Spark中资源与任务的关系
在介绍Spark中的任务和资源之前先解释几个名词:
Dirver Program:运行Application的main函数(用户提交的jar包中的main函数)并新建SparkContext实例的程序,称为驱动程序,通常用SparkContext代表驱动程序(任务的驱动程序)。
Cluster Manager:集群管理器是集群资源管理的外部服务。Spark上现在主要有Standalone、YARN、Mesos3种集群资源管理器。Spark自带的Standalone模式能满足绝大部分
Spark计算环境中对集群资源管理的需求,基本只有在集群中运行多套计算框架时才考虑使用YARN和Mesos。通常说的Spark on YARN或者Standalone指的就是
不同的集群资源管理方式(资源管理器)。
Worker Node:集群中可以运行Application代码的工作节点(计算资源)。
Executor: 在Worker Node上为Application启动的一个工作进程,在进程中负责任务(Task)的运行,并且负责将数据存放在内存或者磁盘上,在Excutor内部通过多线程(线程池)
并发处理应用程序的具体任务(在计算资源上运行的工作进程)。
每个Application都有各自独立的Executors,因此应用程序之间是相互隔离的。
Task: 任务是指被Driver送到Executor上的工作单元。通常一个任务会处理一个Partition的数据,每个Partition一般是一个HDFS的Block块的大小(在工作进程中运行的任务
线程)。
Application: 是创建了SparkContext实例对象的Spark用户程序,包含一个Driver Program和集群中的多个Executor(运行在Spark集群上的应用程序)。
Job: 和Spark的action对应,每个action都会对应一个Job实例,每个Job会拆分成多个Stage,一个Stage包含一个任务集(TaskSet),任务集中的各个任务通过一定的
调度机制发送到工作单位(Executor)上并行执行(Application中进行任务切分的粒度)。
0. 资源的调度管理YARN vs Standalone:
Standalone:此模式下由Master节点负责,Worker节点是在Master节点的调度下启动的Executor。此时集群的部署为典型的Master/Slave架构。
Spark on YARN:yarn-cluster模式提交,首先它会和ResourceManager通信,发送请求给ResourceManager,请求启动ApplicationMaster,ResourceManager接收到请求之后,
会给它分配一个Container,然后在某个NodeManager上启动ApplicationMaster。ApplicationMaster启动之后,会和ResourceManager通信,ApplicationMaster(AM)
就相当于Driver。AM找RM,请求container,启动Executor,RM会给它分配一批Container,用于启动Exectutor。此时AM会去连接其他NM,去启动Executor,NM
就相当于Worker。Executor启动之后,向AM反向注册。与standalone相比,AM就相当于Driver,NM相当于Worker,RM相当于Master。NM上启动Executor之后还是
会反向向AM注册,后面的流程与之前的结构是一样的,这就是yarn-cluster提交模式。
参考:https://zhuanlan.zhihu.com/p/61902619
1. Standalone模式下任务与资源的关系
从上文可知,Spark集群中的资源主要为计算资源,在YARN模式下对应的是Container,Standalone模式下对应的是Worker,Application是用户开发的Spark应用程序,提交到
集群上运行,运行开始时集群给Application分配资源,运行结束后集群会回收资源(Application会释放资源);同一个集群上可以同时运行多个Application,Application之间相互隔离,每个Application对应一个SparkContext对象,由该SparkContext维护与集群之间的关系。
Worker的资源由Master进行管理,Application任务注册到Master之后,由Master根据集群当前Worker的工作状况进行资源分配。分配的资源由SparkContext创建的三个核心对象DAGScheduler,TaskScheduler,SchedulerBackend根据Application进行相应的任务划分和调度。SparkContext创建核心对象及获取计算资源的流程如下图

2. DAGScheduler
DAGSchedule是针对Application对任务进行规划。
DAGScheduler是面向Stage的高层级调度器,DAGScheduler把DAG拆分成很多Task,每组Task都是一个Stage,解析时以Shuffle(宽依赖进行数据同步时会产生Shuffle)为边界反向解析构建Stage;每次遇到Shuffle会产生新的Stage,然后以一个个TaskSet(每个Stage中的Tasks会封装成一个TaskSet)的形式提交给底层的任务调度器TaskScheduler。DAGScheduler需要记录那些RDD被存入磁盘,寻求Task的最优化调度(如Stage内部数据的本地性),监视Shuffle跨节点数据的状态,失败重新提交该Stage。
DAGScheduler的核心工作是进行Stage的划分,Stage划分的依据是RDD的宽窄依赖,父RDD的一个分区同时被多个子RDD分区依赖称为宽依赖,父RDD分区只被一个子RDD分区依赖称为窄依赖。
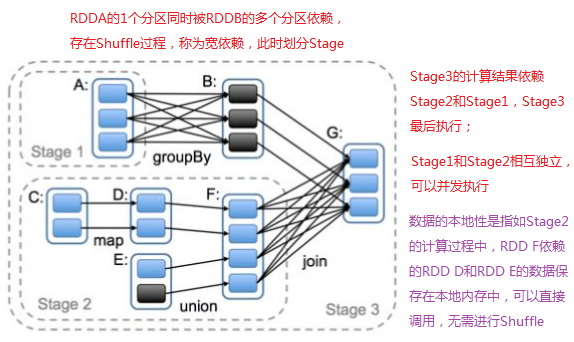
Spark Application因为不同的Action出发多个Job,每个Job由一个或多个Stage组成,后面的Stage依赖于前面的Stage。Spark在在Job的提交过程中进行Stage的划分以及确定Task的最佳位置,Stage划分以后才进行计算;Task的最佳位置及利用本地数据进行计算,本地数据即为数据就在当前内存中。DAGScheduler利用RDD自身的getPreferedLocations中的数据计算数据的本地性,getPreferedLocations中标明了每个Partition的数据本地性。
3.TaskScheduler
TaskScheduler针对Task具体的执行过程,也是针对任务而言。
TaskScheduler的核心任务是提交TaskSet到集群进行运算并汇报结果。
a. 为TaskSet创建和维护一个TaskSetManager,并追踪任务的本地性以及错误信息
b. 遇到Straggle任务时,会放到其他节点重试
c. 向DAGScheduler汇报任务执行情况,包括在Shuffle输出丢失的时候报告fetch failed错误等信息。
TaskSchduler需要确定Task任务使用的计算资源,即需要根据计算本地性原则确定Task具体要运行在哪个ExecutorBackend中。
TaskScheduler是从具体计算的角度考虑本地性,区别于DAGScheduler从数据层面考虑的本地性。
TaskSchedulerImpl是TaskScheduler的子类,通过resourceOffers方法确定Task任务具体运行的ExecutorBackend,具体过程如下:
1. 通过Random.shuffle方法重新洗牌所有计算资源,以寻求计算的负载均衡;
2. ExecutorBackend的cores个数声明类型为TaskDescription的ArrayBuffer数组;
3. 如果有新的ExecutorBackend分配给我们的Job,此时会调用executorAdded来获得新的完整的可用计算资源;
4. 寻求最高级别的优先级本地性;
/**
* Called by cluster manager to offer resources on slaves. We respond by asking our active task
* sets for tasks in order of priority. We fill each node with tasks in a round-robin manner so
* that tasks are balanced across the cluster.
*/
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
...
// Randomly shuffle offers to avoid always placing tasks on the same set of workers.
val shuffledOffers = Random.shuffle(offers)
// Build a list of tasks to assign to each worker.
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores))
val availableCpus = shuffledOffers.map(o => o.cores).toArray
val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
}
//以下代码计算最高级别的优先级本地性
// Take each TaskSet in our scheduling order, and then offer it each node in increasing order
// of locality levels so that it gets a chance to launch local tasks on all of them.
// NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY
for (taskSet <- sortedTaskSets) {
var launchedAnyTask = false
var launchedTaskAtCurrentMaxLocality = false
for (currentMaxLocality <- taskSet.myLocalityLevels) {
do {
launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(
taskSet, currentMaxLocality, shuffledOffers, availableCpus, tasks)
launchedAnyTask |= launchedTaskAtCurrentMaxLocality
} while (launchedTaskAtCurrentMaxLocality)
}
if (!launchedAnyTask) {
taskSet.abortIfCompletelyBlacklisted(hostToExecutors)
}
} if (tasks.size > 0) {
hasLaunchedTask = true
}
return tasks
}
5. 通过调用TaskSetManager的resourceOffer最终确定每个Task具体运行的ExecutorBackend的Locality Level;
6. 通过launchTasks把任务发送给ExecutorBackend执行。launchTasks首先会进行序列化,序列化的大小不能超过默认设置128M,否则报错。由参数
spark.rpc.message.maxSize设置。
4. SchedulerBackend
SchedulerBackend针对资源,所以该接口在不同的部署模式下会创建不同的子类对象(YarnSchedulerBackend)来进行资源管理,如StandaloneSchedulerBackend是在Standalone模式下的管理对象,负责收集和分配资源给Task使用。
StandaloneSchedulerBackend在接收到TaskSchedulerImpl的submitTasks后,会调用父类CoarseGrainedSchedulerBackend中的reviveOffers方法,最终调用makOffers方法分配资源执行Task。
makOffers方法的执行过程:
1. 首先过滤出Active状态的Executor,然后构建代表Executor资源可用的WorkerOffer(此处为构建可用的资源);
2. 调用TaskSchedulerImpl的resourceOffers得到TaskDescrition的二维数组,包含Task ID、Executor ID、Task Index等Task执行需要的信息;
3. 回调DriverEndPoint的launchTask给每个Task对应的Executor发执行Task的LaunchTask信息。
// Make fake resource offers on all executors
private def makeOffers() {
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
launchTasks(scheduler.resourceOffers(workOffers))
}
Spark中资源与任务的关系的更多相关文章
- Spark中Task,Partition,RDD、节点数、Executor数、core数目的关系和Application,Driver,Job,Task,Stage理解
梳理一下Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数.Executor数.core数目的关系. 输入可能以多个文件的形式存储在H ...
- Spark中的partition和block的关系
hdfs中的block是分布式存储的最小单元,类似于盛放文件的盒子,一个文件可能要占多个盒子,但一个盒子里的内容只可能来自同一份文件.假设block设置为128M,你的文件是250M,那么这份文件占3 ...
- Spark Streaming资源动态申请和动态控制消费速率剖析
本期内容 : Spark Streaming资源动态分配 Spark Streaming动态控制消费速率 为什么需要动态处理 : Spark 属于粗粒度资源分配,也就是在默认情况下是先分配好资源然后再 ...
- Spark中的编程模型
1. Spark中的基本概念 Application:基于Spark的用户程序,包含了一个driver program和集群中多个executor. Driver Program:运行Applicat ...
- Tachyon在Spark中的作用(Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks 论文阅读翻译)
摘要: Tachyon是一种分布式文件系统,能够借助集群计算框架使得数据以内存的速度进行共享.当今的缓存技术优化了read过程,可是,write过程由于须要容错机制,就须要通过网络或者 ...
- Spark中Task,Partition,RDD、节点数、Executor数、core数目(线程池)、mem数
Spark中Task,Partition,RDD.节点数.Executor数.core数目的关系和Application,Driver,Job,Task,Stage理解 from:https://bl ...
- Spark中的术语图解总结
参考:http://www.raincent.com/content-85-11052-1.html 1.Application:Spark应用程序 指的是用户编写的Spark应用程序,包含了Driv ...
- spark——spark中常说RDD,究竟RDD是什么?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark专题第二篇文章,我们来看spark非常重要的一个概念--RDD. 在上一讲当中我们在本地安装好了spark,虽然我们只有lo ...
- SPARK 中 DriverMemory和ExecutorMemory
spark中,不论spark-shell还是spark-submit,都可以设置memory大小,但是有的同学会发现有两个memory可以设置.分别是driver memory 和executor m ...
随机推荐
- python3 __mian和__name__的区别
1.新建 test.py 模块: def GetModuleName(): print('__name__ = ', __name__) def PrintName(): print('PrintNa ...
- Shell脚本执行的四种方法
(1).bash(或sh) [脚本的相对路径或绝对路径] [xf@xuexi ~]$ cat a.sh #!/bin/bash echo "hello world!" [xf@xu ...
- layoutSubviews在以下情况下会被调用
1.init初始化不会触发layoutSubviews2.addSubview会触发layoutSubviews3.设置view的Frame会触发layoutSubviews,当然前提是frame的值 ...
- python 实现对象去重
利用set()方法实现对象去重,重写__hash__方法和__eq__方法告诉程序什么样的对象是同一个对象 # 写一个类 拥有100个对象 # 拥有三个属性 name age sex # 如果两个对象 ...
- 初识MyBatis之HelloWorld
1.先下载MyBatis相关Jar包. 2. 创建数据库和表 CREATE TABLE tbl_employee( id ) PRIMARY KEY AUTO_INCREMENT, last_name ...
- 【ARM-Linux开发】C语言getcwd()函数:取得当前的工作目录
相关函数:get_current_dir_name, getwd, chdir 头文件:#include <unistd.h> 定义函数:char * getcwd(char * buf, ...
- 【并行计算-CUDA开发】 NVIDIA Jetson TX1
概述 NVIDIA Jetson TX1是计算机视觉系统的SoM(system-on-module)解决方案.它组合了最新的NVIDIAMaxwell GPU架构,其具有ARM Cortex-A57 ...
- Aspose.Words提取word文档中的图片文件
/// <summary> /// 提取word中的图片 /// </summary> /// <param name="filePath">w ...
- 洛谷 题解 P2010 【回文日期】
因为有8个字符,所以可得出每一年只有一个回文日期. 因此只要判断每一年就行了. 做法: 我们先把年倒过来,例如2018年就倒为8102,就得出8102就是回文日期的后四个字符,我们只要判断一下有没有这 ...
- Redis提供的持久化机制
Redis是一种面向“key-value”类型数据的分布式NoSQL数据库系统,具有高性能.持久存储.适应高并发应用场景等优势.它虽然起步较晚,但发展却十分迅速. 近日,Redis的作者在博客中写到, ...