lucene 范围过滤
Lucene里面有关于Filter的整体知识
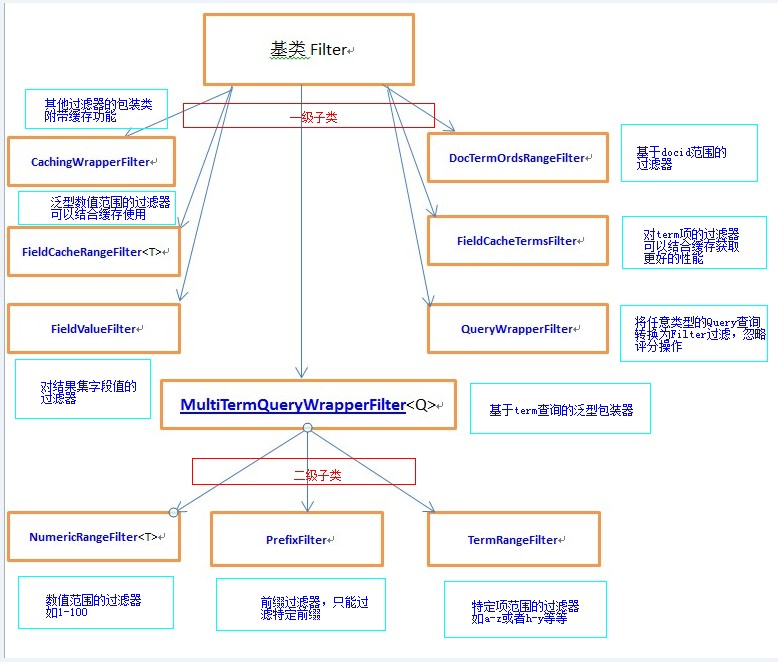
下面,我们来看下具体的在代码里怎么实现,先来看下我们的测试数据

- id score bookname ename type price date
- 1 1 飘渺之旅 pmzl 小说 52.23 201005
- 2 1 三国演义 sgyy 小说 36.13 201207
- 3 1 数据库实战 sjksz 技术 77.13 200811
- 4 1 编程宝典 bcbd 技术 100.3 200501
- 5 1 职场关系论 zcgxl 职场 36.59 200501
- 6 1 健康生活 jksh 生活 20.47 200008
- 7 1 看清本质 kqbz 社会 10.37 201004
- 8 1 编程,编程 bcbc 社会 10.37 201004
核心代码
- //使用过滤器 最后一个为true时包含边界部分,为false时不包含边界部分
- //倒数第二个为true时,包含查询边界,为false时不包含
- TermRangeFilter filter=new TermRangeFilter("ename", new BytesRef("h"), new BytesRef("n"), true, true);
- TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
- 6 1 健康生活 jksh 生活 20.47 200008
- 7 1 看清本质 kqbz 社会 10.37 201004
核心代码
- NumericRangeFilter<Double> filter=NumericRangeFilter.newDoubleRange("price", 10D, 40D, true, false);
- TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
- 2 1 三国演义 sgyy 小说 36.13 201207
- 5 1 职场关系论 zcgxl 职场 36.59 200501
- 6 1 健康生活 jksh 生活 20.47 200008
- 7 1 看清本质 kqbz 社会 10.37 201004
- 8 1 编程,编程 bcbc 社会 10.37 201004
核心代码
- //使用缓存过滤
- Filter filter=FieldCacheRangeFilter.newDoubleRange("price", 20D, 50D, true, true);
- TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式
输出结果
- 2 1 三国演义 sgyy 小说 36.13 201207
- 5 1 职场关系论 zcgxl 职场 36.59 200501
- 6 1 健康生活 jksh 生活 20.47 200008
lucene 范围过滤的更多相关文章
- lucene 过滤结果
package cn.itcast.h_filter; import java.util.ArrayList; import java.util.List; import org.apache.luc ...
- 【lucene系列学习四】使用IKAnalyzer分词器实现敏感词和停用词过滤
Lucene自带的中文分词器SmartChineseAnalyzer不太好扩展,于是我用了IKAnalyzer来进行敏感词和停用词的过滤. 首先,下载IKAnalyzer,我下载了 然后,由于IKAn ...
- lucene整理3 -- 排序、过滤、分词器
1. 排序 1.1. Sort类 public Sort() public Sort(String field) public Sort(String field,Boolean reverse ...
- lucene查询索引库、分页、过滤、排序、高亮
2.查询索引库 插入测试数据 xx.xx. index. ArticleIndex @Test public void testCreateIndexBatch() throws Exception{ ...
- lucene自定义过滤器
先介绍下查询与过滤的区别和联系,其实查询(各种Query)和过滤(各种Filter)之间非常相似,可以这样说只要用Query能完成的事,用过滤也都可以完成,它们之间可以相互转换,最大的区别就是使用过滤 ...
- MySQL和Lucene索引对比分析
MySQL和Lucene都可以对数据构建索引并通过索引查询数据,一个是关系型数据库,一个是构建搜索引擎(Solr.ElasticSearch)的核心类库.两者的索引(index)有什么区别呢?以前写过 ...
- Lucene系列-FieldCache
域缓存,加载所有文档中某个特定域的值到内存,便于随机存取该域值. 用途及使用场景 当用户需要访问各文档中某个域的值时,IndexSearcher.doc(docId)获得Document的所有域值,但 ...
- Apache Lucene(全文检索引擎)—分词器
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- Apache Lucene(全文检索引擎)—搜索
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
随机推荐
- AIDL跨进程通信报Intent must be explicit
在Android5.0机子上采用隐式启动来调试AIDL时,会出现Intent must be explicit的错误,原因是5.0的机子不允许使用隐式启动方式,解决的方法是:在启动intent时添加i ...
- 设计模式——“signleton”
那天别人问了我一个问题,关于单例模式的,由于之前了解的都是蜻蜓点水,所以重新复习了一次重新总结. 单例模式的写法总的来说有5种:懒汉,恶汉,枚举,双重校验锁,静态内部类 懒汉 public class ...
- Java_Web三大框架之Struts2
今天正式接触Java_Web三大框架之Struts2框架.对于初学者来说,先来了解什么是框架技术: 一.“框架技术”帮我们更快更好地构建程序: 1.是一个应用程序的半成品 2.提供可重用的公共结构 3 ...
- java 类名.this
类名为this的限定词. 相对于内部类:有多个this: 1.内部类本身的this: 2.内部类的环境类的this: 类名.this,就是为了对这些this指针的指向做出限定. 区别于类名.class ...
- 【LeetCode】4、Median of Two Sorted Arrays
题目等级:Hard 题目描述: There are two sorted arrays nums1 and nums2 of size m and n respectively. Find t ...
- php中fopen不能创建中文文件名文件的问题
之前网页的chartset用的是utf-8,文件也用utf-8,然后用fopen()创建一个中文文件名的文件时问题就出来了,文件名都是乱 码! 查看了很多文档试了不少方法都解决不了,本来想着用别的方法 ...
- git对vue项目进行版本管理
生成本地仓库 步骤一:git init 步骤二:git add * 步骤三:git commit -m 'init team' 创建远程仓库 new responstory 复制关联代码的命令 将本地 ...
- 解决高分屏/高DPI下GNOME3/Linux字体和按钮太小的问题
更改系统设置就好了. 我的设备是Surface Pro,12英寸,分辨率2736x1824,在虚拟机里安装CentOS 7后字特别小,标题栏的最小化/最大化/关闭按钮也很小,眼睛受不了的. 更改两个设 ...
- 取代PHP原生函数的一些扩展包
前言 虽然程序员无时无刻都在造轮子,但造轮子也有效率之分,用好轮子才能造出好"
- Asp.NET误人子弟教程:在MVC里面结合JQ实现AJAX
public class Person { public string Name { get; set; } public string City { get; set; } public strin ...