MySQL的sql解析
首先看一下示例语句
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
然而它的执行顺序是这样的
1 FROM <left_table>
2 ON <join_condition>
3 <join_type> JOIN <right_table> 第二步和第三步会循环执行
4 WHERE <where_condition> 第四步会循环执行,多个条件的执行顺序是从左往右的。
5 GROUP BY <group_by_list>
6 HAVING <having_condition>
7 SELECT 分组之后才会执行SELECT
8 DISTINCT <select_list>
9 ORDER BY <order_by_condition>
10 LIMIT <limit_number> 前9步都是SQL92标准语法。limit是MySQL的独有语法
来看一个例子
假设有表1和表2
table1
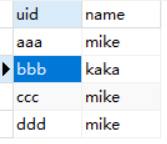
table2
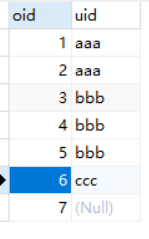
1、from
2个表联合查询得到他们的笛卡尔积CROSS JOIN,产生 虚表VT1

2、ON过滤
对 虚表VT1 进行ON筛选,只有那些符合的行才会被记录在虚表VT2中。
注意:这里因为语法限制,使用了'WHERE'代替,从中读者也可以感受到两者之间微妙的关系;

3.OUTER JOIN添加外部列
如果指定了 OUTER JOIN(比如left join、 right join) ,那么 保留表中未匹配的行 就会作为外部行 添加 到 虚
拟表VT2 中,产生 虚拟表VT3 。
如果FROM子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3
这三个步骤,一直到处理完所有的表为止
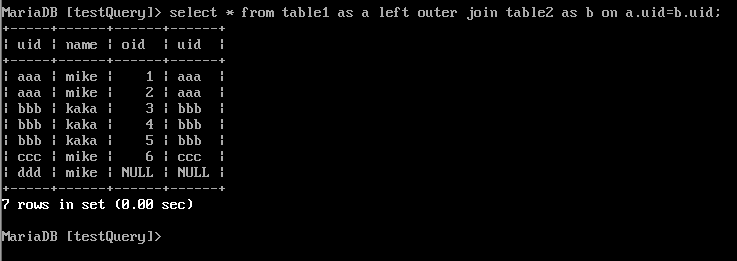
4.WHERE
对 虚拟表VT3 进行WHERE条件过滤。只有符合的记录才会被插入到 虚拟表VT4 中。
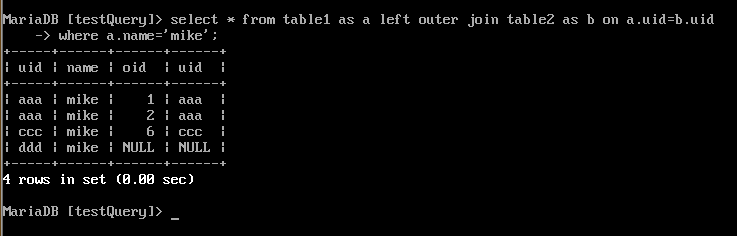
5.GROUP BY
根据group by子句中的列,对VT4中的记录进行分组操作,产生 虚拟表VT5 。
注意:
其后处理过程的语句,如SELECT,HAVING,所用到的列必须包含在GROUP BY中。对于没有出现的,得用聚合函
数;
原因:
GROUP BY改变了对表的引用,将其转换为新的引用方式,能够对其进行下一级逻辑操作的列会减少;
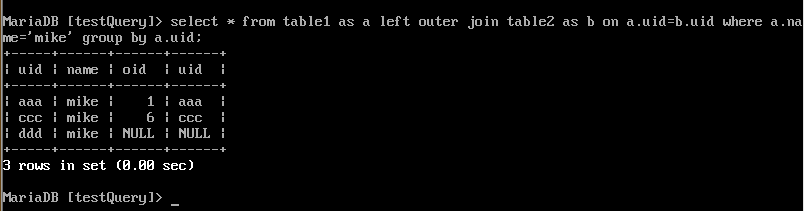
6.HAVING
对 虚拟表VT5 应用having过滤,只有符合的记录才会被 插入到 虚拟表VT6 中。

7.SELECT
这个子句对SELECT子句中的元素进行处理,生成VT5表。
(5-J1)计算表达式 计算SELECT 子句中的表达式,生成VT5-J1
8.DISTINCT
寻找VT5-1中的重复列,并删掉,生成VT5-J2
如果在查询中指定了DISTINCT子句,则会创建一张内存临时表(如果内存放不下,就需要存放在硬盘了)。这张
临时表的表结构和上一步产生的虚拟表VT5是一样的,不同的是对进行DISTINCT操作的列增加了一个唯一索引,以
此来除重复数据
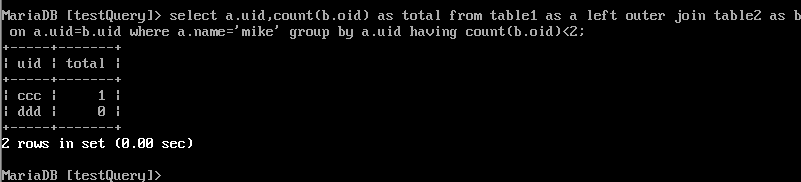
9.ORDER BY
从 VT5-J2 中的表中,根据ORDER BY 子句的条件对结果进行排序,生成VT6表。
注意:
唯一可使用SELECT中别名的地方
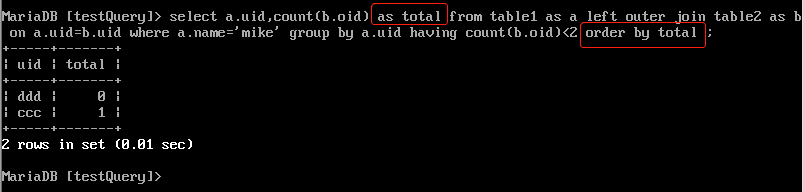
10.LIMIT(MySQL特有)
LIMIT子句从上一步得到的 VT6虚拟表 中选出从指定位置开始的指定行数据
注意:
offset 和 rows 的正负带来的影响;
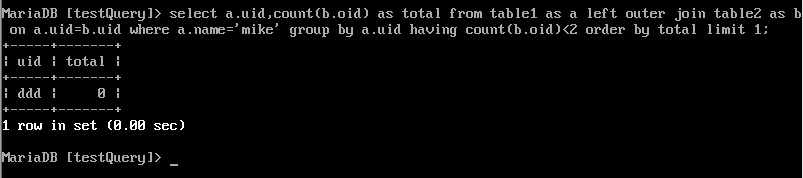
当偏移量很大时效率是很低的,可以这么做:
采用子查询的方式优化 ,在子查询里先从索引获取到最大id,然后倒序排,再取N行结果集
采用INNER JOIN优化 ,JOIN子句里也优先从索引获取ID列表,然后直接关联查询获得最终结果
解析顺序总结
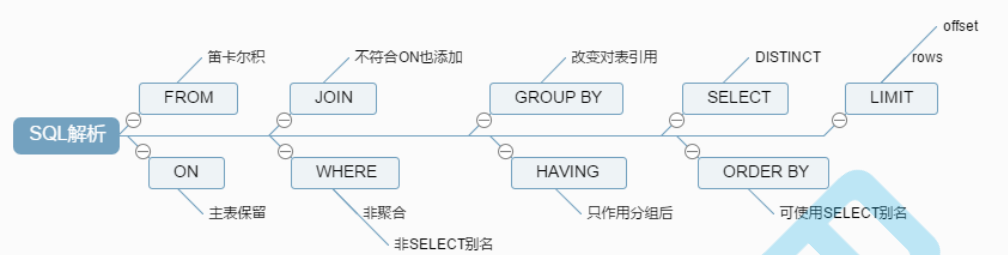
流程分析
1. FROM(将最近的两张表,进行笛卡尔积)---VT1
2. ON(将VT1按照它的条件进行过滤)---VT2
3. LEFT JOIN(保留左表的记录)---VT3
4. WHERE(过滤VT3中的记录)--VT4…VTn
5. GROUP BY(对VT4的记录进行分组)---VT5
6. HAVING(对VT5中的记录进行过滤)---VT6
7. SELECT(对VT6中的记录,选取指定的列)--VT7
8. ORDER BY(对VT7的记录进行排序)--VT8
9. LIMIT(对排序之后的值进行分页)--MySQL特有的语法
流程说明:
单表查询:根据 WHERE 条件过滤表中的记录,形成中间表(这个中间表对用户是不可见的);然后根据
SELECT 的选择列选择相应的列进行返回最终结果。 两表连接查询:对两表求积(笛卡尔积)并用 ON 条件和连接连接类型进行过滤形成中间表;然后根据
WHERE条件过滤中间表的记录,并根据 SELECT 指定的列返回查询结果。 笛卡尔积:行相乘、列相加 多表连接查询:先对第一个和第二个表按照两表连接做查询,然后用查询结果和第三个表做连接查询,以此
类推,直到所有的表都连接上为止,最终形成一个中间的结果表,然后根据WHERE条件过滤中间表的记录,
并根据SELECT指定的列返回查询结果。
MySQL的sql解析的更多相关文章
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序来 ...
- MySQL架构总览->查询执行流程->SQL解析顺序
Reference: https://www.cnblogs.com/annsshadow/p/5037667.html 前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后 ...
- 步步深入MySQL:架构->查询执行流程->SQL解析顺序!
一.前言 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序 ...
- 【转】MySQL批量SQL插入各种性能优化
原文:http://mp.weixin.qq.com/s?__biz=MzA5MzY4NTQwMA==&mid=403182899&idx=1&sn=74edf28b0bd29 ...
- mysql日志详细解析
MySQL日志: 主要包含:错误日志.查询日志.慢查询日志.事务日志.二进制日志: 日志是mysql数据库的重要组成部分.日志文件中记录着mysql数据库运行期间发生的变化:也就是说用来记录mysql ...
- mysql日志详细解析 [转]
原文出处:http://pangge.blog.51cto.com/6013757/1319304 MySQL日志: 主要包含:错误日志.查询日志.慢查询日志.事务日志.二进制日志: 日志是mysql ...
- 基于简单sql语句的sql解析原理及在大数据中的应用
基于简单sql语句的sql解析原理及在大数据中的应用 李万鸿 老百姓呼吁打土豪分田地.共同富裕,总有一天会实现. 全面了解你所不知道的外星人和宇宙真想:http://pan.baidu.com/s/1 ...
- MySQL数据库SQL层级优化
本篇主涉及MySQL SQL Statements层面的优化. 首先,推荐一个链接为万物之始:http://dev.mysql.com/doc/refman/5.0/en/optimization.h ...
- mysql日志详细解析【转载】
转自:http://pangge.blog.51cto.com/6013757/1319304 MySQL日志: 主要包含:错误日志.查询日志.慢查询日志.事务日志.二进制日志: 日志是mysql数据 ...
随机推荐
- linux Ubuntu14.04 make编译文件报错:No rule to make target `/usr/lib/libpython2.7.so', needed by `python/_pywraps2.so'. Stop.
错误过程:当“make”编译文件时报错No rule to make target `/usr/lib/libpython2.7.so', needed by `python/_pywraps2.so ...
- 3_PHP表达式_5_数据类型转换_类型强制转换
以下为学习孔祥盛主编的<PHP编程基础与实例教程>(第二版)所做的笔记. PHP类型转换分为类型自动转换和类型强制转换. 3.5.2 类型强制转换 类型强制转换允许编程人员手动将变量的数据 ...
- docker第二章--数据管理
- java线程的五种状态
五种状态 开始状态(new) 就绪状态(runnable) 运行状态(running) 阻塞状态(blocked) 结束状态(dead) 状态变化 1.线程刚创建时,是new状态 2.线程调用了sta ...
- css 盒子 取值
盒子:当我们设置一个标签宽高时,默认设置的是盒子里面content大小. 内容盒:content 填充盒:content+padding(overflow截取的区域) 边框盒:content+padd ...
- JSONObject和URL以及HttpURLConnection的使用
1 将java对象类转成json格式 首先引入依赖jar文件 注意依赖文件的版本号,高版本可能没有对应的类 2 我的实体类中包含内部类注意内部类要public才能被序列化成json格式 import ...
- python之csv操作
在使用python爬虫时或者其他情况,都会用到csv存储与读取的相关操作,我们在这里就浅谈一下: CSV(Comma-Separated Values)逗号分隔符,也就是每条记录中的值与值之间是用分号 ...
- 【问题】man命令打开的手册上链接怎么展开?
参考:How to follow links in linux man pages? 前言 在使用man查看命令帮助的时候,有些文字下面会有下划线.给人的感觉是一个链接,但是又打不开.那么到底是不是链 ...
- Django drf: 跨域机制
一.同源策略 二.CORS(跨域资源共享)简介 三.CORS基本流程 四.CORS两种请求流程 五.Django项目中支持CORS 一.同源策略 同源策略是一种约定,它是浏览器最核心的最基本的安全功能 ...
- RT-Thread--线程间同步
线程间同步 一个线程从传感器中接收数据并且将数据写到共享内存中,同时另一个线程周期性的从共享内存中读取数据并发送去显示,下图描述了两个线程间的数据传递: 如果对共享内存的访问不是排他性的,那么各个线程 ...