爬取指定网页的源代码显示在GUI中
建立一个GUI图形界面用来用来输入网址和代码显示的区域
#encoding=utf-8
__author__ = 'heng'
#创建一个可以抓取输入网址源代码的GUI
from urllib2 import urlopen
import wx
#建立爬取网页的函数
def capture(event):
webpage = urlopen(the_URL.GetValue())
contents.SetValue(webpage.read())
webpage.close() #首先建立图形界面 app = wx.App()
win = wx.Frame(None,title = "The Editor ",size = (500,500))
bkg = wx.Panel(win)
searchButton = wx.Button(bkg,label = "Search") #设置搜索按键
#开始调用搜索函数
searchButton.Bind(wx.EVT_BUTTON,capture) the_URL = wx.TextCtrl(bkg) #创建URL的文本输入框
contents = wx.TextCtrl(bkg,style = wx.TE_MULTILINE | wx.HSCROLL) hbox = wx.BoxSizer()
hbox.Add(the_URL,proportion = 1,flag = wx.EXPAND)
hbox.Add(searchButton,proportion = 0,flag = wx.LEFT,border = 5) bbox = wx.BoxSizer(wx.VERTICAL)
bbox.Add(hbox,proportion = 0,flag = wx.EXPAND | wx.ALL,border = 5)
bbox.Add(contents,proportion = 1,flag = wx.EXPAND| wx.LEFT|wx.RIGHT|wx.BOTTOM,border = 5) bkg.SetSizer(bbox)
win.Show()
app.MainLoop()
运行效果图
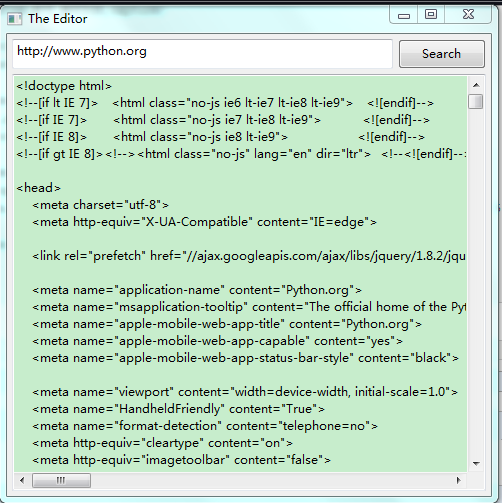
输入要爬取的网页之后点击search就可以开始爬取指定的网页。
爬取指定网页的源代码显示在GUI中的更多相关文章
- Python-定时爬取指定城市天气(二)-邮件提醒
目录 一.概述 二.模块重新划分 三.优化定时任务 四.发送邮件 五.源代码 一.概述 上一篇文章python-定时爬取指定城市天气(一)-发送给关心的微信好友中我们讲述了怎么定时爬取城市天气,并发送 ...
- Python-定时爬取指定城市天气(一)-发送给关心的微信好友
一.背景 上班的日子总是3点一线,家里,公司和上班的路径,对于一个特别懒得我来说,经常遇到上班路上下雨了,而我却没带伞,多么痛的领悟.最近对python有一种狂热的学习热情,写了4年多的C++代码,对 ...
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
- 利用爬虫爬取指定用户的CSDN博客文章转为md格式,目的是完成博客迁移博文到Hexo等静态博客
文章目录 功能 爬取的方式: 设置生成的md文件命名规则: 设置md文件的头部信息 是否显示csdn中的锚点"文章目录"字样,以及下面具体的锚点 默认false(因为csdn中是集 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- 使用htmlparse爬虫技术爬取电影网页的全部下载链接
昨天,我们利用webcollector爬虫技术爬取了网易云音乐17万多首歌曲,而且还包括付费的在内,如果时间允许的话,可以获取更多的音乐下来,当然,也有小伙伴留言说这样会降低国人的知识产权保护意识,诚 ...
- python使用requests库爬取网页的小实例:爬取京东网页
爬取京东网页的全代码: #爬取京东页面的全代码 import requests url="https://item.jd.com/2967929.html" try: r=requ ...
- 使用htmlparser爬虫技术爬取电影网页的全部下载链接
昨天,我们利用webcollector爬虫技术爬取了网易云音乐17万多首歌曲,而且还包括付费的在内,如果时间允许的话,可以获取更多的音乐下来,当然,也有小伙伴留言说这样会降低国人的知识产权保护意识,诚 ...
- Python 爬取单个网页所需要加载的地址和CSS、JS文件地址
Python 爬取单个网页所需要加载的URL地址和CSS.JS文件地址 通过学习Python爬虫,知道根据正式表达式匹配查找到所需要的内容(标题.图片.文章等等).而我从测试的角度去使用Python爬 ...
随机推荐
- docker-machine 快速搭建docker环境
环境:腾讯云测试成功 1.条件:本地主机A和远程主机B 2.远程主机B,配置免密登录 1,在本地主机A上生成公钥和私钥,生成命令:ssh-keygen -t rsa 私钥:id_rsa 公钥:id_r ...
- Go:channel
一.channel 在 Go 语言里,不仅可以使用原子函数和互斥锁来保证对共享资源的安全访问以及消除竞争状态,还可以使用 channel,通过发送和接收需要共享的资源,在 goroutine 之间做同 ...
- Django:调用css、image、js
1.在项目的manage.py同级目录创建static.templates 2.编辑settings.py,在最后加入 STATIC_URL = '/static/' HERE = os.path.d ...
- 配置工程文件dll编译后copy路径
放到工程文件的最后面的配置节点: 下面的配置节点中生成路径换成实际的相对路径就可以了 修改:Prject.csproj 文件里面的配置节点 project配置节点里面的最后面 <Target ...
- Oracle常用内置数据表查询
Oracle 查询库中所有表名.字段名.字段名说明,查询表的数据条数.表名.中文表名. 查询所有表名:select t.table_name from user_tables t;查询所有字段名:se ...
- 79. could not initialize proxy - no Session 【从零开始学Spring Boot】
[原创文章,转载请注明出处] Spring与JPA结合时,如何解决懒加载no session or session was closed!!! 实际上Spring Boot是默认是打开支持sessio ...
- 【转】关于大型网站技术演进的思考(二十)--网站静态化处理—web前端优化—中(12)
Web前端很多优化原则都是从如何提升网络通讯效率的角度提出的,但是这些原则使用的时候还是有很多陷阱在里面,如果我们不能深入理解这些优化原则背后所隐藏的技术原理,很有可能掉进这些陷阱里,最终没有达到最佳 ...
- [luoguP1947] 笨笨当粉刷匠_NOI导刊2011提高(10)(DP)
传送门 f[i][j][k]表示前i行,最后一行前j个,选k次最优解 ntr[i][j][2]表示当前行区间i~j涂0或1所能刷的正确格子 #include <cstdio> #defin ...
- Codeforces Round #277 (Div. 2 Only)
A:SwapSort http://codeforces.com/problemset/problem/489/A 题目大意:将一个序列排序,可以交换任意两个数字,但要求交换的次数不超过n,输出任意一 ...
- [Usaco2009 Open]工作安排Job
Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 1457 Solved: 687[Submit][Status][Discuss] Descriptio ...