Pyspider抓取静态页面
近期,我想爬一批新闻资讯的内容。新闻类型的网址很多,我想看看有没有一个网页上能包罗尽可能多的新闻网站呢,于是就发现了下面这个网页
http://news.hao123.com/wangzhi
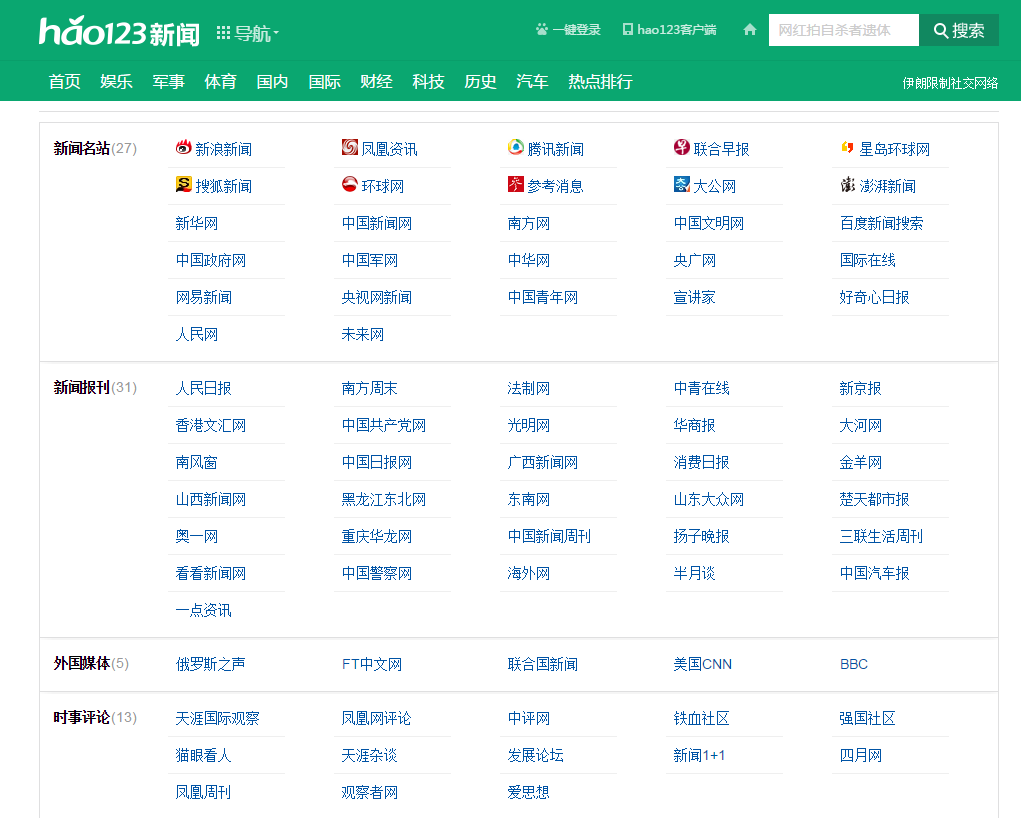
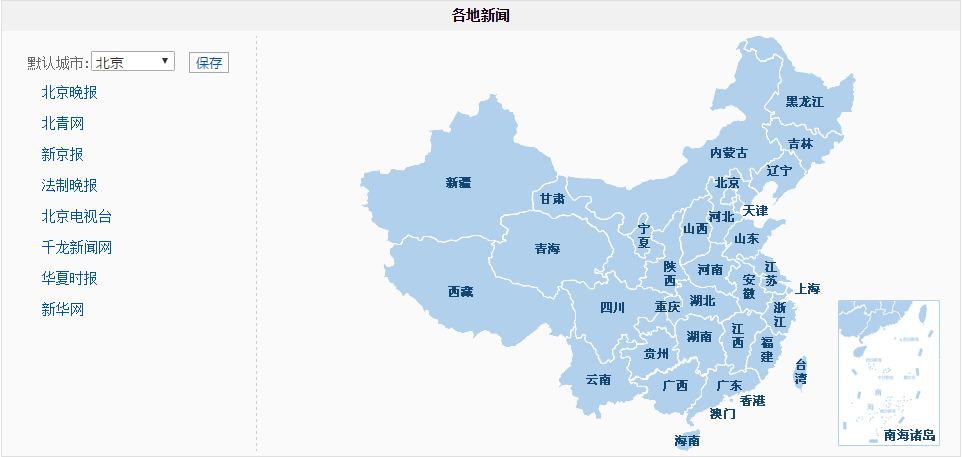
这个页面的下边还有地方新闻的分类
1、爬取目标
按类型分的网址列表
按地方分的网址列表
2、按类型
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-01-02 15:44:54
# Project: financeNews from pyspider.libs.base_handler import * class Handler(BaseHandler):
crawl_config = {
} def __init__(self):
self.url = 'http://news.hao123.com/wangzhi' @every(minutes=24 * 60)
def on_start(self):
self.crawl(self.url,callback=self.index_page) @config(age=10 * 24 * 60 * 60)
def index_page(self, response): return [{
"group" : x('.content-title').text(),
"websites" : [a.text() for a in x('li a').items()]
} for x in response.doc('.mod-content').items()]
运行结果

3、按地方
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-01-02 15:44:54
# Project: financeNews from pyspider.libs.base_handler import * class Handler(BaseHandler):
crawl_config = {
} def __init__(self):
self.url = 'http://news.hao123.com/wangzhi' @every(minutes=24 * 60)
def on_start(self):
self.crawl(self.url,callback=self.index_page) @config(age=10 * 24 * 60 * 60)
def index_page(self, response): return [{
"city" : x.attr('id')[5:],
"websites" : [a.text() for a in x('li a').items()]
} for x in response.doc('.page').items()]
运行结果

4、知识点小结
4.1 __init__()方法为对象创建完成后的初始化方法,自动执行,可以自定义一些全局属性
4.2 "city" : x.attr('id')[5:]
取属性id的值,并从第6个字符截取
4.3 可以在return中多级遍历,数组套数组
4.4 pyspider提供了元素选择帮助功能,可以快捷选取元素,但不是非常精确
Pyspider抓取静态页面的更多相关文章
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写 ...
- Python爬虫之一 PySpider 抓取淘宝MM的个人信息和图片
ySpider 是一个非常方便并且功能强大的爬虫框架,支持多线程爬取.JS动态解析,提供了可操作界面.出错重试.定时爬取等等的功能,使用非常人性化. 本篇通过做一个PySpider 项目,来理解 Py ...
- 利用curl抓取远程页面内容
最基本的操作如下 $curlPost = 'a=1&b=2';//模拟POST数据$cookie_file = tempnam('./temp','kie');//可选,保存ses ...
- php curl抓取远程页面内容的代码
使用php curl抓取远程页面内容的例子. 代码如下: <?php /** * php curl抓取远程网页内容 * edit by www.jbxue.com */ $curlPost = ...
- php抓取ajax页面返回图片。
要抓取的页面:http://pic.hao123.com/ 当我们往下滚动的时候,图片是用ajax来动态获取的.这就需要我们仔细分析页面了. 可以看到,异步加载的ajax文件为: http://pic ...
- C#抓取AJAX页面的内容
原文 C#抓取AJAX页面的内容 现在的网页有相当一部分是采用了AJAX技术,所谓的AJAX技术简单一点讲就是事件驱动吧(当然这种说法可能很不全面),在你提交了URL后,服务器发给你的并不是所有是页面 ...
- Scrapy爬取静态页面
Scrapy爬取静态页面 安装Scrapy框架: Scrapy是python下一个非常有用的一个爬虫框架 Pycharm下: 搜索Scrapy库添加进项目即可 终端下: #python2 sudo p ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 用C#抓取AJAX页面的内容
现在的网页有相当一部分是采用了AJAX技术,不管是采用C#中的WebClient还是HttpRequest都得不到正确的结果,因为这些脚本是在服务器发送完毕后才执行的! 但我们用IE浏览页面时是正常的 ...
随机推荐
- 撩课-Web大前端每天5道面试题-Day33
1.CommonJS 中的 require/exports 和 ES6 中的 import/export 区别? CommonJS 模块的重要特性是加载时执行, 即脚本代码在 require 的时候, ...
- VM虚拟机克隆_修改网络
1.如果网络中没有VMware的网卡,记得重置即可 2.如果右上角没有了网络图标,直接 server NetworkManager restart 3.网络配置 1)在/etc/sysconfig/n ...
- 创建Cordova项目 报错Error: Unhandled "error" event
cordova版本7.0以上版本 创建cordova项目错误信息 Error: Unhandled "error" event. ( Error from Cordova Fet ...
- AMD与CMD的异同
AMD与CMD的异同? 1.从官方推荐的写法上面得出: CMD ----- 依赖就近 //CMD define(function(require,exports,module){ var a = re ...
- phpadmin登录报错:#1045 - Access denied for user 'root'@'localhost' (using password: yes)
原因:phpmyadmin无法通过root+密码联系mysql; 解决方法:重置mysql密码. 步骤: 1.cmd 2.登录MySQL:mysql -uroot -p ->root是用户 ...
- jquery判断浏览器的内核
<script type='text/javascript'> $(function(){ if($.browser.msie) { alert("IE浏览器"); } ...
- Hadoop大数据初入门----haddop伪分布式安装
一.hadoop解决了什么问题 hdfs 解决了海量数据的分布式存储,高可靠,易扩展,高吞吐量mapreduce 解决了海量数据的分析处理,通用性强,易开发,健壮性 yarn 解决了资源管理调度 二. ...
- <Android 基础(三十五)> RecyclerView多类型Item的正确实现姿势
简介 RecyclerView是我们开发过程中经常使用到的一个元素,原生的RecyclerView.Adapter基本上可以满足一般的需求,关于RecyclerView的基础介绍请移步: Recycl ...
- MaxScript与外部程序通讯
最近项目要求通过java给max发送任务指令,max接收指令执行任务,并且返回执行的结果.不管为什么会有这样的需求,有就要去实现. 1.OLE开启 Max本身提供了一个方式,它可以将自己注册成一个Ol ...
- AOP编程 - 淘宝京东网络处理
现象描述 当我们打开京东 app 进入首页,如果当前是没有网络的状态,里面的按钮点击是没有反应的.只有当我们打开网络的情况下,点击按钮才能跳转页面,按照我们一般人写代码的逻辑应该是这个样子: /** ...