算法(Algorithms)第4版 练习 1.5.3
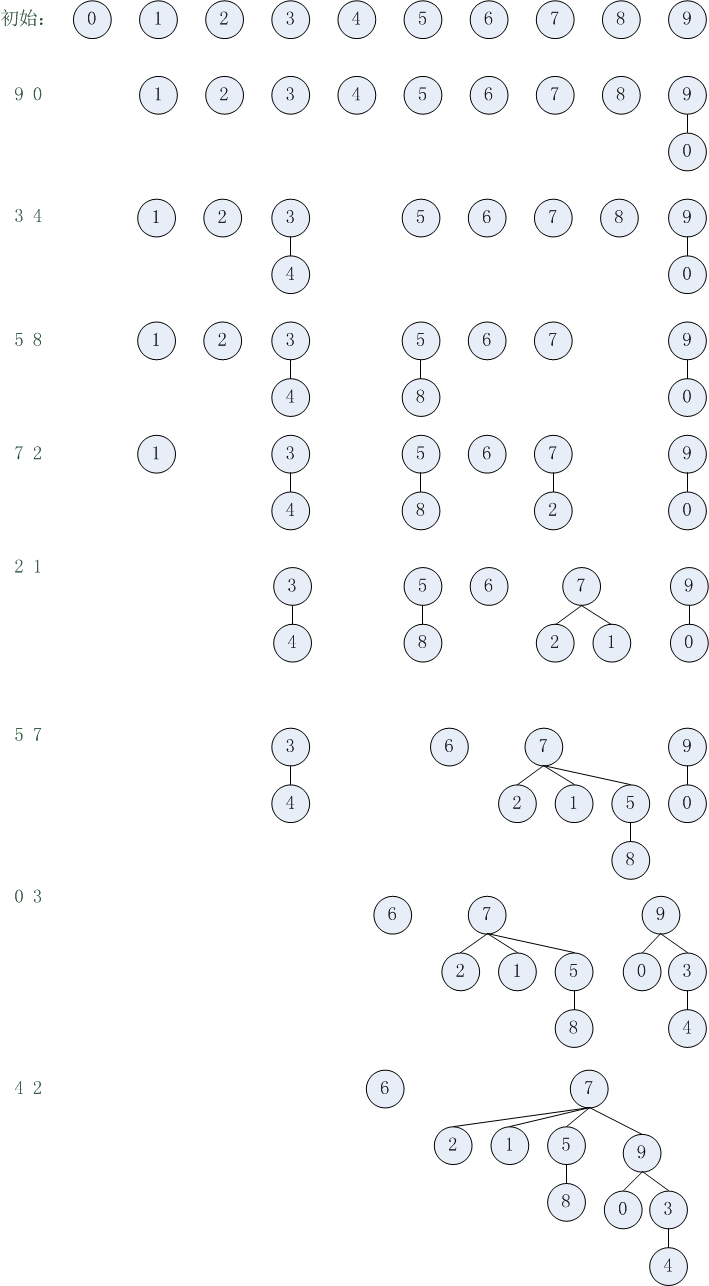
id数组和treesize数组变化情况:
0 1 2 3 4 5 6 7 8 9
1 1 1 1 1 1 1 1 1 1
10 components
9 0
1 2 3 4 5 6 7 8 9
1 1 1 1 1 1 1 1 1
9 components
3 4
9 1 2 3 5 6 7 8 9
1 1 1 1 1 1 1 1 2
8 components
5 8
9 1 2 3 3 5 6 7 9
1 1 1 2 1 1 1 1 2
7 components
7 2
9 1 3 3 5 6 7 5 9
1 1 1 2 1 2 1 1 2
6 components
2 1
9 7 3 3 5 6 7 5 9
1 1 1 2 1 2 1 1 2
5 components
5 7
9 7 7 3 3 6 7 5 9
1 1 1 2 1 2 1 1 2
4 components
0 3
9 7 7 3 7 6 7 5 9
1 1 1 2 1 2 1 5 1
3 components
4 2
9 7 7 9 3 7 6 7 5
1 1 1 2 1 2 1 1 4
2 components
森林图:
操作次数分析:
find函数每次访问数组次数是1 + 2 * depth
connected函数每次调用两次find函数
union函数每次调用两次find函数(如果两个连接点不在同一个树的话,则多一次数组访问)
public static void main(String[] args) {
//initialize N components
int N = StdIn.readInt();
UFWeightedQuickUnion uf = new UFWeightedQuickUnion(N);
StdOut.println(uf);
while(!StdIn.isEmpty()) {
int p = StdIn.readInt();
int q = StdIn.readInt();
if(uf.connected(p, q)) {//ignore if connected
StdOut.println(p + " " + q + " is connected");
continue;
}
uf.union(p, q);//connect p and q
StdOut.println(p + " " + q);
StdOut.println(uf);
}
}
对于这个client,对每个数据对,都调用一次connected函数和union函数。
下边对数组访问次数进行分析:
9 0:9和0的深度都为0,find访问数组次数为1,connected为2 * 1, union为2 * 1 + 5,总的为2 * 1 + 2 * 1 + 5
3 4:3和4的深度都为0,find访问数组次数为1,connected为2 * 1, union为2 * 1 + 5,总的为2 * 1 + 2 * 1 + 5
5 8:5和8的深度都为0,find访问数组次数为1,connected为2 * 1, union为2 * 1 + 5,总的为2 * 1 + 2 * 1 + 5
7 2:7和2的深度都为0,find访问数组次数为1,connected为2 * 1, union为2 * 1 + 5,总的为2 * 1 + 2 * 1 + 5
2 1:2的深度为1,1的深度为0。find访问数组次数分别为3、1,connected为3 + 1, union为3 + 1 + 5,总的为3 + 1 +3 + 1 + 5
5 7:5的深度为0,7的深度为0。find访问数组次数分别为1、1,connected为1 + 1, union为1 + 1 + 5,总的为1 + 1 +1 + 1 + 5
0 3:0的深度为1,3的深度为0。find访问数组次数分别为3、1,connected为3 + 1, union为3 + 1 + 5,总的为3 + 1 +3 + 1 + 5
4 2:4的深度为2,2的深度为1。find访问数组次数分别为5、3,connected为5 + 3, union为5 + 3 + 5,总的为5 + 3 +5 + 3 + 5
源代码:
package com.qiusongde; import edu.princeton.cs.algs4.StdIn;
import edu.princeton.cs.algs4.StdOut; public class UFWeightedQuickUnion { private int[] id;//parent link(site indexed)
private int[] treesize;//size of component for roots(site indexed)
private int count;//number of components public UFWeightedQuickUnion(int N) { count = N; id = new int[N];
for(int i = 0; i < N; i++)
id[i] = i; treesize = new int[N];
for(int i = 0; i < N; i++)
treesize[i] = 1; } public int count() {
return count;
} public boolean connected(int p, int q) {
return find(p) == find(q);
} public int find(int p) { while(p != id[p])
p = id[p]; return p; } public void union(int p, int q) { int pRoot = find(p);
int qRoot = find(q); if(pRoot == qRoot)
return; //make smaller root point to larger one
if(treesize[pRoot] < treesize[qRoot]) {
id[pRoot] = qRoot;
treesize[qRoot] += treesize[pRoot];
} else {
id[qRoot] = pRoot;
treesize[pRoot] += treesize[qRoot];
} count--; } @Override
public String toString() {
String s = ""; for(int i = 0; i < id.length; i++) {
s += id[i] + " ";
}
s += "\n"; for(int i = 0; i < treesize.length; i++) {
s += treesize[i] + " ";
}
s += "\n" + count + " components"; return s;
} public static void main(String[] args) { //initialize N components
int N = StdIn.readInt();
UFWeightedQuickUnion uf = new UFWeightedQuickUnion(N);
StdOut.println(uf); while(!StdIn.isEmpty()) { int p = StdIn.readInt();
int q = StdIn.readInt(); if(uf.connected(p, q)) {//ignore if connected
StdOut.println(p + " " + q + " is connected");
continue;
} uf.union(p, q);//connect p and q
StdOut.println(p + " " + q);
StdOut.println(uf);
} } }
算法(Algorithms)第4版 练习 1.5.3的更多相关文章
- 1.2 Data Abstraction(算法 Algorithms 第4版)
1.2.1 package com.qiusongde; import edu.princeton.cs.algs4.Point2D; import edu.princeton.cs.algs4.St ...
- 1.1 BASIC PROGRAMMING MODEL(算法 Algorithms 第4版)
1.1.1 private static void exercise111() { StdOut.println("1.1.1:"); StdOut.println((0+15)/ ...
- ubuntu命令行下java工程编辑与算法(第四版)环境配置
ubuntu命令行下java工程编辑与算法(第四版)环境配置 java 命令行 javac java 在学习算法(第四版)中的实例时,因需要安装配套的java编译环境,可是在编译java文件的时候总是 ...
- 配置算法(第4版)的Java编译环境
1. 下载 1.1 JDK http://www.oracle.com/technetwork/java/javase/downloads/index.html选择“Windows x64 180.5 ...
- 算法(第四版)C# 习题题解——1.3.49 用 6 个栈实现一个 O(1) 队列
因为这个解法有点复杂,因此单独开一贴介绍. 那么这里就使用六个栈来解决这个问题. 这个算法来自于这篇论文. 原文里用的是 Pure Lisp,不过语法很简单,还是很容易看懂的. 先导知识——用两个栈模 ...
- 在Eclipse下配置算法(第四版)运行环境
第一步:配置Eclipse运行环境 Eclipse运行环境配置过程是很简单的,用过Eclipse进行java开发或学习的同学应该都很熟悉这个过程了. 配置过程: (1)系统环境:Windows7 64 ...
- 排序算法总结(C语言版)
排序算法总结(C语言版) 1. 插入排序 1.1 直接插入排序 1.2 Shell排序 2. 交换排序 2.1 冒泡排序 2.2 快速排序 3. 选择 ...
- 算法(第四版)C#题解——2.1
算法(第四版)C#题解——2.1 写在前面 整个项目都托管在了 Github 上:https://github.com/ikesnowy/Algorithms-4th-Edition-in-Csh ...
- 《算法》第四版 IDEA 运行环境的搭建
<算法>第四版 IDEA 运行环境的搭建 新建 模板 小书匠 在搭建之初,我是想不到会出现如此之多的问题.我看了网上的大部分教程,都是基于Eclipse搭建的,还没有使用IDEA搭建的教程 ...
- 常见排序算法题(java版)
常见排序算法题(java版) //插入排序: package org.rut.util.algorithm.support; import org.rut.util.algorithm.Sor ...
随机推荐
- java数字签名算法之RSA
© 版权声明:本文为博主原创文章,转载请注明出处 实例 1.项目结构 2.pom.xml <project xmlns="http://maven.apache.org/POM/4.0 ...
- spring的xml配置文件出现故障
今天在断网的情况下,spring的applicationContext.xml文件开头部分出现红叉 <span style="font-size:18px;">< ...
- java多线程之happens-before
1.背景问题 在讲happens-before之前,先引入一个例子: 假定我们有已经被初始化的变量: int counter = 0; 这个 counter 变量被两个线程所共有,也就是说线程A和线程 ...
- cocos2dx 3.0rc怎样创建项目
转自官网的文档. How to Run cpp-tests on win32 In this article, I will show you how to run cpp-tests on your ...
- BZOJ 2176 Strange string 最小表示法
题目大意:给定一个串S,求最小表示法 n<=1000W,实在不敢写后缀自己主动机,就去学了最小表示法= = 记得用unsigned char不然WA= = 数据真是逗- - #include & ...
- 【Atheros】Ath9k速率调整算法源码走读
上一篇文章介绍了驱动中minstrel_ht速率调整算法,atheros中提供了可选的的两种速率调整算法,分别是ath9k和minstrel,这两个算法分别位于: drivers\net\wirele ...
- PHP-Manual的学习----【语言参考】----【类型】-----【array数组】
1.Array 数组 PHP 中的 数组 实际上是一个有序映射.映射是一种把 values 关联到 keys 的类型.此类型在很多方面做了优化,因此可以把它当成真正的数组,或列表(向量),散列表(是 ...
- python 深复制与浅复制------copy模块
模块解读: 浅复制: x = copy.copy(y)深复制: x = copy.deepcopy(y)(注:模块特有的异常,copy.Error) 深copy与浅copy的差别主要体现在当有混合对象 ...
- EasyDSS流媒体解决方案实现的RTMP/HLS视频直播、直播鉴权(如何完美将EasyDSS过渡到新版)
上一篇博文介绍了EasyDSS点播功能,然后作为RTMP流媒体服务器,接受RTMP推流.进行实时的直播流分发又是自身一大核心功能. 需求背景: 写本篇博文的一个目的是向大家介绍一下EasyDSS新版的 ...
- SpringMVC拦截器实现用户登录拦截
本例实现登陆时的验证拦截,采用SpringMVC拦截器来实现 当用户点击到网站主页时要进行拦截,用户登录了才能进入网站主页,否则进入登陆页面 核心代码 首先是index.jsp,显示链接 1 < ...