Python数据分析2------数据探索
一、数据探索
数据探索的目的:及早发现数据的一些简单规律或特征
数据清洗的目的:留下可靠数据,避免脏数据的干扰。
两者没有严格的先后顺序,经常在一个阶段进行。
分为:
(1)数据质量分析(跟数据清洗密切联系):缺失值分析、异常值分析、一致性分析、重复数据或含有特殊符号的数据分析
(2)数据特征分析(分布、对比、周期性、相关性、常见统计量等):
二、数据探索操作
- 查看数据前5行:dataframe.head()
- #查看数据的信息,包括每个字段的名称、非空数量、字段的数据类型 : data.info()

- #用统计学指标快速描述数据的概要: data.describe()

- #查看dataframe的大小:dataframe.shape
三、缺失值分析
(通过describe与len直接发现,通过0数据发现)
(1)缺失值发现:
比方说一个dataframe:dataframe.describe()得到count结果与len(dataframe[某个属性])对比,若少则表明有缺失值。
若一个dataframe中的0数据过多且不合理,则表明这个属性也存在缺失值。
操作:
- dataframe.isnull() #元素级别的判断,把对应的所有元素的位置都列出来,元素为空或者NA就显示True,否则就是False

- dataframe.isnull().any() #列级别的判断,只要该列有为空或者NA的元素,就为True,否则False

- missing = dataframe.columns [ dataframe.isnull().any() ].tolist() #将为空或者NA的列找出来
- dataframe [ missing ].isnull().sum() #将列中为空或者NA的个数统计出来
- # 缺失值比例 len(data["Age"] [ pda.isnull(data["Age"]) ]) / len(data))
(2)缺失值处理方式:(删除、插补、不处理)
- 缺失值少:插补(均值插补、中位数插补、众数插补、固定值插补、最近数据插补、回归插补、拉格朗日插值、牛顿插值法、分段插值、用预测值填充 等)
- 缺失值多:不处理,不使用该类型数据
- 缺失值适中:将缺失当做新的一类,如one-hot来处理
操作:
插补:
- dataframe.loc [ dataframe [ column ] .isnull() , column ] = value 将某一列column中缺失元素的值,用value值进行填充。
- data.Age.fillna(data.Age.mean(),inplace=True) 将age列缺失值填充均值。
- dataframe [age] [ dataframe.age.isnull() ] = dataframe.age.dropna().mode().values #众数填补 , mode()函数就是取出现次数最多的元素。
- dataframe ['age'].fillna(method='pad') #使用前一个数值替代空值或者NA,就是NA前面最近的非空数值替换
- dataframe ['age'].fillna(method='bfill',limit=1) #使用后一个数值替代空值或者NA,limit=1就是限制如果几个连续的空值,只能最近的一个空值可以被填充。
- df.interpolate():对于时间序列的缺失,可以使用这种方法。
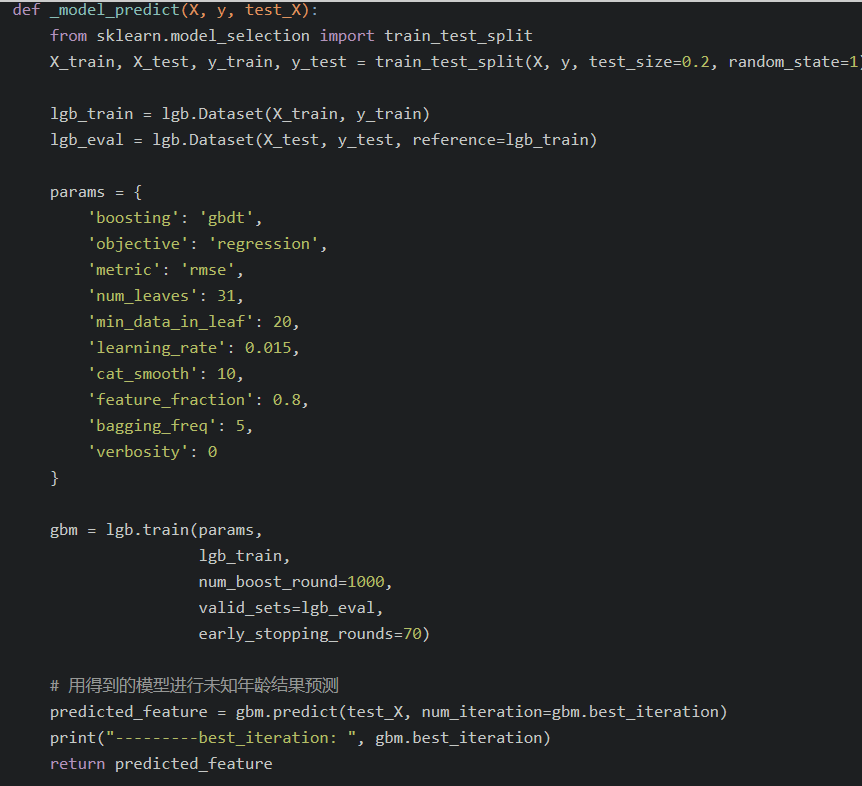
- import lightgbm as lgb :采用lgb来预测缺失值填补

删除:
- new_drop = dataframe.dropna ( axis=0,subset=["Age","Sex"] ) 【在子集中有缺失值,按行删除】
- new_drop = dataframe.dropna ( axis=1) 【将dataframe中含有缺失值的所有列删除】
(2)异常值发现:(通过散点图和箱型图发现)
异常值发现:
先画数据的散点图。观察偏差过大的数据,判断其是否为异常值。
或者画箱型图,箱型图识别异常值比较客观,因为它是根据3σ原则,如果数据服从正态分布,若超过平均值的3倍标准差的值被视为异常值。
异常值处理方式:视为缺失值、删除、修补(平均数、中位数等)、不处理。
中位数比平均值插值好一点,因为受异常值影响较小。
4、数据特征分析:
分布分析:(画直方图)
先确定极差(max-min)、组数、组距,然后根据这三个来画直方图(hist函数)。
可以大范围查看数据,也可以缩小范围进行分析,这需要具体数据具体分析。
通常数据有很多属性,可以将属性两两画直方图,通过直方图来分析数据符合什么分布,比如正态分布,线性分布等。如果使用上所有的数据范围过大,分布过于集中不明显,可以将其集中的数据缩小到一个小范围中再画直方图进行分析。
小例子:将data中price列数据值为0的变为缺失值,然后再给其赋值为中位数,假设中位数为36
import pandas as pd data['price'][(data['price']==0)]=None
for i in data.columns:
for j in data.index:
if (data[i].isnull())[j]:
data[i][j]=''
Python数据分析2------数据探索的更多相关文章
- python数据分析笔记——数据加载与整理]
[ python数据分析笔记——数据加载与整理] https://mp.weixin.qq.com/s?__biz=MjM5MDM3Nzg0NA==&mid=2651588899&id ...
- Python机器学习之数据探索可视化库yellowbrick
# 背景介绍 从学sklearn时,除了算法的坎要过,还得学习matplotlib可视化,对我的实践应用而言,可视化更重要一些,然而matplotlib的易用性和美观性确实不敢恭维.陆续使用过plot ...
- Python机器学习之数据探索可视化库yellowbrick-tutorial
背景介绍 从学sklearn时,除了算法的坎要过,还得学习matplotlib可视化,对我的实践应用而言,可视化更重要一些,然而matplotlib的易用性和美观性确实不敢恭维.陆续使用过plotly ...
- python数据挖掘之数据探索第一篇
目录 数据质量分析 当我们得到数据后,接下来就是要考虑样本数据集的数据和质量是否满足建模的要求?是否出现不想要的数据?能不能直接看出一些规律或趋势?每个因素之间的关系是什么? 通过检验数据集的 ...
- Python数据分析_Pandas01_数据框的创建和选取
主要内容: 创建数据表 查看数据表 数据表索引.选取部分数据 通过标签选取.loc 多重索引选取 位置选取.iloc 布尔索引 Object Creation 新建数据 用list建series序列 ...
- Python数据分析--------numpy数据打乱
一.shuffle函数: import numpy.random def shuffleData(data): np.random.shufflr(data) cols=data.shape[1] X ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- 数据挖掘(二)用python实现数据探索:汇总统计和可视化
今天我们来讲一讲有关数据探索的问题.其实这个概念还蛮容易理解的,就是我们刚拿到数据之后对数据进行的一个探索的过程,旨在了解数据的属性与分布,发现数据一些明显的规律,这样的话一方面有助于我们进行数据预处 ...
- python数据分析之pandas数据选取:df[] df.loc[] df.iloc[] df.ix[] df.at[] df.iat[]
1 引言 Pandas是作为Python数据分析著名的工具包,提供了多种数据选取的方法,方便实用.本文主要介绍Pandas的几种数据选取的方法. Pandas中,数据主要保存为Dataframe和Se ...
随机推荐
- elasticsearch实战 中文+拼音搜索
需求 雪花啤酒 需要搜索雪花.啤酒 .雪花啤酒.xh.pj.xh啤酒.雪花pj ik导入 参考https://www.cnblogs.com/LQBlog/p/10443862.html,不需要修改 ...
- HDU4565 So Easy!
/* HDU4565 So Easy! http://acm.hdu.edu.cn/showproblem.php?pid=4565 数论 快速幂 矩阵快速幂 题意:求[(a+sqrt(b))^n ] ...
- C#--线程存储数据的机制
面试题:线程存储数据的机制 Local variables 局部变量 临时存储 栈 Instance class fields 对象存储 堆 (堆的大小只有硬件的限制) Static local va ...
- 启动BIOS虚拟化
启动BIOS虚拟化 学习了:https://jingyan.baidu.com/article/335530daa55d7e19cb41c3c2.html securable.exe下载地址:http ...
- [hdu 3264] Open-air shopping malls(二分+两圆相交面积)
题目大意是:先给你一些圆,你可以任选这些圆中的一个圆点作圆,这个圆的要求是:你画完以后.这个圆要可以覆盖之前给出的每一个圆一半以上的面积,即覆盖1/2以上每一个圆的面积. 比如例子数据,选左边还是选右 ...
- 【Storm】storm安装、配置、使用以及Storm单词计数程序的实例分析
前言:阅读笔记 storm和hadoop集群非常像.hadoop执行mr.storm执行topologies. mr和topologies最关键的不同点是:mr执行终于会结束,而topologies永 ...
- java开发环境配置(win8 64位)
自己配置java环境时是自己上网找资料装的,,有讲的好的也有讲的不是很清晰的,,自己也入了几个坑..所以在这里自己整理了下win8配置JDK的教程. 下载JDK 首先我们需要下载java开发工具包JD ...
- 各种JSON的maven引用
一.jackjson maven <jackjson.version>2.8.8</jackjson.version> <dependency> <group ...
- WebRequestSugar
用法 WebRequestSugar ws = new WebRequestSugar(); //可选参数 //ws.SetAccept //ws.SetContentType //ws.SetCoo ...
- 【转】git rebase简介(基本篇)
原文网址:http://blog.csdn.net/hudashi/article/details/7664631/ 原文: http://gitbook.liuhui998.com/4_2.html ...