【CV论文阅读】Detecting events and key actors in multi-person videos
论文主要介绍一种多人协作的视频事件识别的方法,使用attention模型+RNN网络,最近粗浅地学习了RNN网络,它比较适合用于处理序列的存在上下文作用的数据。
NCAA Basketball数据集
这个数据集是作者新构建的,一个事件4秒长度,在论文中共需识别11个事件。而且从训练集子集通过标注人物的bounding box学习了一个multibox detector,来识别所有帧中的人物bounding box。
RNN模型
论文使用了RNN模型中的LSTM来处理帧序列。网络的结构如下图,其中BLSTM代表双向的LSTM结构
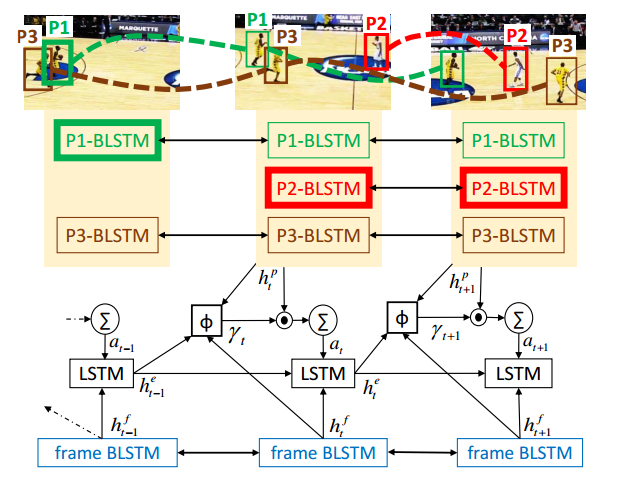
每个Pi-BLSTM跟踪每个人物帧序列中的状态,方框的厚度代表attention作为key人物的权值。
首先,每一帧提取1024维度的特征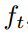 ,而对于每帧的每一个player,提取2805维特征(1440维位置spatial的信息以及1365维appearance信息)
,而对于每帧的每一个player,提取2805维特征(1440维位置spatial的信息以及1365维appearance信息)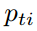 。首先使用BLSTM计算hidden state
。首先使用BLSTM计算hidden state 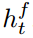 ,它保存了全局上下文的信息。计算式子如下
,它保存了全局上下文的信息。计算式子如下
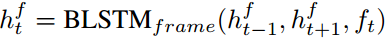
然后可以利用单向的LSTM计算事件状态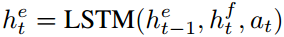
最后,对于每个事件k,都定义一个权向量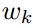 ,计算它们的内积
,计算它们的内积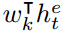 来确定事件的分类。误差函数可以定义:
来确定事件的分类。误差函数可以定义: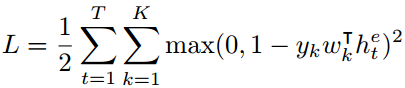
其中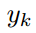 是对于视频原label,如果属于k则为1,否则为-1。
是对于视频原label,如果属于k则为1,否则为-1。
Attention 模型
Attention模型的主要作用在于识别主人物并增大他在计算event state中所起的作用,在这里会利用一个softmax函数来实现上述的功能。论文提出了两种思路,分别是对每个人物进行跟踪的模型以及不跟踪的模型。
跟踪模型
利用KTL tracker和图匹配找到每帧对应的人物,并为每个人物建立一个BLSTM网络,用于计算hidden state 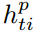 ,得
,得 。计算softmax函数分配每个人物在每一帧的权重,从而识别关键人物,如下计算
。计算softmax函数分配每个人物在每一帧的权重,从而识别关键人物,如下计算
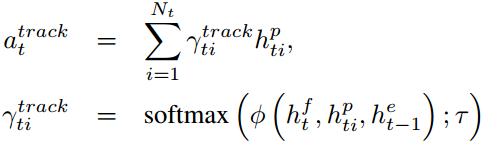
其中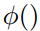 是一个多层感知机。
是一个多层感知机。
非跟踪模型
直接使用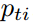 替代
替代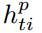 ,可以得到计算方法为
,可以得到计算方法为
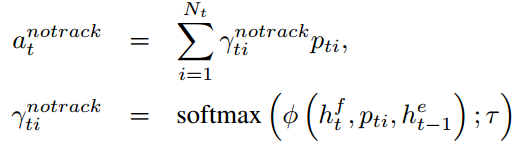
【CV论文阅读】Detecting events and key actors in multi-person videos的更多相关文章
- 【CV论文阅读】Deep Linear Discriminative Analysis, ICLR, 2016
DeepLDA 并不是把LDA模型整合到了Deep Network,而是利用LDA来指导模型的训练.从实验结果来看,使用DeepLDA模型最后投影的特征也是很discriminative 的,但是很遗 ...
- 【CV论文阅读】Unsupervised deep embedding for clustering analysis
Unsupervised deep embedding for clustering analysis 偶然发现这篇发在ICML2016的论文,它主要的关注点在于unsupervised deep e ...
- 【CV论文阅读】生成式对抗网络GAN
生成式对抗网络GAN 1. 基本GAN 在论文<Generative Adversarial Nets>提出的GAN是最原始的框架,可以看成极大极小博弈的过程,因此称为“对抗网络”.一般 ...
- 【CV论文阅读】Image Captioning 总结
初次接触Captioning的问题,第一印象就是Andrej Karpathy好聪明.主要从他的两篇文章开始入门,<Deep Fragment Embeddings for Bidirectio ...
- 【CV论文阅读】+【搬运工】LocNet: Improving Localization Accuracy for Object Detection + A Theoretical analysis of feature pooling in Visual Recognition
论文的关注点在于如何提高bounding box的定位,使用的是概率的预测形式,模型的基础是region proposal.论文提出一个locNet的深度网络,不在依赖于回归方程.论文中提到locne ...
- 【CV论文阅读】Dynamic image networks for action recognition
论文的重点在于后面approximation部分. 在<Rank Pooling>的论文中提到,可以通过训练RankSVM获得参数向量d,来作为视频帧序列的representation.而 ...
- 【CV论文阅读】Rank Pooling for Action Recognition
这是期刊论文的版本,不是会议论文的版本.看了论文之后,只能说,太TM聪明了.膜拜~~ 视频的表示方法有很多,一般是把它看作帧的序列.论文提出一种新的方法去表示视频,用ranking function的 ...
- 【CV论文阅读】Two stream convolutional Networks for action recognition in Vedios
论文的三个贡献 (1)提出了two-stream结构的CNN,由空间和时间两个维度的网络组成. (2)使用多帧的密集光流场作为训练输入,可以提取动作的信息. (3)利用了多任务训练的方法把两个数据集联 ...
- 【CV论文阅读】YOLO:Unified, Real-Time Object Detection
YOLO的一大特点就是快,在处理上可以达到完全的实时.原因在于它整个检测方法非常的简洁,使用回归的方法,直接在原图上进行目标检测与定位. 多任务检测: 网络把目标检测与定位统一到一个深度网络中,而且可 ...
随机推荐
- jq一些常用的交互效果
jq回到顶部: //回到顶部 $(window).scroll(function() { //执行处理的代码 var a = document.body.scrollTop; if($(documen ...
- VirtualBox Networking Model
- (转)淘淘商城系列——MyBatis分页插件(PageHelper)的使用以及商品列表展示
http://blog.csdn.net/yerenyuan_pku/article/details/72774381 上文我们实现了展示后台页面的功能,而本文我们实现的主要功能是展示商品列表,大家要 ...
- Java8新特性 Stream流式思想(三)
Stream接口中的常用方法 forEach()方法package cn.com.cqucc.demo02.StreamMethods.Test02.StreamMethods; import jav ...
- 对称加密DES加密
DES加密: des是对称加密,加密和解密需要相同的秘钥,它的密码最长56位,必须是8的倍数,秘钥越长,越安全. package com.trm.util.encrypt; import java.s ...
- NLog小记
NLog安装: Install-Package NLog NLog配置: <?xml version="1.0" encoding="utf-8" ?&g ...
- sublime text 快捷键记录
sublime常用快捷键 Ctrl+D 选词 (反复按快捷键,即可继续向下同时选中下一个相同的文本进行同时编辑) Ctrl+G 跳转到相应的行 Ctrl+J 合并行(已选择需要合并的多行时) Ctrl ...
- 基于Redis的三种分布式爬虫策略
前言: 爬虫是偏IO型的任务,分布式爬虫的实现难度比分布式计算和分布式存储简单得多. 个人以为分布式爬虫需要考虑的点主要有以下几个: 爬虫任务的统一调度 爬虫任务的统一去重 存储问题 速度问题 足够“ ...
- MyBatis 多参问题
当传入的参数为多个参数时 1 可以不封装为Javabean直接传入,写法如下 public List<XXXBean> getXXXBeanList(String xxId, String ...
- Java ExecutorService四种线程池的例子与说明(转发)
1.new Thread的弊端 执行一个异步任务你还只是如下new Thread吗? new Thread(new Runnable() { @Override public void run() { ...