[机器学习]Generalized Linear Model
最近一直在回顾linear regression model和logistic regression model,但对其中的一些问题都很疑惑不解,知道我看到广义线性模型即Generalized Linear Model后才恍然大悟原来这些模型是这样推导的,在这里与诸位分享一下,具体更多细节可以参考Andrew Ng的课程。
一、指数分布
广义线性模型都是由指数分布出发来推导的,所以在介绍GLM之前先讲讲什么是指数分布。指数分布的形式如下:

η是参数,T(y)是y的充分统计量,即T(y)可以完全表达y,通常T(y)=y。当参数T,b,a都固定的时候,就定义了一个以η为参数的参数簇。实际上,很多的概率分布都是属于指数分布,比如:
(1)伯努利分布
(2)正态分布
(3)泊松分布
(4)伽马分布
等等等。。。。
或许从原本的形式上看不出来他们是指数分布,但是经过一系列的变换之后,就会发现他们都是指数分布。举两个例子,顺便我自己也推导一下。
伯努利分布:
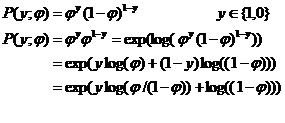
那么b(y)=1,T(y)=y,η=log(φ/(1-φ)),a(η)=log((1-φ)),则φ=1/(1+e-y),这个就是sigmoid函数的由来。
同样我们对正态分布做变换,不过在这里我们要假设方差为1,以为方差并不影响我们的回归。
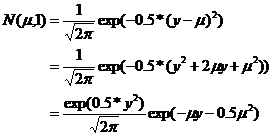
我们可以看到η=µ。
二、广义线性模型
介绍完指数分布后我们可以来看看广义线性模型是怎样的。
首先广义线性模型有三个假设,这三个假设即是前提条件也是帮助我们构造模型的关键。
(1)P(y|x;θ)~ExpFamliy(η);
(2)对于一个给定x,我们的目标函数为h(x)=E[T(y)|x];
(3)η=ΘTx
根据以上三个假设我们就能推导出logistic model 和 最小二乘模型。Logistic model 推导如下:
h(x)=E[T(y)|x]=E[y|x]=φ=1/(1+e-η)=1/(1+e-ΘTx)
对于最小二乘模型推导如下:
h(x)=E[T(y)|x]=E[y|x]=η=µ=ΘTx
从中我们将把η和原模型参数联系起来的函数称之为正则响应函数。所以对于广义线性模型,我们需要y是怎样的分布,就能推导出相应的模型。有兴趣的可以从多项式分布试试推导出SoftMax回归。
[机器学习]Generalized Linear Model的更多相关文章
- Bayesian generalized linear model (GLM) | 贝叶斯广义线性回归实例
一些问题: 1. 什么时候我的问题可以用GLM,什么时候我的问题不能用GLM? 2. GLM到底能给我们带来什么好处? 3. 如何评价GLM模型的好坏? 广义线性回归啊,虐了我快几个月了,还是没有彻底 ...
- 广义线性模型(Generalized Linear Model)
广义线性模型(Generalized Linear Model) http://www.cnblogs.com/sumai 1.指数分布族 我们在建模的时候,关心的目标变量Y可能服从很多种分布.像线性 ...
- 广义线性模型(GLM, Generalized Linear Model)
引言:通过高斯模型得到最小二乘法(线性回归),即: 通过伯努利模型得到逻辑回归,即: 这些模型都可以通过广义线性模型得到.广义线性模型是把自变量的线性预测函数当作因变量的估计值.在 ...
- 从线性模型(linear model)衍生出的机器学习分类器(classifier)
1. 线性模型简介 0x1:线性模型的现实意义 在一个理想的连续世界中,任何非线性的东西都可以被线性的东西来拟合(参考Taylor Expansion公式),所以理论上线性模型可以模拟物理世界中的绝大 ...
- Andrew Ng机器学习公开课笔记 -- Generalized Linear Models
网易公开课,第4课 notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf 前面介绍一个线性回归问题,符合高斯分布 一个分类问题,logstic回 ...
- [Scikit-learn] 1.5 Generalized Linear Models - SGD for Classification
NB: 因为softmax,NN看上去是分类,其实是拟合(回归),拟合最大似然. 多分类参见:[Scikit-learn] 1.1 Generalized Linear Models - Logist ...
- [Scikit-learn] 1.1 Generalized Linear Models - Logistic regression & Softmax
二分类:Logistic regression 多分类:Softmax分类函数 对于损失函数,我们求其最小值, 对于似然函数,我们求其最大值. Logistic是loss function,即: 在逻 ...
- Regression:Generalized Linear Models
作者:桂. 时间:2017-05-22 15:28:43 链接:http://www.cnblogs.com/xingshansi/p/6890048.html 前言 本文主要是线性回归模型,包括: ...
- Generalized Linear Models
作者:桂. 时间:2017-05-22 15:28:43 链接:http://www.cnblogs.com/xingshansi/p/6890048.html 前言 主要记录python工具包:s ...
随机推荐
- NOIP2015 运输计划 - 二分 + 树链剖分 / (倍增 + 差分)
BZOJ CodeVS Uoj 题目大意: 给一个n个点的边带权树,给定m条链,你可以选择树中的任意一条边,将它置为0,使得最长的链长最短. 题目分析: 最小化最大值,二分. 二分最短长度mid,将图 ...
- JQuery通过radio,select改变隐藏显示div
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/qq_36092584/article/details/52740681 1)select下拉框控制d ...
- 查询系统状态 内存大小 cpu信息 设备负载情况
1.1 查看内存状态 /proc/meminfo里面存放着内存的信息 查看内存命令(包括虚拟内存swap): free -h (低版本系统可能不支持-h) 或者 free -m (以mb单位显示) a ...
- Sleep(0)的妙用
在线程中,调用sleep(0)可以释放cpu时间,让线程马上重新回到就绪队列而非等待队列,sleep(0)释放当前线程所剩余的时间片(如果有剩余的话),这样可以让操作系统切换其他线程来执行,提升效率. ...
- Cordova 返回键切换后台
这里需要用到 cordova-plugin-backbutton 这个插件 1.安装插件,命令窗口输入(当前目录是你项目所在的目录) cordova plugin add cordova-plugin ...
- Linux调试工具
1. 使用printf调试 #ifdef DEBUG Printf(“valriable x has value = %d\n”, x) #endif 然后在编译选项中加入-DDEBUG 更复杂的调试 ...
- Airflow 使用简介
- Delphi读取文件属性
Read File Detailed Properties https://www.board4all.biz/threads/read-file-detailed-properties.655787 ...
- ORACLE 11G在相同的linuxserver从实施例1满库到实例2上
早期的导出命令: [root@powerlong4 ~]# su - oracle [oracle@powerlong4 ~]$ export ORACLE_SID=pt1; [oracle@powe ...
- 如何将任意文件固定在 Win10 的开始屏幕中
虽然Wox和Launchy是我日常启动程序的主力方式,不过开始屏幕的图标方便归类,这是快速启动工具所不能提供的,因此我也会将最常用的程序在开始屏幕上分类固定. 最近需要将一个常用的批处理文件(*.ba ...