MPP(大规模并行处理)
1、 什么是MPP?
MPP (Massively Parallel Processing),即大规模并行处理,在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。
简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。
2、MPP(大规模并行处理)架构
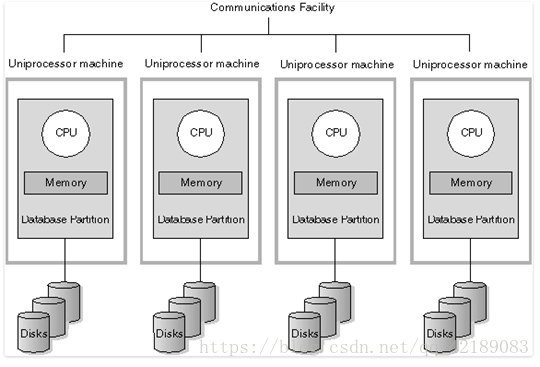
(MPP架构)
3、 MPP架构特征
● 任务并行执行;
● 数据分布式存储(本地化);
● 分布式计算;
● 私有资源;
● 横向扩展;
● Shared Nothing架构。
4、 MPP服务器架构
它由多个SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个SMP服务器(每个SMP服务器称节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构,因而扩展能力最好,理论上其扩展无限制。
5、MPPDB
MPPDB是一款 Shared Nothing 架构的分布式并行结构化数据库集群,具备高性能、高可用、高扩展特性,可以为超大规模数据管理提供高性价比的通用计算平台,并广泛地用于支撑各类数据仓库系统、BI 系统和决策支持系统
6、MPPDB架构
MPP 采用完全并行的MPP + Shared Nothing 的分布式扁平架构,这种架构中的每一个节点(node)都是独立的、自给的、节点之间对等,而且整个系统中不存在单点瓶颈,具有非常强的扩展性。
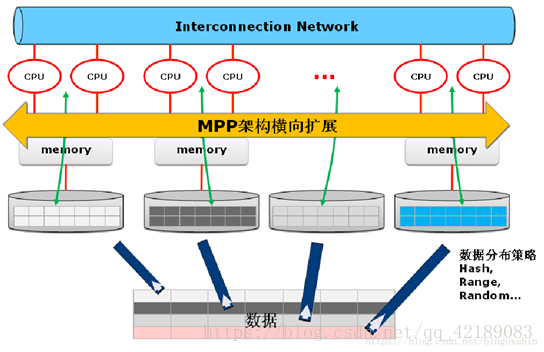
MPPDB架构
7、 MPPDB特征
MPP 具备以下技术特征:
1) 低硬件成本:完全使用 x86 架构的 PC Server,不需要昂贵的 Unix 服务器和磁盘阵列;
2) 集群架构与部署:完全并行的 MPP + Shared Nothing 的分布式架构,采用 Non-Master 部署,节点对等的扁平结构;
3) 海量数据分布压缩存储:可处理 PB 级别以上的结构化数据,采用 hash分布、random 存储策略进行数据存储;同时采用先进的压缩算法,减少存储数据所需的空间,可以将所用空间减少 1~20 倍,并相应地提高 I/O 性能;
4) 数据加载高效性:基于策略的数据加载模式,集群整体加载速度可达2TB/h;
5) 高扩展、高可靠:支持集群节点的扩容和缩容,支持全量、增量的备份/恢复;
6) 高可用、易维护:数据通过副本提供冗余保护,自动故障探测和管理,自动同步元数据和业务数据。提供图形化工具,以简化管理员对数据库的管理工作;
7) 高并发:读写不互斥,支持数据的边加载边查询,单个节点并发能力大于 300 用户;
8) 行列混合存储:提供行列混合存储方案,从而提高了列存数据库特殊查询场景的查询响应耗时;
9) 标准化:支持SQL92 标准,支持 C API、ODBC、JDBC、ADO.NET 等接口规范。
8、 常见MPPDB
● GREENPLUM(EMC)
● Asterdata(Teradata)
● Nettezza(IBM)
● Vertica(HP)
● GBase 8a MPP cluster(南大通用)
9、 MPPDB、Hadoop与传统数据库技术对比与适用场景
MPPDB与Hadoop都是将运算分布到节点中独立运算后进行结果合并(分布式计算),但由于依据的理论和采用的技术路线不同而有各自的优缺点和适用范围。两种技术以及传统数据库技术的对比如下:
|
特征 |
Hadoop |
MPPDB |
传统数据仓库 |
|
平台开放性 |
高 |
低 |
低 |
|
运维负责度 |
高 |
中 |
中 |
|
扩展能力 |
高 |
中 |
低 |
|
拥有成本 |
低 |
中 |
高 |
|
系统和数据管理成本 |
高 |
中 |
中 |
|
应用开发维护成本 |
高 |
中 |
中 |
|
SQL支持 |
中(低) |
高 |
高 |
|
数据规模 |
PB级别 |
部分PB |
TB级别 |
|
计算性能 |
对非关系型操作效率高 |
对关系型操作效率高 |
对关系型操作效率中 |
|
数据结构 |
机构化、半结构化和非机构化数据 |
结构化数据 |
结构化数据 |
综合而言,Hadoop和MPP两种技术的特定和适用场景为:
● Hadoop在处理非结构化和半结构化数据上具备优势,尤其适合海量数据批处理等应用要求。
● MPP适合替代现有关系数据机构下的大数据处理,具有较高的效率。
MPP适合多维度数据自助分析、数据集市等;Hadoop适合海量数据存储查询、批量数据ETL、非机构化数据分析(日志分析、文本分析)等。
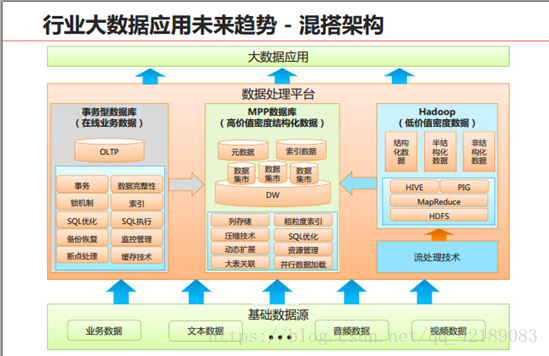
由上述对比可预见未来大数据存储与处理趋势:MPPDB+Hadoop混搭使用,用MPP处理PB级别的、高质量的结构化数据,同时为应用提供丰富的SQL和事物支持能力;用Hadoop实现半结构化、非结构化数据处理。这样可以同时满足结构化、半结构化和非结构化数据的高效处理需求。
MPP(大规模并行处理)的更多相关文章
- MPP(大规模并行处理)简介
1. 什么是MPP? MPP (Massively Parallel Processing),即大规模并行处理,在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和 ...
- MPP大规模并行处理架构详解
面试官:说下你知道的MPP架构的计算引擎? 这个问题不少小伙伴在面试时都遇到过,因为对MPP这个概念了解较少,不少人都卡壳了,但是我们常用的大数据计算引擎有很多都是MPP架构的,像我们熟悉的Impal ...
- 从Oracle迁移到Mysql之前必须知道的50件事
1. 对子查询的优化表现不佳. 2. 对复杂查询的处理较弱 3. 查询优化器不够成熟 4. 性能优化工具与度量信息不足 5. 审计功能相对较弱 6. 安全功能不成熟,甚至可以说很粗糙.没有用户组与角色 ...
- PostgreSQL与MySQL比较(转)
Mysql 使用太广泛了,以至于我不得不将一些应用从mysql 迁移到postgresql, 很多开源软件都是以Mysql 作为数据库标准,并且以Mysql 作为抽象基础的,但是具体使用过程中,发现M ...
- 北风风hadoop课程体系
课程一.基于Linux操作系统平台下的Java语言开发(20课时)课程简介本套课程主要介绍了Linux系统下的Java环境搭建及最基础的Java语法知识.学习Linux操作系统下Java语言开发的好处 ...
- 基于Greenplum Hadoop分布式平台的大数据解决方案及商业应用案例剖析
随着云计算.大数据迅速发展,亟需用hadoop解决大数据量高并发访问的瓶颈.谷歌.淘宝.百度.京东等底层都应用hadoop.越来越多的企 业急需引入hadoop技术人才.由于掌握Hadoop技术的开发 ...
- Mysql 和 Postgresql(PGSQL) 对比
Mysql 和 Postgresql(PGSQL) 对比 转载自:http://www.oschina.net/question/96003_13994 PostgreSQL与MySQL比较 MySQ ...
- apache-kylin 权威指南—读书笔记
1. 概述 kylin 是 OLAP 引擎,采用多维立方体预计算技术,可将大数据的 SQL 查询速度提升到亚秒级别. 需求: 虽然像 spark,hive 等使用 MPP 大规模并行处理和列式存储的方 ...
- oracle 事务 锁机制
原文地址:http://www.cnblogs.com/quanweiru/archive/2013/05/24/3097367.html 本课内容属于Oracle高级课程范畴,内容略微偏向理论性,但 ...
随机推荐
- JVM:java类的加载机制
原文连接:https://www.cnblogs.com/ityouknow/p/5603287.html 类加载机制的奥妙. 1.什么是类的加载 类的加载指的是将类的.class文件中的二进制数据读 ...
- (生产)create-keyframe-animation -动画实现
参考:https://github.com/HenrikJoreteg/create-keyframe-animation 实例 var animations = require('create-ke ...
- HTML5制作新年贺春
<!DOCTYPE html> <html> <head> <meta charset='UTF-8'/> <meta name='viewpor ...
- DXperience Winforms新版本13.2功能预览
据界面控件厂商 DevExpress 官方最新消息,大家期盼已久的DXperience 13.2终于要面世了.今天在这里提前跟大家提前披露一下DXperience Winforms 13.2的一些精彩 ...
- 解决在php5中simple XML解析错误的问题
2004年7月,php5正式版本的发布,标志着一个全新的PHP时代的到来.PHP5的最大特点是引入了面向对象的全部机制,并且保留了向下的兼容性.程序员不必再编写缺乏功能性的类,并且能够以多种方法实现类 ...
- vue - 绑定css、style
1.绑定html css1.1对象语法: 传给 v-bind:class 一个对象,以动态地切换 class <div v-bind:class="{ active: isActive ...
- BZOJ 4679/Hdu5331 Simple Problem LCT or 树链剖分
4679: Hdu5331 Simple Problem 题意: 考场上,看到这道题就让我想起BZOJ4712洪水.然后思路就被带着飞起了,完全没去考虑一条链的情况,于是GG. 解法:先考虑一条链的做 ...
- 二进制安装mysql5.6
安装依赖包 yum install -y libaio yum install -y perl perl-devel 解压 mkdir /opt/mysql mv mysql-5.6 ...
- Android(java)学习笔记68:使用proguard混淆android代码
1. 当前是有些工具比如apktool,dextojar等是可以对我们android安装包进行反编译,获得源码的.为了减少被别人破解,导致源码泄露,程序被别人盗取代码,等等.我们需要对代码进行混淆,a ...
- PHP APC安装与使用
先要解决一下httpd-devel依赖库问题 yum install cyrus-sasl-devel db4-devel openldap apr apr-util apr-util-devel p ...