StanFord ML 笔记 第六部分&&第七部分
第六部分内容:
1.偏差/方差(Bias/variance)
2.经验风险最小化(Empirical Risk Minization,ERM)
3.联合界(Union bound)
4.一致收敛(Uniform Convergence)
第七部分内容:
1. VC 维
2.模型选择(Model Selection)
2017.11.3注释:这两个部分都是讲述理论过程的,第一方面太难了,第二方面现在只想快速理解Ng的20节课程。所以这部分以后回头再看!
2017.11.4注释:这理论还是得掌握,不然看Ng视频干嘛?直接去操作TF算了啊。。。。
1.偏差/方差(Bias/variance)
https://www.gitbook.com/book/yoyoyohamapi/mit-ml/details,这个是比较简单的,偷懒不写了。
2.经验风险最小化(Empirical Risk Minization,ERM)
定义一个线性分类器
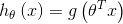
其中  (note
(note  )
)
假设有m个训练样本,样本之间是独立同分布的。
定义训练误差:
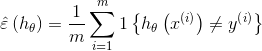
训练误差也被称为风险。
经验风险最小化: 选择分类器函数的参数,使得分类器的训练误差(training error)最小。

让我们换一种考虑方式:我们不是在选择最优分类器函数的参数,而是在选择最优的分类器函数。
定义假设类

假设类的每一个成员都是参数n+1个的线性分类器函数。
重新定义ERM:从假设类H中选取一个函数,使得分类器的训练误差最小。

实际上,我们并不关心训练误差的大小,我们关心的是分类器对于未知样本的预测能力,也就是一般误差(generation error):

3.联合界(Union bound)
注释:这里的两个定理证明很麻烦,直接用就可以了,联合界定理很简单不用叙述,Hoeffding 不等式表示试验次数越多均值越趋向真实的值,比如实验10000次硬币,那就正反的比例为1:1。
3.1.联合界引理(Union Bound):
令  表示k个事件,这些事件不一定是独立的,
表示k个事件,这些事件不一定是独立的,
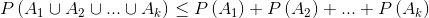
3.2.Hoeffding 不等式:
假设Z1,…,Zm为m个独立同分布(iid,independent and identically distributed)的随机变量,服从于伯努利分布,即


并且
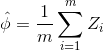
为这些随机变量的均值,给定  ,那么有
,那么有

表达的是对真实分布的估计值与真实分布之间的差值大于 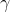 的概率的上界,这个上界随着m的增加而指数下降。
的概率的上界,这个上界随着m的增加而指数下降。
考虑具有有限假设类的情形: 猜想类H具有k个假设
猜想类H具有k个假设
ERM会从H中选出具有最小训练误差的假设

注释:对Hoeffding 不等式的简单解释如下-->>
Hoeffding不等式是关于一组随机变量均值的概率不等式。 如果X1,X2,⋯,Xn为一组独立同分布的参数为p的伯努利分布随机变量,n为随机变量的个数。定义这组随机变量的均值为:

对于任意δ>0, Hoeffding不等式可以表示为

上面的公式似乎写的不是很详细,所以我又从网上copy了一份其他的解释:
Hoeffding不等式:Hoeffding不等式好像有很多个形式,all of statistics里的感觉较难理解,这里写一种好理解的。令X1,…,Xn为独立同分布随机变量,满足ai≤Xi≤bi。则对于任意t>0有

其中:
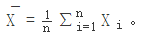
至于这个公式怎么证明,就不要为难自己了~
而这个公式的用途:
在统计推断中,我们可以利用样本的统计量(statistic)来推断总体的参数(parameter),譬如使用样本均值来估计总体期望。如下图所示,我们从罐子里抽球,希望估计罐子里红球和绿球的比例。

直觉上,如果我们有更多的样本(抽出更多的球),则样本期望ν应该越来越接近总体期望μ。事实上,这里可以用hoeffding不等式表示如下:

从hoeffding不等式可以看出,当n逐渐变大时,不等式的UpperBound越来越接近0,所以样本期望越来越接近总体期望。
4.一致收敛(Uniform Convergence)
4.1. 训练误差是一个对一般误差的很好的近似
首先证明第一项,从猜想类H中任意选取一个假设  ,定义
,定义
 服从伯努利分布,因此
服从伯努利分布,因此
 其均值是假设的一般误差。
其均值是假设的一般误差。
训练误差为

由Hoeffding不等式可知

假设m很大,即训练样本很多,那么训练误差将会以很大概率近似于一般误差。
定义事件  为
为  发生
发生
有

那么对于整个猜想类来说

= 

两边同时用1减去



也就是说,在不小于  的概率下,对于猜想类H中的所有假设h,其训练误差和一般误差之间的差距将会在
的概率下,对于猜想类H中的所有假设h,其训练误差和一般误差之间的差距将会在 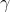 以内。
以内。
这被称为 一致收敛。
4.2. ERM选择的假设的一般误差存在上界
定义
那么给定  和
和 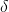 解出
解出


意思是,只要你的训练集合包含至少上述m这么多的样本,那么概率至少在  下,有
下,有  对H中的所有假设成立。
对H中的所有假设成立。
样本复杂度:为了达到一个特定的错误的界,你需要多大的训练集合。
误差界:
同样的,我们可以固定m和

定义 为H中具有最小一般误差的假设,
为H中具有最小一般误差的假设, 为H中具有最小训练误差的假设,那么至少在
为H中具有最小训练误差的假设,那么至少在  的概率下,有
的概率下,有






也就是说,我们选择的(具有最小训练误差的)假设的一般误差,和具有最小一般误差的假设的一般误差之间的差值存在  的上界。
的上界。
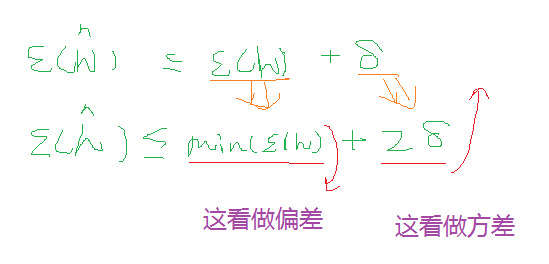
直观上,我们可以把第一项  看成是选择假设的偏差,第二项
看成是选择假设的偏差,第二项  看成选择假设的方差。
看成选择假设的方差。
当我们将H替换为更复杂的猜想类H',即H是H'的子集时,第一项只会变的更小,即偏差变小;而由于k的增大,第二项会变的更大,即方差变大。
将一切总结为两个定理如下:


第七部分:
7.1VC维空间,VC界讲的很棒
7.2模型选择
7.1.1.交叉验证
训练和测试相互参照
7.1.2特征选择
控制变量,去观察别的变量对结果的影响
7.1.3特征过滤
计算特征Xi和Y的相关程度,然后再通过交叉验证去排除
参考:http://blog.csdn.net/u013656184/article/details/50178573
http://www.cnblogs.com/madrabbit/p/7095575.html#undefined
StanFord ML 笔记 第六部分&&第七部分的更多相关文章
- StanFord ML 笔记 第三部分
第三部分: 1.指数分布族 2.高斯分布--->>>最小二乘法 3.泊松分布--->>>线性回归 4.Softmax回归 指数分布族: 结合Ng的课程,在看这篇博文 ...
- StanFord ML 笔记 第八部分
第八部分内容: 1.正则化Regularization 2.在线学习(Online Learning) 3.ML 经验 1.正则化Regularization 1.1通俗解释 引用知乎作者:刑无刀 ...
- StanFord ML 笔记 第五部分
1.朴素贝叶斯的多项式事件模型: 趁热打铁,直接看图理解模型的意思:具体求解可见下面大神给的例子,我这个是流程图. 在上篇笔记中,那个最基本的NB模型被称为多元伯努利事件模型(Multivariate ...
- StanFord ML 笔记 第一部分
本章节内容: 1.学习的种类及举例 2.线性回归,拟合一次函数 3.线性回归的方法: A.梯度下降法--->>>批量梯度下降.随机梯度下降 B.局部线性回归 C.用概率证明损失函数( ...
- StanFord ML 笔记 第十部分
第十部分: 1.PCA降维 2.LDA 注释:一直看理论感觉坚持不了,现在进行<机器学习实战>的边写代码边看理论
- StanFord ML 笔记 第九部分
第九部分: 1.高斯混合模型 2.EM算法的认知 1.高斯混合模型 之前博文已经说明:http://www.cnblogs.com/wjy-lulu/p/7009038.html 2.EM算法的认知 ...
- StanFord ML 笔记 第四部分
第四部分: 1.生成学习法 generate learning algorithm 2.高斯判别分析 Gaussian Discriminant Analysis 3.朴素贝叶斯 Navie Baye ...
- StanFord ML 笔记 第二部分
本章内容: 1.逻辑分类与回归 sigmoid函数概率证明---->>>回归 2.感知机的学习策略 3.牛顿法优化 4.Hessian矩阵 牛顿法优化求解: 这个我就不记录了,看到一 ...
- Android群英传笔记——第六章:Android绘图机制与处理技巧
Android群英传笔记--第六章:Android绘图机制与处理技巧 一直在情调,时间都是可以自己调节的,不然世界上哪有这么多牛X的人 今天就开始读第六章了,算日子也刚好一个月了,一个月就读一半,这效 ...
随机推荐
- Hadoop Mapreduce 案例 wordcount+统计手机流量使用情况
mapreduce设计思想 概念:它是一个分布式并行计算的应用框架它提供相应简单的api模型,我们只需按照这些模型规则编写程序,即可实现"分布式并行计算"的功能. 案例一:word ...
- Flume连接oracle实时推送数据到kafka
版本号: RedHat6.5 JDK1.8 flume-1.6.0 kafka_2.11-0.8.2.1 flume安装 RedHat6.5安装单机flume1.6:RedHat6.5安 ...
- switch case语句重点概况
witch-case语句格式如下: switch(变量){ case 变量值1: //; break; case 变量值2: //...; break; ... case default: //... ...
- STL基础--容器
容器种类 序列容器(数组,链表) Vector, deque, list, forward list, array 关联容器(二叉树),总是有序的 set, multiset根据值排序,元素值不能修改 ...
- Javascript中的词法作用域、动态作用域、函数作用域和块作用域(四)
一.js中的词法作用域和动态作用域 词法作用域也就是在词法阶段定义的作用域,也就是说词法作用域在代码书写时就已经确定了. js中其实只有词法作用域,并没有动态作用域,this的执 ...
- mac nginx 安装教程
eeking a satisfactory solution to create a local web server for programming in macOS with PHP and My ...
- PAT 乙级 1031 查验身份证(15) C++版
1031. 查验身份证(15) 时间限制 200 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 CHEN, Yue 一个合法的身份证号码由17位地区. ...
- react表单事件和取值
常见的表单包括输入框,单选框,复选框,下拉框和多文本框,本次主要总结它们在react中如何取值. 输入框 在之前有说过输入框,可以先给input框的value绑定一个值,然后通过input框的改变事件 ...
- acl的基本知识点
#ACL acl number 3001 rule 1 deny udp destination-port eq 445 rule 2 deny tcp destination-por ...
- docker镜像文件的导入与导出(docker镜像迁移)
1.查看镜像ID # docker images [root@localhost ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE myto ...