车型识别API调用与批量分类车辆图片
版权声明:本文为博主原创文章,转载 请注明出处 https://blog.csdn.net/sc2079/article/details/82189824
9月9日更:博客资源下载:链接: https://pan.baidu.com/s/1AEtQL7uk4_T7TPKa1Q6kFg 提取码: g1n8 永久有效
动机
暑假实习,一位做算法的老师让我们一行人将摄像头拍取的车辆照片按车型分类保存。
示例如下:
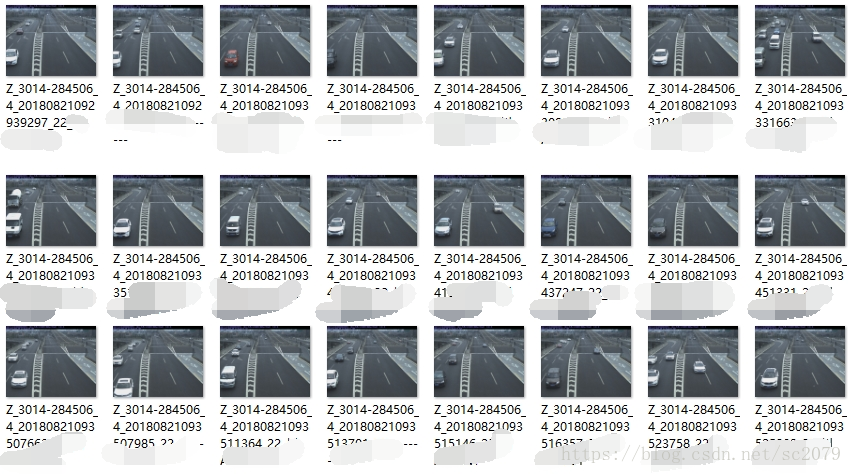
这样的图片共有上万张,且有多个文件夹,人工打开图片、放大,再识别(如果不清楚车辆标志,还需上网查找),并Ctrl+C、Ctrl+V将其保存在相应文件夹下,这着实让人感到无聊与繁琐。
因此,我就萌发了用熟知的python写个脚本,自动化完成工作。
开始工作
上面想法很好,但是实际行动起来我还是遇到了很多问题。
首先,技术路线的选取。最简单莫过于直接调用某云上的API接口,但是免费调用次数有限。当然,我最开始也最想采用的是走爬虫路线。有很多网站可以在线上传车辆照片并返回车型结果,我就想利用这一点解决车型识别的问题。然并卵,post请求无法响应,就想向selenium上靠,可是上传文件对话框阻碍了我进一步操作。虽然网上有很多解决对话框的方法,但是碍于时间紧且方法较复杂(短时我无法实现)等种种原因,我不得不采用了最简单直接的方法。PS:如果有做过类似的项目(对话框)的大佬请不吝赐教!
1.环境配置
编译环境:Python3.6,Spyder
依赖模块:shelve,PIL,shutil
2.申请API
打开百度云图像识别的网页链接:https://cloud.baidu.com/product/imagerecognition,创建一个项目,便可以得到API调用的接口。

找到并下载车型识别Python的SDK
车型识别的示例:
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('example.jpg')
""" 调用车辆识别 """
client.carDetect(image);
""" 如果有可选参数 """
options = {}
options["top_num"] = 3
options["baike_num"] = 5
""" 带参数调用车辆识别 """
client.carDetect(image, options)3.指定目录下所有车型的获得
对API调用返回JSON数据的清洗,提取所需要的信息(取第一个)
car_info=client.carDetect(img)
try:
car_color=car_info['color_result']
except:
car_color='无法识别'
try:
car_name=car_info['result'][0]['name']
car_score=car_info['result'][0]['score']
car_year=car_info['result'][0]['year']
except:
car_name='非车类'
car_score=1
car_year='无年份信息'
car_result=[car_color,car_name,car_score,car_year,file]获取指定目录下的所有车辆照片的车型
path='..'
img_path=path+'\\car_img'
#调用API获取指定目录下所有文件的车型,并将数据保存
m_files=os.listdir(img_path)
for i in range(len(m_files)):
results=[]
files_path=img_path+'\\'+m_files[i]
imgs=os.listdir(files_path)
for j in range(len(imgs)):
#out_path,img=img_cut(m_files[i],imgs[j])
result=get_info(out_path,img)
results.append(result)
data_path=path+'\\'+'data'+'\\'+m_files[i]
shelf_save(results,data_path)实际操作中,发现有些图片识别不出来,便裁剪一下,保留下半部分,竟然发现它能识别了。因此,在上传图片时首先对图片进行了裁剪。
#图片裁剪
def img_cut(file,img):
img_read = Image.open(path+'\\car_img\\'+file+'\\'+img)
a = [0,1300,3310,2600]
box = (a)
roi = img_read.crop(box)
out_path = path+'\\图片处理\\'+file
if not os.path.exists(out_path):
os.mkdir(out_path)
roi.save(out_path+'\\'+img)
return out_path,img我这里使用了shelve模块将每个文件夹数据进行保存与调用
def shelf_load(path):
shelfFile = shelve.open(path)
results=shelfFile['results']
shelfFile.close()
return results
def shelf_save(results,path):
shelfFile = shelve.open(path)
shelfFile['results'] = results
shelfFile.close() 4.根据车型分类建立文件夹
话不多说,直接上代码
#按车型分类建立文件夹
for i in range(len(m_datas)):
_path=path+'\\data\\'+m_datas[i]
datas=shelf_load(_path)
for j in range(len(datas)):
ori_path=img_path+'\\'+m_datas[i]+'\\'+datas[j][4]
if datas[j][1]=='非车类':
if not os.path.exists(path+'\\results\\未知'):
os.mkdir(path+'\\results\\未知')
now_path=path+'\\results\\未知\\'+datas[j][4]
shutil.copy(ori_path,now_path)
continue
for brand in brands:
if brand in datas[j][1]:
if not os.path.exists(path+'\\results\\'+brand):
os.mkdir(path+'\\results\\'+brand)
now_path=path+'\\results\\'+brand+'\\'+datas[j][4]
shutil.copy(ori_path,now_path)
break
if brand=='其他':
if not os.path.exists(path+'\\results\\未知'):
os.mkdir(path+'\\results\\未知')
now_path=path+'\\results\\未知\\'+datas[j][4]
shutil.copy(ori_path,now_path)运行结果
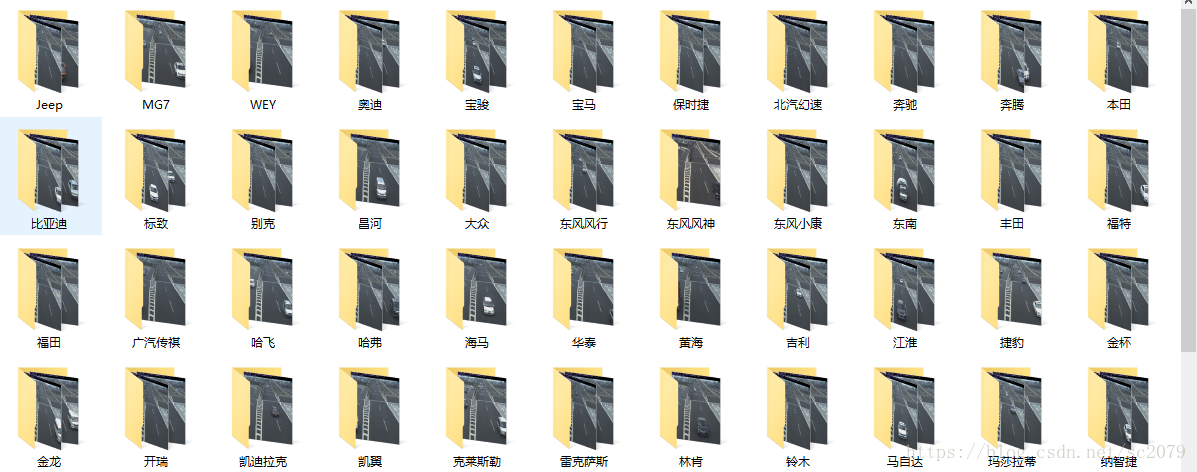
由于调用次数限制,我跑了480张图片,仅有几张无法识别,识别率还可以。至于准确率,我简单翻看了一些目录下的照片,虽然有个别车型识别错误,但大多还可以的。这里仅展示已经自动分类好的文件。
结语
由于时间仓促,代码还没整理好。另外其他细节(如存储车型brands数组,获得shelve数据、根文件夹下子文件下有哪些等)这里就不一一展示了。如果实在需要,过段时间我发个Github 链接。
车型识别API调用与批量分类车辆图片的更多相关文章
- C#百度图片识别API调用返回数据包解析
百度图片识别api接口 public static JObject GeneralBasic(string apikey,string secretkey,string path) { var cli ...
- 菜品识别 API调用
#get_access_token.py #获取access_token 1 import requests def GetToken(API_KEY,SECRET_KEY): url = 'http ...
- LUIS 语义识别API调用方法
本例使用itchat获取微信文字消息,发送给LUIS返回识别消息,再将返回消息格式化后通过微信发回 关于itchat的使用参考我的另外一篇随笔itchat个人练习 语音与文本图灵测试例程 # -*- ...
- Elasticsearch 5.4.3实战--Java API调用:批量写入数据
这个其实比较简单,直接上代码. 注意部分逻辑可以换成你自己的逻辑 package com.cs99lzzs.elasticsearch.service.imp; import java.sql.Tim ...
- Python调用百度地图API实现批量经纬度转换为实际省市地点(api调用,json解析,excel读取与写入)
1.获取秘钥 调用百度地图API实现得申请百度账号或者登陆百度账号,然后申请自己的ak秘钥.链接如下:http://lbsyun.baidu.com/apiconsole/key?applicatio ...
- 脸识别API微软牛津项目
微软牛津项目人脸识别API初探 按照董子的这篇博客中的介绍,到微软牛津项目的网站申请到测试用的人脸识别Key,按照官方文档的介绍,把wpf项目建好之后,按照一步步的流程下来就可以完成example中的 ...
- 【百度地图API】如何批量转换为百度经纬度
原文:[百度地图API]如何批量转换为百度经纬度 摘要: 百度地图API的官网上提供了常用坐标转换的示例.但是,一次只能转换一个,真的非常麻烦!!这里结合了官方的示例,自制一个批量转换工具,供大家参考 ...
- 免费人脸识别APi
今天对应一些免费的人脸识别的api 做了一下简单的对比,觉得百度开发出来的人脸识别接口还是最符合的我的要求,简单易用,容易上手. 据说百度的一些门禁也使用上了人脸识别的功能了,功能很强大,而且能识别出 ...
- Python3 下实现 腾讯人工智能API 调用
1.背景 a.鹅厂近期发布了自己的人工智能 api,包括身份证ocr.名片ocr.文本分析等一堆API,因为前期项目用到图形OCR,遂实现试用了一下,发现准确率还不错,放出来给大家共享一下. b.基于 ...
随机推荐
- js中的正则表达式小结1
正则表达式总结 创建正则对象:var regex=new RegExp(/\d/); 一般都用直接量,写法更简洁:var regex=/\d/; test()方法用来验证字符串是否符合规则,返回tru ...
- 最新 猎豹移动java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.猎豹移动等10家互联网公司的校招Offer,因为某些自身原因最终选择了猎豹移动.6.7月主要是做系统复习.项目复盘.Leet ...
- JS节流和防抖的区分和实现详解
参考链接:http://caibaojian.com/throttle-debounce.html
- NOIP 2015:信息传递
题目描述 有n个同学(编号为1到n)正在玩一个信息传递的游戏.在游戏里每人都有一个固定的信息传递对象,其中,编号为i的同学的信息传递对象是编号为Ti同学. 游戏开始时,每人都只知道自己的生日.之后每一 ...
- [转帖]SSH远程登录配置文件sshd_config详解
SSH远程登录配置文件sshd_config详解 2016年06月02日 17:42:25 Field_Yang 阅读数 61386 版权声明:本文为博主原创文章,遵循CC 4.0 by-sa版权 ...
- HanLP-基于HMM-Viterbi的人名识别原理介绍
Hanlp自然语言处理包中的基于HMM-Viterbi处理人名识别的内容大概在年初的有分享过这类的文章,时间稍微久了一点,有点忘记了.看了 baiziyu 分享的这篇比我之前分享的要简单明了的多.下面 ...
- Chrome浏览器控制台报 POST http://*** net::ERR_BLOCKED_BY_CLIENT
开发项目广告模块时,遇到前端提交的请求后台拿不到,好像被什么拦截了,查看了过滤器,拦截器都无错误,且请求也到不了拦截器,chrome浏览器报:ERR_BLOCKED_BY_CLIENT错误 搞腾一半天 ...
- springboot集成mongoDB简易使用
1.首先是添加Spring Data mongo的配置依赖 <dependency> <groupId>org.springframework.boot</groupId ...
- ros 配置udev
显示已经链接设备 lsusb 显示挂载点 ls /dev/ttyACM* /dev/ttyUSB* 可以看到 ttyUSB0 和 ttyUSB1 对应哪一个设备不确定,因此,我们就需要一种方法来保证每 ...
- 超级简单的requests模块教程
在web后台开发过程中,会遇到需要向第三方发送http请求的场景,python中的requests库可以很好的满足这一要求,这里简要记录一下requests模块的使用! 说明: 这里主要记录一下req ...