Bias(偏差),Error(误差),和Variance(方差)的区别和联系
准:
bias描述的是根据样本拟合出的模型的输出预测结果的期望与样本真实结果的差距,简单讲,就是在样本上拟合的好不好。要想在bias上表现好,low bias,就得复杂化模型,增加模型的参数,但这样容易过拟合 (overfitting),过拟合对应上图是high variance,点很分散。low bias对应就是点都打在靶心附近,所以瞄的是准的,但手不一定稳。
确:
varience描述的是样本上训练出来的模型在测试集上的表现,要想在variance上表现好,low varience,就要简化模型,减少模型的参数,但这样容易欠拟合(unfitting),欠拟合对应上图是high bias,点偏离中心。low variance对应就是点都打的很集中,但不一定是靶心附近,手很稳,但是瞄的不准。
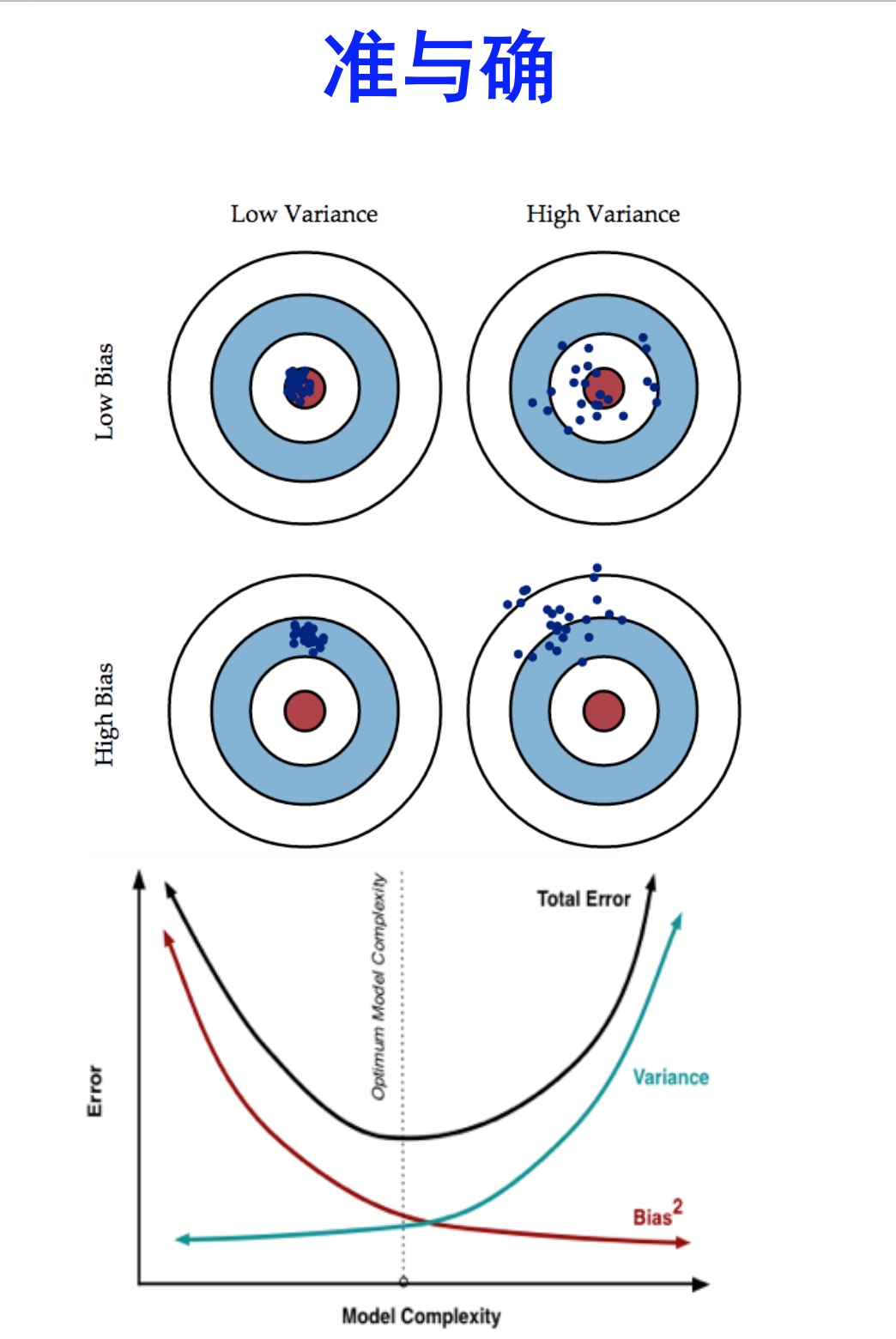
这个靶子上的点(hits)可以理解成一个一个的拟合模型,如果许多个拟合模型都聚集在一堆,位置比较偏,如图中 high bias low variance 这种情景,意味着无论什么样子的数据灌进来,拟合的模型都差不多,这个模型过于简陋了,参数太少了,复杂度太低了,这就是欠拟合;但如果是图中 low bias high variance 这种情景,你看,所有拟合模型都围绕中间那个 correct target 均匀分布,但又不够集中,很散,这就意味着,灌进来的数据一有风吹草动,拟合模型就跟着剧烈变化,这说明这个拟合模型过于复杂了,不具有普适性,就是过拟合。
所以bias和variance的选择是一个tradeoff,过高的variance对应的概念,有点『剑走偏锋』『矫枉过正』的意思,如果说一个人variance比较高,可以理解为,这个人性格比较极端偏执,眼光比较狭窄,没有大局观。而过高的bias对应的概念,有点像『面面俱到』『大巧若拙』的意思,如果说一个人bias比较高,可以理解为,这个人是个好好先生,谁都不得罪,圆滑世故,说话的时候,什么都说了,但又好像什么都没说,眼光比较长远,有大局观。
链接:https://www.zhihu.com/question/27068705/answer/82132134
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先明确一点,Bias和Variance是针对Generalization(一般化,泛化)来说的。
在机器学习中,我们用训练数据集去训练(学习)一个model(模型),通常的做法是定义一个Loss function(误差函数),通过将这个Loss(或者叫error)的最小化过程,来提高模型的性能(performance)。然而我们学习一个模型的目的是为了解决实际的问题(或者说是训练数据集这个领域(field)中的一般化问题),单纯地将训练数据集的loss最小化,并不能保证在解决更一般的问题时模型仍然是最优,甚至不能保证模型是可用的。这个训练数据集的loss与一般化的数据集的loss之间的差异就叫做generalization error。
而generalization error又可以细分为Bias和Variance两个部分。
首先如果我们能够获得所有可能的数据集合,并在这个数据集合上将loss最小化,这样学习到的模型就可以称之为“真实模型”,当然,我们是无论如何都不能获得并训练所有可能的数据的,所以“真实模型”肯定存在,但无法获得,我们的最终目标就是去学习一个模型使其更加接近这个真实模型。
而bias和variance分别从两个方面来描述了我们学习到的模型与真实模型之间的差距。
Bias是 “用所有可能的训练数据集训练出的所有模型的输出的平均值” 与 “真实模型”的输出值之间的差异;
Variance则是“不同的训练数据集训练出的模型”的输出值之间的差异。
这里需要注意的是我们能够用来学习的训练数据集只是全部数据中的一个子集。想象一下我们现在收集几组不同的数据,因为每一组数据的不同,我们学习到模型的最小loss值也会有所不同,当然,它们与“真实模型”的最小loss也是不一样的。
其他答主有提到关于cross validation中k值对bias和variance的影响,那我就从其他方面来举个例子。
假设我们现在有一组训练数据,需要训练一个模型(基于梯度的学习,不包括最近邻等方法)。在训练过程的最初,bias很大,因为我们的模型还没有来得及开始学习,也就是与“真实模型”差距很大。然而此时variance却很小,因为训练数据集(training data)还没有来得及对模型产生影响,所以此时将模型应用于“不同的”训练数据集也不会有太大差异。
而随着训练过程的进行,bias变小了,因为我们的模型变得“聪明”了,懂得了更多关于“真实模型”的信息,输出值与真实值之间更加接近了。但是如果我们训练得时间太久了,variance就会变得很大,因为我们除了学习到关于真实模型的信息,还学到了许多具体的,只针对我们使用的训练集(真实数据的子集)的信息。而不同的可能训练数据集(真实数据的子集)之间的某些特征和噪声是不一致的,这就导致了我们的模型在很多其他的数据集上就无法获得很好的效果,也就是所谓的overfitting(过学习)。
因此,在实际的训练过程中会用到validation set,会用到诸如early stopping以及regularization等方法来避免过学习的发生,然而没有一种固定的策略方法适用于所有的task和data,所以bias和variance之间的tradeoff应该是机器学习永恒的主题吧。
最后说一点,从bias和variance的讨论中也可以看到data对于模型训练的重要性,假如我们拥有全部可能的数据,就不需要所谓的tradeoff了。但是既然这是不现实的,那么尽量获取和使用合适的数据就很重要了。
链接:https://www.zhihu.com/question/27068705/answer/35151681
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Error = Bias + Variance + Noise
Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。
举一个例子,一次打靶实验,目标是为了打到10环,但是实际上只打到了7环,那么这里面的Error就是3。具体分析打到7环的原因,可能有两方面:一是瞄准出了问题,比如实际上射击瞄准的是9环而不是10环;二是枪本身的稳定性有问题,虽然瞄准的是9环,但是只打到了7环。那么在上面一次射击实验中,Bias就是1,反应的是模型期望与真实目标的差距,而在这次试验中,由于Variance所带来的误差就是2,即虽然瞄准的是9环,但由于本身模型缺乏稳定性,造成了实际结果与模型期望之间的差距。
在一个实际系统中,Bias与Variance往往是不能兼得的。如果要降低模型的Bias,就一定程度上会提高模型的Variance,反之亦然。造成这种现象的根本原因是,我们总是希望试图用有限训练样本去估计无限的真实数据。当我们更加相信这些数据的真实性,而忽视对模型的先验知识,就会尽量保证模型在训练样本上的准确度,这样可以减少模型的Bias。但是,这样学习到的模型,很可能会失去一定的泛化能力,从而造成过拟合,降低模型在真实数据上的表现,增加模型的不确定性。相反,如果更加相信我们对于模型的先验知识,在学习模型的过程中对模型增加更多的限制,就可以降低模型的variance,提高模型的稳定性,但也会使模型的Bias增大。Bias与Variance两者之间的trade-off是机器学习的基本主题之一,机会可以在各种机器模型中发现它的影子。
具体到K-fold Cross Validation的场景,其实是很好的理解的。首先看Variance的变化,还是举打靶的例子。假设我把抢瞄准在10环,虽然每一次射击都有偏差,但是这个偏差的方向是随机的,也就是有可能向上,也有可能向下。那么试验次数越多,应该上下的次数越接近,那么我们把所有射击的目标取一个平均值,也应该离中心更加接近。更加微观的分析,模型的预测值与期望产生较大偏差,在模型固定的情况下,原因还是出在数据上,比如说产生了某一些异常点。在最极端情况下,我们假设只有一个点是异常的,如果只训练一个模型,那么这个点会对整个模型带来影响,使得学习出的模型具有很大的variance。但是如果采用k-fold Cross Validation进行训练,只有1个模型会受到这个异常数据的影响,而其余k-1个模型都是正常的。在平均之后,这个异常数据的影响就大大减少了。相比之下,模型的bias是可以直接建模的,只需要保证模型在训练样本上训练误差最小就可以保证bias比较小,而要达到这个目的,就必须是用所有数据一起训练,才能达到模型的最优解。因此,k-fold Cross Validation的目标函数破坏了前面的情形,所以模型的Bias必然要会增大。
为什么要用交叉验证(Cross-Validation)
1.交叉验证,这是仅使用训练集衡量模型性能的一个方便技术,不用建模最后才使用测试集
2.Cross-validation 是为了有效的估测 generalization error(泛化误差) 所设计的实验方法,而generalization error=bias+variance
首先:bias和variance分别从两个方面来描述了我们学习到的模型与真实模型之间的差距。Bias是 “用所有可能的训练数据集训练出的所有模型的输出的平均值” 与 “真实模型”的输出值之间的差异;Variance则是“不同的训练数据集训练出的模型”的输出值之间的差异。
作者:mrlevo520
链接:https://www.jianshu.com/p/8d01ac406b40
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
可以发现,怎么来平衡Bias和Variance则成了我们最大的任务了,也就是怎么合理的评估自己模型呢?我们由此提出了交叉验证的思想,以K-fold Cross Validation(记为K-CV)为例,基本思想如下:(其他更多方法请看@bigdataage --交叉验证(Cross-Validation))
将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标.K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2. 而K-CV 的实验共需要建立 k 个models,并计算 k 次 test sets 的平均辨识率。在实作上,k 要够大才能使各回合中的 训练样本数够多,一般而言 k=10 (作为一个经验参数)算是相当足够了。
看不清上面的就来一幅更简单的
每次的training_set 红色, validation_set白色 ,也就是说k=5的情况了
注意:交叉验证使用的仅仅是训练集!!根本没测试集什么事!很多博客都在误导!
这也就解决了上面刚开始说的Variance(不同训练集产生的差异),Bias(所有data训练结果的平均值)这两大问题了!因为交叉验证思想集合了这两大痛点,能够更好的评估模型好坏!
说白了,就是你需要用下交叉验证去试下你的算法是否精度够好,够稳定!你不能说你在某个数据集上表现好就可以,你做的模型是要放在整个数据集上来看的!毕竟泛化能力才是机器学习解决的核心
Bias、Variance和K-fold的关系
下面解释一下Bias、Variance和k-fold的关系:k-fold交叉验证常用来确定不同类型的模型(线性、指数等)哪一种更好,为了减少数据划分对模型评价的影响,最终选出来的模型类型(线性、指数等)是k次建模的误差平均值最小的模型。当k较大时,经过更多次数的平均可以学习得到更符合真实数据分布的模型,Bias就小了,但是这样一来模型就更加拟合训练数据集,再去测试集上预测的时候预测误差的期望值就变大了,从而Variance就大了;反之,k较小时模型不会过度拟合训练数据,从而Bias较大,但是正因为没有过度拟合训练数据,Variance也较小。
作者:TANGent
链接:https://www.zhihu.com/question/27068705/answer/35286205
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
作者:mrlevo520
链接:https://www.jianshu.com/p/8d01ac406b40
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
Bias(偏差),Error(误差),和Variance(方差)的区别和联系的更多相关文章
- 总结:Bias(偏差),Error(误差),Variance(方差)及CV(交叉验证)
犀利的开头 在机器学习中,我们用训练数据集去训练(学习)一个model(模型),通常的做法是定义一个Loss function(误差函数),通过将这个Loss(或者叫error)的最小化过程,来提高模 ...
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
前几天搜狗的一道笔试题,大意是在随机森林上增加一棵树,variance和bias如何变化呢? 参考知乎上的讨论:https://www.zhihu.com/question/27068705 另外可参 ...
- 主效应|处理误差 |组间误差|处理效应|随机误差|组内误差|误差|效应分析|方差齐性检验|SSE|SSA|SST|MSE|MSA|F检验|关系系数|完全随机化设计|区组设计|析因分析
8 什么是只考虑主效应的方差分析? 就是不考虑交互效应的方差分析,即认为因素之间是不相互影响的,就是无重复的方差分析. 什么是处理误差 (treatment error).组间误差(between ...
- Spark2 Dataset统计指标:mean均值,variance方差,stddev标准差,corr(Pearson相关系数),skewness偏度,kurtosis峰度
val df4=spark.sql("SELECT mean(age),variance(age),stddev(age),corr(age,yearsmarried),skewness(a ...
- 【debug、info、warn、error】四者之间的区别与用法
debug:需要在调试过程中输出的信息,但发布后是不需要的(当然发布后,也是看不到的) info:需要持续输出的信息(无论调试还是发布状态) warn:警告级别的信息(不严重) error:错误信息( ...
- Throwable、Error、Exception、RuntimeException的区别与联系
Throwable类是Java语言中所有错误和异常的超类.只有作为此类(或其子类之一)的实例的对象才被Java虚拟机抛出,或者可以被Java throw语句抛出.类似地,只有这个类或其子类之一可以是c ...
- 详解Java异常Throwable、Error、Exception、RuntimeException的区别
在Java中,根据错误性质将运行错误分为两类:错误和异常. 在Java程序的执行过程中,如果出现了异常事件,就会生成一个异常对象.生成的异常对象将传递Java运行时系统,这一异常的产生和提交过程称为抛 ...
- # ML学习小笔记—Where does the error come from?
关于本课程的相关资料http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17.html 错误来自哪里? error due to "bias" ...
- Understanding the Bias-Variance Tradeoff
Understanding the Bias-Variance Tradeoff When we discuss prediction models, prediction errors can be ...
随机推荐
- Linux 配置mail发送邮件
一.在/etc/mail.rc下添加如下内容 set from=lipingchang@pystandard.com set smtp=smtp.pystandard.com set smtp-aut ...
- 使用matplotlib绘制散点图
在matplotlib中使用函数 matplotlib.pyplot.scatter 绘制散点图,matplotlib.pyplot.scatter的函数签名如下: matplotlib.pyplot ...
- java学习之借书系统
实现的图书借阅系统要处理用户输入的非法参数,并引导用户正确使用 测试结果: 主要目的就是练习异常处理中的Exception类的使用 使用的相关语法 try{ //可能产生异常的代码块 }catch(E ...
- 2017, X Samara Regional Intercollegiate Programming Contest 题解
[题目链接] A - Streets of Working Lanterns - 2 首先将每一个括号匹配串进行一次缩减,即串内能匹配掉的就匹配掉,每个串会变成连续的$y$个右括号+连续$z$个左括号 ...
- JDK1.8快速入门
JDK8提供了非常多的便捷用法和语法糖,其编码效率几乎接近于C#开发,maven则是java目前为止最赞的jar包管理和build工具,这两部分内容都不算多,就合并到一起了. 愿编写java代码的过程 ...
- Orleans入门
一.Grains 二.开发一个Grain 三.开发一个客户端 四.运行应用程序 五.调式 一.Grains Grains是Orleans编程模型的关键原语. Grains是Orleans应用程序的构建 ...
- Android activity之间数据传递和共享的方式之Application
1.基于消息的通信机制 Intent ---bundle ,extra 数据类型有限,比如遇到不可序列化的数据Bitmap,InputStream,或者LinkedList链表等等数据类型就不太好用 ...
- java使用代理模拟http get请求
直接上代码: import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.InetSocketAd ...
- CentOS 7搭建KVM在线管理面板WebVirtMgr
系统版本:CentOS 7.4 WebVirtMgr版本:master分支的20180720版本,下载链接(链接:https://pan.baidu.com/s/1kl060hPHDGbwJUR_iM ...
- KL46 custom board SWD reset is never asserted - SWS Waveform
KL46 custom board SWD reset is never asserted Hi everybody, I'm trying to program a custom board bas ...