爬取某网站景区列表并保存为csv文件
网址:http://www.halehuo.com/jingqu.html
经过查看可以发现,该景区页面没有分页,不停的往下拉,页面会进行刷新显示后面的景区信息
通过使用浏览器调试器,发现该网站使用的是post请求,使用ajax传输数据

请求参数:

响应数据:
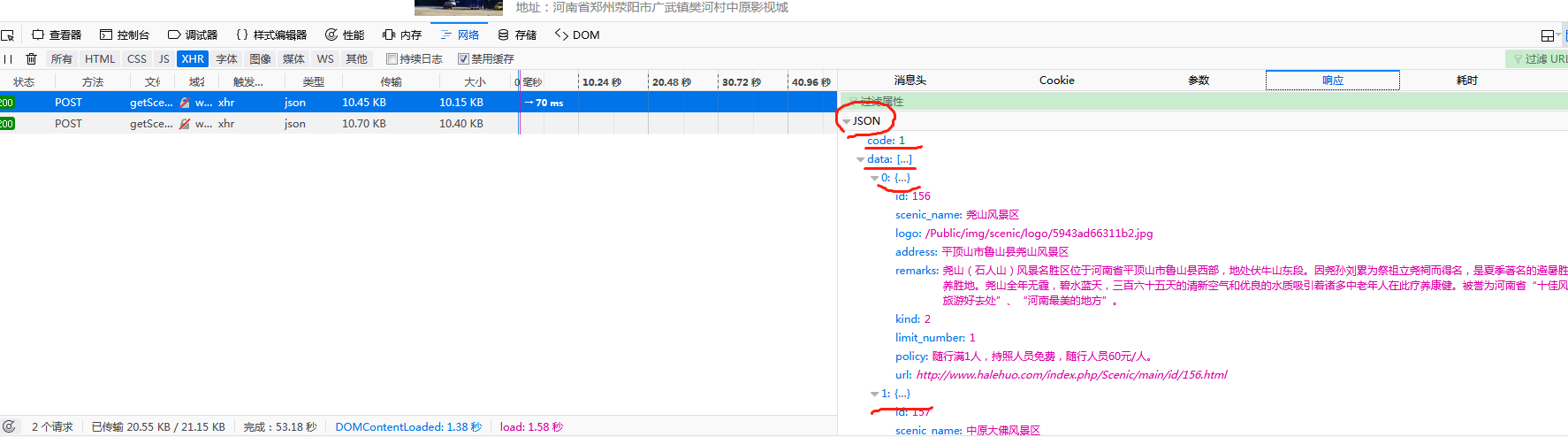


经过以上分析,大致思路如下:
(1)向请求网站使用post方式传递参数,先传递首页参数,获得json数据,然后进行数据提取,获取所需要的数据
(2)使用for循环遍历获取数据
需要注意的地方:
(1)景区logo图片获取的是相对地址,通过构造一个函数获得景区logo的绝对地址
(2)获取到的景区详情链接打不开,通过景区列表页面打开景区详情页面,发现获取的景区详情链接跟景区详情页面链接不匹配再构造一个函数处理获取到的景区详情链接
#!/usr/bin/env python
# -*- coding: utf-8 -*- import csv
import json
from urllib.parse import urlencode import requests # 构造参数,发起请求,获得数据
def get_page_index(pageindex):
data = {
'citycode': 0,
'countycode': 0,
'keywords': 0,
'pageindex': pageindex,
'sceniclev': 0,
'themetype': 0,
}
params = urlencode(data)
base = 'http://www.halehuo.com/index.php/Scenic/getScenicList'
url = base + '?' + params
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
print('Error occurred')
return None # 处理景区logo地址
def get_log_url(url):
base_url = 'http://www.halehuo.com'
return base_url + url # 处理景区详情链接
def get_detail_url(url):
return url.replace('index.php/Scenic/main/id', 'jingqu') # 解析获得的景区数据
def parse_page_index(pageindex):
item = get_page_index(pageindex)
items = json.loads(item)['data']
for item in items:
yield {
'id': item['id'],
'scenic_name': item['scenic_name'],
'logo': get_log_url(item['logo']),
'address': item['address'],
'policy': item['policy'],
'url': get_detail_url(item['url']),
'remarks': item['remarks']
} # 数据存储到csv
def write_to_file3(item):
with open('jingqu_detail.csv', 'a', encoding='utf_8_sig', newline='') as f:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['id', 'scenic_name', 'logo', 'address', 'policy', 'url', 'remarks']
w = csv.DictWriter(f, fieldnames=fieldnames)
# w.writeheader()
# print(item)
w.writerow(item) def main():
for i in range(1, 13):
items = parse_page_index(i)
for item in items:
write_to_file3(item) if __name__ == '__main__':
main()
保存到csv文件的截图如下:

爬取某网站景区列表并保存为csv文件的更多相关文章
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- 爬取拉勾网python工程师的岗位信息并生成csv文件
转载自:https://www.cnblogs.com/sui776265233/p/11146969.html 代码写得很好,但是目前只看得懂前一部分 一.爬取和分析相关依赖包 Python版本: ...
- scrapy框架来爬取壁纸网站并将图片下载到本地文件中
首先需要确定要爬取的内容,所以第一步就应该是要确定要爬的字段: 首先去items中确定要爬的内容 class MeizhuoItem(scrapy.Item): # define the fields ...
- 使用Python爬取微信公众号文章并保存为PDF文件(解决图片不显示的问题)
前言 第一次写博客,主要内容是爬取微信公众号的文章,将文章以PDF格式保存在本地. 爬取微信公众号文章(使用wechatsogou) 1.安装 pip install wechatsogou --up ...
- python爬取视频网站m3u8视频,下载.ts后缀文件,合并成整视频
最近发现一些网站,可以解析各大视频网站的vip.仔细想了想,这也算是爬虫呀,爬的是视频数据. 首先选取一个视频网站,我选的是 影视大全 ,然后选择上映不久的电影 “一出好戏” . 分析页面 我用的是c ...
- 使用pandas中的raad_html函数爬取TOP500超级计算机表格数据并保存到csv文件和mysql数据库中
参考链接:https://www.makcyun.top/web_scraping_withpython2.html #!/usr/bin/env python # -*- coding: utf-8 ...
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
随机推荐
- javascript 获取当前对象
<a href="dsfjlsdjf" onclick="testGet()"> 请教编写testGet()函数获取这个超链接href属性,限制例如 ...
- DM8168 IPNC Boa移植
1.交叉编译openssL 下载openssL-1.0.0.tar.gz在虚拟机下进行交叉编译,生成libcrypto.a及libssl.a.将这两个文件复制到DVRRDK_03.00.00.00/b ...
- java调用c++ dll出现中文乱码
近期的开发用到了使用java调用本机动态连接库的功能,将文件路径通过java调用C++代码对文件进行操作. 在调用中假设路径中包括有中文字符就会出现故障.程序执行就会中止. 以下用一个小样例,来说明记 ...
- 新手对ASP.NET MVC的疑惑
习惯了多年的WEB FORM开发方式,突然转向MVC,一下子懵了,晕头转向,好多不习惯,好多不明白,直到现在也没弄明白,只好先记下来,在应用中一一求解. 主要集中在视图(View)这里. 1.@Htm ...
- Android系统Recovery工作原理之使用update.zip升级过程分析(八)---解析并执行升级脚本updater-script【转】
本文转载自:http://blog.csdn.net/mu0206mu/article/details/7465551 Android系统Recovery工作原理之使用update.zip升级过程分 ...
- UESTC--758--P酱的冒险旅途(模拟)
P酱的冒险旅途 Time Limit: 1000MS Memory Limit: 65535KB 64bit IO Format: %lld & %llu Submit Status ...
- codeforces 916E Jamie and Tree dfs序列化+线段树+LCA
E. Jamie and Tree time limit per test 2.5 seconds memory limit per test 256 megabytes input standard ...
- 【POJ 1456】 Supermarket
[题目链接] http://poj.org/problem?id=1456 [算法] 贪心 + 堆 [代码] #include <algorithm> #include <bitse ...
- TCP打开文件传输(客户端code)
#include <stdio.h>#include <stdlib.h>#include <arpa/inet.h>#include <sys/types. ...
- Flink之流处理理论基础
目录 Introduction to Stateful Stream Processing Traditional Data Infrastructures Stateful Stream Proce ...