Spark学习笔记2——RDD(上)
Spark学习笔记2——RDD(上)
笔记摘抄自 [美] Holden Karau 等著的《Spark快速大数据分析》
RDD是什么?
弹性分布式数据集(Resilient Distributed Dataset,简称 RDD)
- Spark 的核心概念
- 一个不可变的分布式对象集合
- 每个 RDD 都被分为多个分区运行在集群的不同节点上
- RDD 可以包含 Python、Java、Scala 中任意类型的对象(可以自定义)
在 Spark 中,对数据的所有操作不外乎 创建 RDD、转化已有 RDD 以及 调用 RDD 操作 进行求值。而在这一切背后,Spark 会自动将 RDD 中的数据分发到集群上,并将操作并行化执行。
例子
创建 RDD 的两种方式:
- 读取一个外部数据集
- 驱动器程序里分发驱动器程序中的对象集合(比如 list 和 set)
这里通过读取文本文件作为一个字符串 RDD:
>>> lines = sc.textFile("README.md")
RDD 的两种操作:
- 转化操作(transformation):由一个RDD 生成一个新的RDD,例如筛选数据
- 行动操作(action):对RDD 计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(如HDFS)中
调用转化操作 filter() :
>>> pythonLines = lines.filter(lambda line: "Python" in line)
调用 first() 行动操作 :
>>> pythonLines.first()
u'high-level APIs in Scala, Java, Python, and R, and an optimized engine that'
@Notice
- “惰性计算”:RDD 只有在进行第一个 行动操作 时才会被计算[1]
- “持久化”:RDD默认会在每次行动操作时重新计算[2],如果想要在多个行动操作中重复使用同一个 RDD ,需要对该 RDD 进行 “持久化”
把RDD 持久化[3]到内存中
>>> pythonLines.persist
<bound method PipelinedRDD.persist of PythonRDD[3] at RDD at PythonRDD.scala:53>
>>> pythonLines.count()
3
>>> pythonLines.first()
u'high-level APIs in Scala, Java, Python, and R, and an optimized engine that'
创建 RDD
并行化方式
把程序中一个已有的集合传给 SparkContext 的 parallelize() 方法,这种方式需要把整个数据集先放到一台机器的内存中,故不常用
JavaRDD<String> lines = sc.parallelize(Arrays.asList("pandas", "i like pandas"));
读取外部数据集方式
JavaRDD<String> lines = sc.textFile("/path/to/README.md");
RDD 操作
转化操作
RDD 的转化操作是返回一个新的RDD 的操作,比如 map() 和 filter()
例程(Java)
展示日志文件中所有错误记录
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.List;
public class CountError {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("CountError");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaRDD<String> log = javaSparkContext.textFile(args[0]);
JavaRDD<String> errorsRDD = log.filter(
new Function<String, Boolean>() {
public Boolean call(String x) {
return x.contains("ERROR");
}
});
List<String> errors = errorsRDD.collect();
for (String output : errors) {
System.out.println(output);
}
javaSparkContext.stop();
}
}
日志文件内容
INFO:everything gonna be ok...
ERROR:something is wrong!
INFO:everything gonna be ok...
ERROR:something is wrong!
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
ERROR:something is wrong!
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
ERROR:something is wrong!
INFO:everything gonna be ok...
INFO:everything gonna be ok...
运行效果
[root@server1 spark-2.4.4-bin-hadoop2.7]# bin/spark-submit --class CountError ~/SparkTest2.jar ~/SparkTest2.log
...
19/09/10 16:33:10 INFO DAGScheduler: Job 0 finished: collect at CountError.java:20, took 0.423698 s
ERROR:something is wrong!
ERROR:something is wrong!
ERROR:something is wrong!
ERROR:something is wrong!
...
例程(Python)
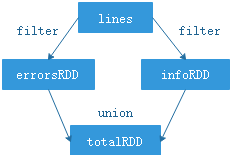
>>> lines = sc.textFile("/root/SparkTest2.log")
>>> errorsRDD = lines.filter(lambda lines: "ERROR" in lines)
>>> infoRDD = lines.filter(lambda lines: "INFO" in lines)
>>> totalRDD = errorsRDD.union(infoRDD)
>>> lines.count()
21
>>> errorsRDD.count()
4
>>> infoRDD.count()
17
>>> totalRDD.count()
21
@Notice
转化操作可以操作任意数量的输入 RDD
Spark 会使用谱系图(lineage graph)来记录这些不同 RDD 之间的依赖关系,以此按需计算每个 RDD
@P.s.
也可以依靠谱系图在持久化的RDD 丢失部分数据时恢复所丢失的数据
行动操作
把最终求得的结果返回到驱动器程序,或者写入外部存储系统中的 RDD 操作
上文例程中的 count() 便是一个行动操作,另外还有 take() 、collect() 等操作
下面以 take() 为例,获取 union 后的 totalRDD 的前 10 条
>>> for line in totalRDD.take(10):print line
...
ERROR:something is wrong!
ERROR:something is wrong!
ERROR:something is wrong!
ERROR:something is wrong!
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
INFO:everything gonna be ok...
>>>
@P.s.
程序把RDD 筛选到一个很小的规模单台机器内存足以放下时才可以使用 collect()
惰性求值
RDD 的转化操作都是惰性求值的,在被调用行动操作之前 Spark 不会开始计算
- 不应该把 RDD 看作存放着特定数据的数据集,而最好把每个 RDD 当作我们通过转化操作构建出来的、记录如何计算数据的 指令列表
- 把数据读取到 RDD 的操作也同样是惰性的
- 读取数据的操作也有可能会多次执行
Spark学习笔记2——RDD(上)的更多相关文章
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记之RDD中的Transformation和Action函数
总算可以开始写第一篇技术博客了,就从学习Spark开始吧.之前阅读了很多关于Spark的文章,对Spark的工作机制及编程模型有了一定了解,下面把Spark中对RDD的常用操作函数做一下总结,以pys ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
随机推荐
- CentOS7下搭建zabbix监控(一)——Zabbix监控端配置
zabbix 是一个基于 WEB 界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案.zabbix 能监视各种网络参数,保证服务器系统的安全运营:并提供灵活的通知机制以让系统管理员快速定位 ...
- (十二)class文件结构:魔数和版本
一.java体系结构 二.class格式文件概述 class文件是一种8位字节的二进制流文件, 各个数据项按顺序紧密的从前向后排列, 相邻的项之间没有间隙, 这样可以使得class文件非常紧凑, 体积 ...
- jenkins:从FTP服务器下载文件
lftp 账号:密码@192.168.207.2 lcd /home/eccore/app/chen get -c /基础运维共享文件/OK-TeamViewer14.2.2558.rar
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- 并查集与最小生成树Kruskal算法
一.什么是并查集 在计算机科学中,并查集是一种树型的数据结构,用于处理一些不交集的合并及查询问题.有一个联合-查找算法(union-find algorithm)定义了两个用于次数据结构的操作: Fi ...
- CSS History
Preface 如果只是要写程序,那的确是不需要这么麻烦,上来直接看Syntax,动手写上至少300行代码,做上3个应用程序,这门语言你也就差不多会用了,接下来不过就是模式,特殊的地方以及记住一些函数 ...
- Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2)
mysql使用可视化界面登录使用的时候都没问题,只要使用xhell命令进入mysql就报异常 Can't connect to local MySQL server through socket '/ ...
- Win10 改为用 Ctrl+Shift 切换中英输入语言而不是 Win+空格
是切换中英输入语言,而不是切换输入法,如图: 步骤: 设置 > 设备 > 输入 > 高级键盘设置 > 语言栏选项 > 高级键盘设置 > 更改按键顺序 > 切换 ...
- C++:链表(有头链表)
介绍 把链表分为无头链表和有头链表. 无头链表:所有的节点都包含了有效数据,上一篇文章中演示代码使用的就是无头链表. 有头链表:用一个固定的头节点来指代整个链表,所有的对象都挂在这个头节点下面,而头节 ...
- spring cloud微服务实践三
上篇文章里我们实现了spring cloud中的服务提供者和使用者.接下来我们就来看看spring cloud中微服务的其他组件. 注:这一个系列的开发环境版本为 java1.8, spring bo ...