caffe的损失函数
损失函数,一般由两项组成,一项是loss term,另外一项是regularization term。
J=L+R
先说损失项loss,再说regularization项。
1. 分对得分1,分错得分0.gold standard
2. hinge loss(for softmargin svm),J=1/2||w||^2 + sum(max(0,1-yf(w,x)))
3. log los, cross entropy loss function in logistic regression model.J=lamda||w||^2+sum(log(1+e(-yf(wx))))
4. squared loss, in linear regression. loss=(y-f(w,x))^2
5. exponential loss in boosting. J=lambda*R+exp(-yf(w,x))
再说regularization项,
一般用的多的是R2=1/2||w||^2,R1=sum(|w|)。R1和R2是凸的,同时R1会使得损失函数更加具有sparse,而R2则会更加光滑些。具体可以参见下图:

caffe的损失函数,目前已经囊括了所有可以用的了吧,损失函数由最后一层分类器决定,同时有时会加入regularization,在BP过程中,使得误差传递得以良好运行。
contrastive_loss,对应contrastive_loss_layer,我看了看代码,这个应该是输入是一对用来做验证的数据,比如两张人脸图,可能是同一个人的(正样本),也可能是不同个人(负样本)。在caffe的examples中,siamese这个例子中,用的损失函数是该类型的。该损失函数具体数学表达形式可以参考lecun的文章Dimensionality Reduction by Learning an Invariant Mapping, Raia Hadsell, Sumit Chopra, Yann LeCun, cvpr 2006.
euclidean_loss,对应euclidean_loss_layer,该损失函数就是l=(y-f(wx))^2,是线性回归常用的损失函数。
hinge_loss,对应hinge_loss_layer,该损失函数就是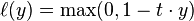 。主要用在SVM分类器中。
。主要用在SVM分类器中。
infogain_loss,对应infogain_loss_layer,损失函数表达式没找到,只知道这是在文本处理中用到的损失函数。
multinomial_logistic_loss,对应multinomial_logistic_loss_layer,
sigmoid_cross_entropy,对应sigmoid_cross_entropy_loss_layer,也就是logistic regression使用的损失函数。
softmax_loss,对应softmax_loss_layer,损失函数等可以见UFLDL中关于softmax章节。在caffe中多类分类问题,损失函数就是softmax_loss,比如imagenet, mnist等。softmax_loss是sigmoid的多类问题。但是,我就没明白,multinomial_logistic_loss和这个有什么区别,看代码,输入有点差别,softmax的输入是probability,而multinomial好像不要求是probability,但是还是没明白,如果只是这样,岂不是一样啊?
这里详细说明了两者之间的差异,并且有详细的测试结果,非常赞。简单理解,multinomial 是将loss分成两个层进行,而softmax则是合在一起了。或者说,multinomial loss是按部就班的计算反向梯度,而softmax则是把两个步骤直接合并为一个步骤进行了,减少了中间的精度损失等 ,从计算稳定性讲,softmax更好,multinomial是标准做法,softmax则是一种优化吧。
转自caffe:
Softmax
- LayerType:
SOFTMAX_LOSS
The softmax loss layer computes the multinomial logistic loss of the softmax of its inputs. It’s conceptually identical to a softmax layer followed by a multinomial logistic loss layer, but provides a more numerically stable gradient.
references:
http://www.ics.uci.edu/~dramanan/teaching/ics273a_winter08/lectures/lecture14.pdf
http://caffe.berkeleyvision.org/tutorial/layers.html
Bishop, pattern recognition and machine learning
http://deeplearning.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
http://freemind.pluskid.org/machine-learning/softmax-vs-softmax-loss-numerical-stability/
caffe的损失函数的更多相关文章
- Caffe学习笔记(二):Caffe前传与反传、损失函数、调优
Caffe学习笔记(二):Caffe前传与反传.损失函数.调优 在caffe框架中,前传/反传(forward and backward)是一个网络中最重要的计算过程:损失函数(loss)是学习的驱动 ...
- Caffe框架下的图像回归测试
Caffe框架下的图像回归测试 参考资料: 1. http://stackoverflow.com/questions/33766689/caffe-hdf5-pre-processing 2. ht ...
- Caffe学习系列(13):对训练好的模型进行fine-tune
使用http://www.cnblogs.com/573177885qq/p/5804863.html中的图片进行训练和测试. 整个流程差不多,fine-tune命令: ./build/tools/c ...
- caffe中各层的作用:
关于caffe中的solver: cafffe中的sover的方法都有: Stochastic Gradient Descent (type: "SGD"), AdaDelta ( ...
- Caffe(卷积神经网络框架)介绍
Caffe(卷积神经网络框架)Caffe,全称Convolution Architecture For Feature Extraction caffe是一个清晰,可读性高,快速的深度学习框架.作者是 ...
- caffe: fuck compile error again : error: a value of type "const float *" cannot be used to initialize an entity of type "float *"
wangxiao@wangxiao-GTX980:~/Downloads/caffe-master$ make -j8find: `wangxiao/bvlc_alexnet/spl': No suc ...
- CAFFE中训练与使用阶段网络设计的不同
神经网络中,我们通过最小化神经网络来训练网络,所以在训练时最后一层是损失函数层(LOSS), 在测试时我们通过准确率来评价该网络的优劣,因此最后一层是准确率层(ACCURACY). 但是当我们真正要使 ...
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
- 利用Caffe训练模型(solver、deploy、train_val)+python使用已训练模型
本文部分内容来源于CDA深度学习实战课堂,由唐宇迪老师授课 如果你企图用CPU来训练模型,那么你就疯了- 训练模型中,最耗时的因素是图像大小size,一般227*227用CPU来训练的话,训练1万次可 ...
随机推荐
- 2019.03.20 读书笔记 关于Reflect与Emit的datatable转list的效率对比
Reflect public static List<T> ToListByReflect<T>(this DataTable dt) where T : new() { Li ...
- MAYA删除不干净
AUTODESK系列软件着实令人头疼,安装失败之后不能完全卸载!!!(比如maya,cad,3dsmax等).有时手动删除注册表重装之后还是会出现各种问题,每个版本的C++Runtime和.NET f ...
- Windows 10 JDK安装及环境配置(vim+gcc)
JDK安装 首先去官网下载JDK:点击进入 下载后点击安装: 中途会提示安装jre,注意jre的安装文件夹和jdk的不能相同,不然会覆盖掉jdk里面的jre文件.可以创建一个Java文件夹.将jdk和 ...
- ToDictionary写法
把List集合转化成Dictionary public ActionResult Dimo() { Dictionary<string, Object> param = new Dicti ...
- Oracle 求昨天 上个月 去年 日期
到公司发现有一个报表没有收到,查看后发现原来是Oracle数据源异常. ' day, 'yyyyMMdd') AS enddata FROM DUAL; 上面这个sql求上个月今天和昨天.一般情况下不 ...
- Snipaste的详细安装和使用
Snipaste安装和使用 1:snipaste的安装 步骤一: https://zh.snipaste.com/ ,去此官网下载. 步骤二:由于此是个绿色软件,直接解压即可. 步骤三:使用,见官网 ...
- FAT12格式的引导区实现
org 07c00h ;================================================ jmp short START nop ; 这个 nop 不可少 ;这个结构将 ...
- 栅格那点儿事(四D)
统计值与空值 在上一篇的内容里反复提到了一个统计值.那这个统计值是怎么来的,具体是干嘛用的呢? 统计值主要就是用于栅格数据的显示和重分类,顾名思义就是一个波段中所有像元值的一个统计信息,最大值,最小值 ...
- 关于 IntelliJ IDEA 的Maven 版本修改
Project Structure->Project里Project sdk以及project language level Project Structure->Modules里Sour ...
- 磁盘空间满了之后MySQL会怎样
大多数用户在对于磁盘进行分区的时候都是习惯性的不给系统盘预留很大空间,其实这并不是一个好习惯.因为系统分区并不像我们想象的那样会仅仅安装一个操作系统,系统分区多数还是会承载操作系统主要应用软件安装任务 ...