意味着它的体系结构有别于传统数据库。
- Hive本身不存储数据,完全依赖于HDFS和MapReduce,Hive可以将结构化的数据文件映射为一张数据库表,Hive中表纯逻辑,就是表的元数据。而HBase是物理表,定位是NoSQL。
以下SQL在Pig中的实现refer to http://guoyunsky.iteye.com/blog/1317084
我这里以Mysql 5.1.x为例,Pig的版本是0.8
同时我将数据放在了两个文件,存放在/tmp/data_file_1和/tmp/data_file_2中.文件内容如下:
tmp_file_1:
- zhangsan 23 1
- lisi 24 1
- wangmazi 30 1
- meinv 18 0
- dama 55 0
tmp_file_2:
- 1 a
- 23 bb
- 50 ccc
- 30 dddd
- 66 eeeee
1.从文件导入数据
1)Mysql (Mysql需要先创建表).
CREATE TABLE TMP_TABLE(USER VARCHAR(32),AGE INT,IS_MALE BOOLEAN);
CREATE TABLE TMP_TABLE_2(AGE INT,OPTIONS VARCHAR(50)); -- 用于Join
LOAD DATA LOCAL INFILE '/tmp/data_file_1' INTO TABLE TMP_TABLE ;
LOAD DATA LOCAL INFILE '/tmp/data_file_2' INTO TABLE TMP_TABLE_2;
2)Pig
tmp_table = LOAD '/tmp/data_file_1' USING PigStorage('\t') AS (user:chararray, age:int,is_male:int);
tmp_table_2= LOAD '/tmp/data_file_2' USING PigStorage('\t') AS (age:int,options:chararray);
2.查询整张表
1)Mysql
SELECT * FROM TMP_TABLE;
2)Pig
DUMP tmp_table;
3. 查询前50行
1)Mysql
SELECT * FROM TMP_TABLE LIMIT 50;
2)Pig
tmp_table_limit = LIMIT tmp_table 50;
DUMP tmp_table_limit;
4.查询某些列
1)Mysql
SELECT USER FROM TMP_TABLE;
2)Pig
tmp_table_user = FOREACH tmp_table GENERATE user;
DUMP tmp_table_user;
5. 给列取别名
1)Mysql
SELECT USER AS USER_NAME,AGE AS USER_AGE FROM TMP_TABLE;
2)Pig
tmp_table_column_alias = FOREACH tmp_table GENERATE user AS user_name,age AS user_age;
DUMP tmp_table_column_alias;
6.排序
1)Mysql
SELECT * FROM TMP_TABLE ORDER BY AGE;
2)Pig
tmp_table_order = ORDER tmp_table BY age ASC;
DUMP tmp_table_order;
7.条件查询
1)Mysql
SELECT * FROM TMP_TABLE WHERE AGE>20;
2) Pig
tmp_table_where = FILTER tmp_table by age > 20;
DUMP tmp_table_where;
8.内连接Inner Join
1)Mysql
SELECT * FROM TMP_TABLE A JOIN TMP_TABLE_2 B ON A.AGE=B.AGE;
2)Pig
tmp_table_inner_join = JOIN tmp_table BY age,tmp_table_2 BY age;
DUMP tmp_table_inner_join;
9.左连接Left Join
1)Mysql
SELECT * FROM TMP_TABLE A LEFT JOIN TMP_TABLE_2 B ON A.AGE=B.AGE;
2)Pig
tmp_table_left_join = JOIN tmp_table BY age LEFT OUTER,tmp_table_2 BY age;
DUMP tmp_table_left_join;
10.右连接Right Join
1)Mysql
SELECT * FROM TMP_TABLE A RIGHT JOIN TMP_TABLE_2 B ON A.AGE=B.AGE;
2)Pig
tmp_table_right_join = JOIN tmp_table BY age RIGHT OUTER,tmp_table_2 BY age;
DUMP tmp_table_right_join;
11.全连接Full Join
1)Mysql
SELECT * FROM TMP_TABLE A JOIN TMP_TABLE_2 B ON A.AGE=B.AGE
UNION SELECT * FROM TMP_TABLE A LEFT JOIN TMP_TABLE_2 B ON A.AGE=B.AGE
UNION SELECT * FROM TMP_TABLE A RIGHT JOIN TMP_TABLE_2 B ON A.AGE=B.AGE;
2)Pig
tmp_table_full_join = JOIN tmp_table BY age FULL OUTER,tmp_table_2 BY age;
DUMP tmp_table_full_join;
12.同时对多张表交叉查询
1)Mysql
SELECT * FROM TMP_TABLE,TMP_TABLE_2;
2)Pig
tmp_table_cross = CROSS tmp_table,tmp_table_2;
DUMP tmp_table_cross;
13.分组GROUP BY
1)Mysql
SELECT * FROM TMP_TABLE GROUP BY IS_MALE;
2)Pig
tmp_table_group = GROUP tmp_table BY is_male;
DUMP tmp_table_group;
14.分组并统计
1)Mysql
SELECT IS_MALE,COUNT(*) FROM TMP_TABLE GROUP BY IS_MALE;
2)Pig
tmp_table_group_count = GROUP tmp_table BY is_male;
tmp_table_group_count = FOREACH tmp_table_group_count GENERATE group,COUNT($1);
15.查询去重DISTINCT
1)MYSQL
SELECT DISTINCT IS_MALE FROM TMP_TABLE;
2)Pig
tmp_table_distinct = FOREACH tmp_table GENERATE is_male;
tmp_table_distinct = DISTINCT tmp_table_distinct;
DUMP tmp_table_distinct;
Hadoop Pig的更多相关文章
- Hadoop:pig 安装及入门示例
pig是hadoop的一个子项目,用于简化MapReduce的开发工作,可以用更人性化的脚本方式分析数据. 一.安装 a) 下载 从官网http://pig.apache.org下载最新版本(目前是0 ...
- hadoop pig入门总结
在这里贴一个pig源码的分析,做pig很长时间没做笔记,不包含任何细节,以后有机会再说吧 http://blackproof.iteye.com/blog/1769219 hadoop pig入门总结 ...
- Hadoop Pig简介、安装、试用
相比Java的MapReduce api,Pig为大型数据集的处理提供了更高层次的抽象,与MapReduce相比,Pig提供了更丰富的数据结构,一般都是多值和嵌套的数据结构.Pig还提供了一套更强大的 ...
- Hadoop Pig组件
- Hadoop学习笔记—16.Pig框架学习
一.关于Pig:别以为猪不能干活 1.1 Pig的简介 Pig是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换 ...
- Pig安装及简单使用(pig版本0.13.0,Hadoop版本2.5.0)
原文地址:http://www.linuxidc.com/Linux/2014-03/99055.htm 我们用MapReduce进行数据分析.当业务比较复杂的时候,使用MapReduce将会是一个很 ...
- [hadoop系列]Pig的安装和简单演示样例
inkfish原创,请勿商业性质转载,转载请注明来源(http://blog.csdn.net/inkfish ).(来源:http://blog.csdn.net/inkfish) Pig是Yaho ...
- Hadoop 之Pig的安装的与配置之遇到的问题---待解决
1. 前提是hadoop集群已经配置完成并且可以正常启动:以下是我的配置方案: 首先配置vim /etc/hosts 192.168.1.64 xuegod64 192.168.1.65 xuegod ...
- Hive集成HBase;安装pig
Hive集成HBase 配置 将hive的lib/中的HBase.jar包用实际安装的Hbase的jar包替换掉 cd /opt/hive/lib/ ls hbase-0.94.2* rm -rf ...
随机推荐
- mysql 随机取数据
SELECT * FROM table WHERE id >= (SELECT FLOOR(RAND()*MAX(id)) FROM table ) ORDER BY idLIMIT 1; 这样 ...
- APP开发关于缓存
1 http://www.cnblogs.com/qianxudetianxia/archive/2012/02/20/2112128.html 1.1 http://blog.csdn.net/ln ...
- ganlia安装配置文档
gangliaz在ubuntu中安装和配置很简单 1. 服务器端安装 sudo apt-get install ganglia-monitor ganglia-webfrontend rrdtool ...
- NFS详细分析
1. NFS服务介绍 1.1什么是NFS服务 NFS(Network File System)即网络文件系统,它允许网络中的计算机之间通过TCP/IP网络共享资源.在NFS的应用中,本地NFS的客户端 ...
- ubuntu16.04上安装深度学习基本框架caffe2 pytorch tensorflow opencv
anaconda3.5.2.0----python3.6: conda install tensorflow-gpu -y --prefix /media/wkr/diskHgst/ubun ...
- Active Directory的基本概念
前言 本文是面对准备加入Active Directory编程的初学者的一份文章,主要是讲解Active Directory(活动目录)的一些概念和相关知识.这篇文章本来是不想写下来的,因为概念性内容的 ...
- mapreduce学习资料
http://blog.csdn.net/tianjun2012/article/category/6794531 http://blog.csdn.net/tianjun2012/article/d ...
- 【数据挖掘】分类之Naïve Bayes(转载)
[数据挖掘]分类之Naïve Bayes 1.算法简介 朴素贝叶斯(Naive Bayes)是监督学习的一种常用算法,易于实现,没有迭代,并有坚实的数学理论(即贝叶斯定理)作为支撑. 本文以拼写检查作 ...
- Memcached下载、安装及使用演示。
Memcached下载及安装: 下载地址: memcached-1.4.5-amd64.zip================================================通过cmd ...
- 修改Liunx服务器SSH端口
为提高Linux系统安全性,我们经常会修改ssh端口,下面以CentOS 6为例: vi /etc/ssh/sshd_config 修改ssh端口,默认配置如下: 修改为自己想要的端口号(小于6553 ...