浅析Java源码之HashMap外传-红黑树Treenode(已鸽)
(这篇文章暂时鸽了,有点理解不能,点进来的小伙伴可以撤了)
刚开始准备在HashMap中直接把红黑树也过了的,结果发现这个类不是一般的麻烦,所以单独开一篇。
由于红黑树之前完全没接触过,所以这篇博客相当于探索(其实之前的博客都是边看源码边写的,全是探索)。
红黑树没见过,树我还是知道的,所以先上一张帅图:
红黑树在这个基本树的基础上还多了red,暂时不知道啥意思,慢慢探索。
先来一个类总览:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
// ...
}
这个红黑树继承了一个另外一个类中的静态内部类:
static class Entry<K,V> extends HashMap.Node<K,V> {}
这个类也继承了一个静态内部类,竟然是HashMap中的Node,真是无语的循环!
这些东西虽然绕来绕去,但是总的特性就是两个字:链表!!!!!!!!!
变量
废话不多说,首先来看一个这个类的内部变量:
// 父节点
TreeNode<K,V> parent;
// 左右子节点
TreeNode<K,V> left;
TreeNode<K,V> right;
// ???
TreeNode<K,V> prev;
// 红黑树的精髓 => red!
boolean red;
这些节点的意思都比较直接,按理讲在正常的树中只有父、左、右三个,这里的prev和red暂时不清楚干嘛用的。
构造函数
接下来是构造函数
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
super!然后我跑去看了下LinkedHashMap.Entry的构造函数,还是super!!!!
绕了一圈,最后还是回到了Node的构造函数,如下:
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
没啥好讲的。
需要注意的是,静态内部类都是作为工具来使用的,所以不从常规的添加节点、查询来讲解,直接从链表转红黑树的方法入手,看到什么方法讲什么方法,Let's go!
// tab为HashMap的数组
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
// 这里的this是需要树转换数组索引处的第一个链表元素
for (TreeNode<K,V> x = this, next; x != null; x = next) {
// 依次往上获取节点
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
// 第一个元素被设置为树的根节点
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
// 根据hash值的大小区分左右
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
// 当出现hash碰撞 暂时不管这个
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
// 这里的xp变成了root
TreeNode<K,V> xp = p;
// 这个表达式不加括号看起来真是恶心
// 根据dir判断root.left或者root.right是否为null
if ((p = (dir <= 0) ? p.left : p.right) == null) {
// 设置下一个元素的parent为root
x.parent = xp;
// 设置root的left或right
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
}
}
}
moveRootToFront(tab, root);
}
在前面的转换中,其实参数tab并没有用上,所以暂时只需要关注链表本身。
在balanceInsertion方法之前,只完成了两件事:
1、将链表的第一个元素设置为根节点
2、将第二个元素的hash与根节点做比较,然后设置根节点的left或right为该元素
画个帅图:
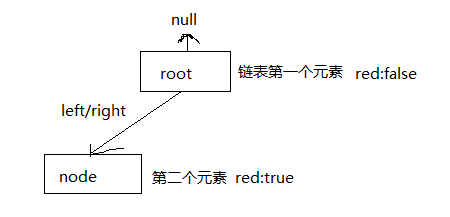
接下来看balanceInsertion方法做了什么,该方法接受两个参数:根节点、根节点的left(right)节点。
这个方法真长,让我深深的吸了一口气。
static <K, V> TreeNode<K, V> balanceInsertion(TreeNode<K, V> root,TreeNode<K, V> x) {
// 红属性
x.red = true;
// xp => x的父节点
// xpp => xp的父节点
// xppl => xpp.left
// xppr => xpp.right
for (TreeNode<K, V> xp, xpp, xppl, xppr;;) {
// 当x为根节点时
// 这时xp已经被赋值 xp => root
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
// 根节点red为false 所以直接返回root
else if (!xp.red || (xpp = xp.parent) == null)
return root;
// more code...
}
}
很遗憾,返回的特别快,这里的x为根节点的子节点,而根节点的父节点为null,所以这里直接返回root,返回后break,进入下一个循环。
总的来说,这个函数在第一次什么都没有做。
下一次循环时,x为链表中第三个元素,这里就存在一种新情况:dir的值。
首先当dir的值与上次不同时,我们假设在第二次判断中,x的hash值小于根节点root,于是dir为-1,这样就有:
xp.left = x;
而第三次,x的hash值比根节点大,而root.right此时仍为null,所以有
xp.right = x;
这样,根节点的两个儿子就集齐了。
另外一种情况就是dir的值与上次相同,此时p.left即root.left不为null,所以会进入下一轮内循环。此时的p不再是root,而是root.left,即第二个链表元素。
同样,第二个链表元素作为父节点与当前节点的hash作比较,然后设置对应的left/right。
此时,balanceInsertion函数就会进入下一个判断分支:
static <K, V> TreeNode<K, V> balanceInsertion(TreeNode<K, V> root,TreeNode<K, V> x) {
// 红属性
x.red = true;
for (TreeNode<K, V> xp, xpp, xppl, xppr;;) {
if ((xp = x.parent) == null) {/**/}
else if (!xp.red || (xpp = xp.parent) == null){/**/ }
// 此时xpp为root 父元素正好等于root.left
if (xp == (xppl = xpp.left)) {
// 此时xpp.right还没有值
if ((xppr = xpp.right) != null && xppr.red) {
// ...
} else {
if (x == xp.right) {
// ...
}
if (xp != null) {
// ...
}
}
} else {
// ...
}
}
}
这里的分支特别多。。。先看看当前的情况,并假设2次都是left,父、父父均无右节点,如图:

一个一个情况的讨论,反正基本的塞节点已经明白了。这种情况下,会进入如下分支:
if (xp == (xppl = xpp.left)) {
// 此时xpp.right还没有值
if ((xppr = xpp.right) != null && xppr.red) {
// ...
} else {
if (x == xp.right) {
// ...
}
if (xp != null) {
// 父节点黑了
xp.red = false;
if (xpp != null) {
// 父父节点红了
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
} else {
// ...
}
这种情况下,将父节点置黑,父父节点置红,并调用另外一个方法rotateRight。
直接看这个方法,接受两个参数:根节点、父父节点(还是root):
static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root,TreeNode<K,V> p) {
TreeNode<K,V> l, pp, lr;
if (p != null && (l = p.left) != null) {
// p.left = l.right
if ((lr = p.left = l.right) != null)
lr.parent = p;
// l.parent = p.parent
if ((pp = l.parent = p.parent) == null)
(root = l).red = false;
else if (pp.right == p)
pp.right = l;
else
pp.left = l;
l.right = p;
p.parent = l;
}
return root;
}
这个函数应该是叫做向右翻转红黑树,在理解的时候尽量不要把p当做根节点,而是一个普通的节点。
另外,这里就直接讲解各种情况下的翻转效果。
每一个if语句中的赋值都会改变树的结构,这里不太好讲,用图来一步一步解释,当前例子:

可见,翻转后,原来的root被转移到了l的右边,l变成了新的root且red被置false,函数返回新的root。
现在讨论更加普遍的情况,首先看在什么情况下会调用右翻转,将上一个函数中的第一个判断分支抽出如下:
// true
xp == (xppl = xpp.left)
// false
(xppr = xpp.right) != null && xppr.red
// true
xp != null
// true
xpp != null
false代表这是else分支。
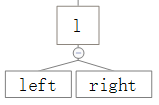
1、父元素为父父元素的left
2、父父元素的right为null或者父父元素的red为真
3、父元素及父父元素均不为null
很明显,上面的翻转符合这个条件,这里还有另外两种情况,即:
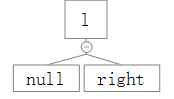 、
、
针对这两种情况的翻转给出对应的结果图:
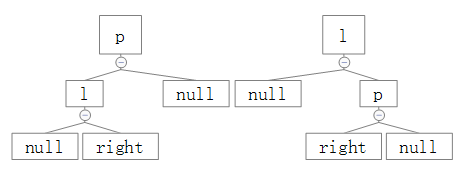 、
、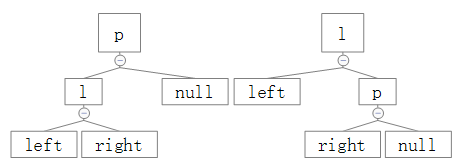
可以看出,在p为根节点时,l会被转换为新的根节点,并且有:
l.right = p;
p.left = l.right
然而,在p不为根节点时,情况稍微会不一样:
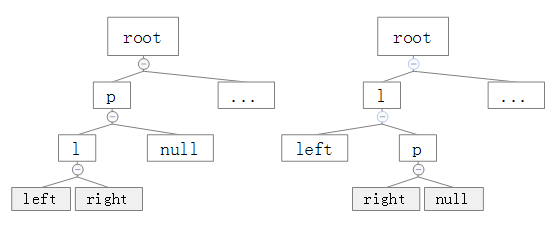
这种情况下不会根节点替换,仅仅是p与l进行换位。
下面来看第二个分支:
// false
xp == (xppl = xpp.left)
// false
xppl != null && xppl.red
// true
x == xp.left
即:
1、父元素为父父元素的right
2、父父元素的left为null或者red为真
3、当前元素为父元素的left
这里的参数不太一样:
root = rotateRight(root, x = xp);
直接看图吧!
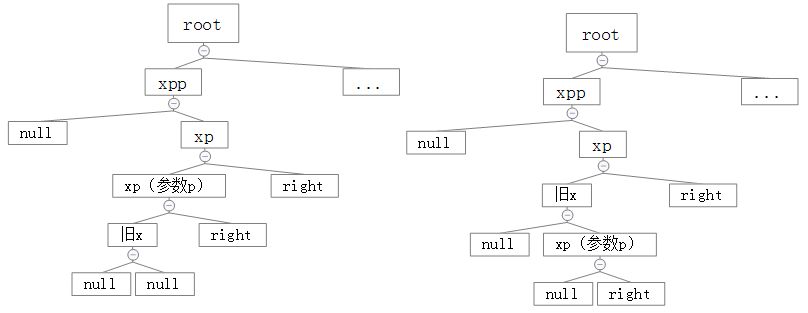
我要疯了!!!!
技术太渣,暂时不搞这个数据结构。。。
浅析Java源码之HashMap外传-红黑树Treenode(已鸽)的更多相关文章
- 浅析Java源码之HashMap
写这篇文章还是下了一定决心的,因为这个源码看的头疼得很. 老规矩,源码来源于JRE1.8,java.util.HashMap,不讨论I/O及序列化相关内容. 该数据结构简介:使用了散列码来进行快速搜索 ...
- JAVA源码分析-HashMap源码分析(一)
一直以来,HashMap就是Java面试过程中的常客,不管是刚毕业的,还是工作了好多年的同学,在Java面试过程中,经常会被问到HashMap相关的一些问题,而且每次面试都被问到一些自己平时没有注意的 ...
- Java源码学习:HashMap实现原理
AbstractMap HashMap继承制AbstractMap,很多通用的方法,比如size().isEmpty(),都已经在这里实现了.来看一个比较简单的方法,get方法: public V g ...
- Java源码之HashMap
一.HashMap和Hashtable的区别 (1)HashMapl的键值(key)和值(value)可以为null,而Hashtable不可以 (2)Hashtable是线程安全类,而HashMap ...
- Java源码阅读HashMap
1类签名与注释 public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cl ...
- Java源码解析|HashMap的前世今生
HashMap的前世今生 Java8在Java7的基础上,做了一些改进和优化. 底层数据结构和实现方法上,HashMap几乎重写了一套 所有的集合都新增了函数式的方法,比如说forEach,也新增了很 ...
- JAVA源码分析-HashMap源码分析(二)
本文继续分析HashMap的源码.本文的重点是resize()方法和HashMap中其他的一些方法,希望各位提出宝贵的意见. 话不多说,咱们上源码. final Node<K,V>[] r ...
- 浅析Java源码之ArrayList
面试题经常会问到LinkedList与ArrayList的区别,与其背网上的废话,不如直接撸源码! 文章源码来源于JRE1.8,java.util.ArrayList 既然是浅析,就主要针对该数据结构 ...
- 【数据结构】8.java源码关于HashMap
1.hashmap的底层数据结构 众所皆知map的底层结构是类似邻接表的结构,但是进入1.8之后,链表模式再一定情况下又会转换为红黑树在JDK8中,当链表长度达到8,并且hash桶容量超过64(MIN ...
随机推荐
- Linux-用户及权限
1. 用户组 RHEL 7/CentOS 7系统中的用户组有如下3类: 超级用户,UID 0:系统的超级用户. 系统用户,UID 1-999:系统中系统服务由不同用户运行,更加安全,默认被限制不能登录 ...
- Gimp RGB 转 CMYK
安装GIMP separate+插件.在Windows的Photoshop中,有转换CMYK的功能,非常简单.在Linux里,通常用GIMP进行转换.由于授权的问题,默认安装的GIMP里没有安装转换的 ...
- NODE-WEBKIT教程(5)NATIVE UI API 之FRAMELESS WINDOW
node-webkit教程(5)Native UI API 之Frameless window 文/玄魂 原文链接:http://www.xuanhun521.com/Blog/2014/4/15/n ...
- MySQL--binlog和relay log的生成和删除
##================================================================================================== ...
- GridControl简单属性操作
1.单行记录整行选中 GridView->OptionsBehavior->EditorShowMode 设置为:Click 2.如何让行只能选择而不能编辑(或编辑某一单元格) 只读 Gr ...
- 3.翻译:EF基础系列--EF怎么工作的?
原文链接:http://www.entityframeworktutorial.net/basics/how-entity-framework-works.aspx 这里,你将会大概了解到EF是怎么工 ...
- 201621123018《Java程序设计》第5周学习报告
1. 本周学习总结 1.1 写出你认为本周学习中比较重要的知识点关键词 接口.interface.implements.Comparable.Comparator. 1.2 尝试使用思维导图将这些关键 ...
- 模拟ssh、黏包、hashlib模块
一.模拟ssh 1.subprocess模块 ipconfig -all dir subprocess模块是python从2.4版本开始引入的模块.主要用来取代 一些旧的模块方法,如os.system ...
- java String 内存模型
关于java的内存模型,参照以下的一篇文章: https://isudox.com/2016/06/22/memory-model-of-string-in-java-language/
- mybatis 控制台打印执行的SQL语句
1. Spring boot 集成 mybatis [转载]SpringBoot中Mybatis打印sql 1.1 如果使用的是application.properties文件,加入如下配置: log ...