2.caffe初解
http://www.cnblogs.com/nwpuxuezha/p/4302024.html
原文链接:caffe.berkeleyvision.org/tutorial/layers.html
创建caffe模型,首先要在protocol buffer 定义文件(prototxt)中定义结构。
在caffe环境中,图像的明显特征是其空间结构。
|
主要layers |
主要功能 |
主要类型 |
其他 |
|
卷积层 |
提取特征 |
CONVOLUTION |
学习率、数据维度 |
|
池化层 |
特征池化 |
POOLING |
池化方法,数据维度 |
|
局部响应归一化层 |
临近抑制 |
LRN |
|
|
损失计算层 |
loss计算 |
SOFTMAX_LOSS EUCLIDEAN_LOSS HINGE_LOSS ACCURACY正确率 |
选择合适的loss 范数可选 |
|
激励层 |
非线性函数 |
ReLU SIGMOID TANH ABSVAL POWER BNLL |
ReLU收敛更快 |
|
数据层 |
数据源 |
Level-DB LMDB HDF5_DATA HDF5_OUTPUT IMAGE_DATA |
Level-DB和LMDB更加高效 |
|
一般层 |
INNER_PRODUCT 全连接层 SPLIT FLATTEN 类似shape方法 CONCAT ARGMAX MVN |
一、卷积层 Convolution:

Documents:注意维度变化与参数选择

1 Parameters (ConvolutionParameter convolution_param)
2
3 Required
4 num_output (c_o): 输出数(filter数)
5 kernel_size (or kernel_h and kernel_w): 指定卷积核
6
7 Strongly Recommended
8 weight_filler [default type: 'constant' value: 0]
9
10 Optional
11 bias_term [default true]: 指定是否提供偏置10
12 pad (or pad_h and pad_w) [default 0]: 指定输入图片的两侧像素填充量
13 stride (or stride_h and stride_w) [default 1]: 过滤器步长
14 group (g) [default 1]: 如果 g > 1, 我们限制每一个filter之间的连通性 对于输入的子集. 指定输入和输出被分为 g 组,第i输出组只会和第i输入组相连接.
15
16 Input
17
18 n * c_i * h_i * w_i
19
20 Output
21
22 n * c_o * h_o * w_o, where h_o = (h_i + 2 * pad_h - kernel_h) / stride_h + 1 and w_o likewise.
example:
1 layers {
2 name: "conv1"
3 type: CONVOLUTION
4 bottom: "data"
5 top: "conv1"
6 blobs_lr: 1 # learning rate multiplier for the filters
7 blobs_lr: 2 # learning rate multiplier for the biases
8 weight_decay: 1 # weight decay multiplier for the filters
9 weight_decay: 0 # weight decay multiplier for the biases
10 convolution_param {
11 num_output: 96 # learn 96 filters
12 kernel_size: 11 # each filter is 11x11
13 stride: 4 # step 4 pixels between each filter application
14 weight_filler {
15 type: "gaussian" # initialize the filters from a Gaussian
16 std: 0.01 # distribution with stdev 0.01 (default mean: 0)
17 }
18 bias_filler {
19 type: "constant" # initialize the biases to zero (0)
20 value: 0
21 }
22 }
23 }
二、池化层 Pooling:
参考链接 deeplearning.stanford.edu/wiki/index.php/池化
池化: 概述
在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做面临计算量的挑战。例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) * (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 892 * 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在 另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平 均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。
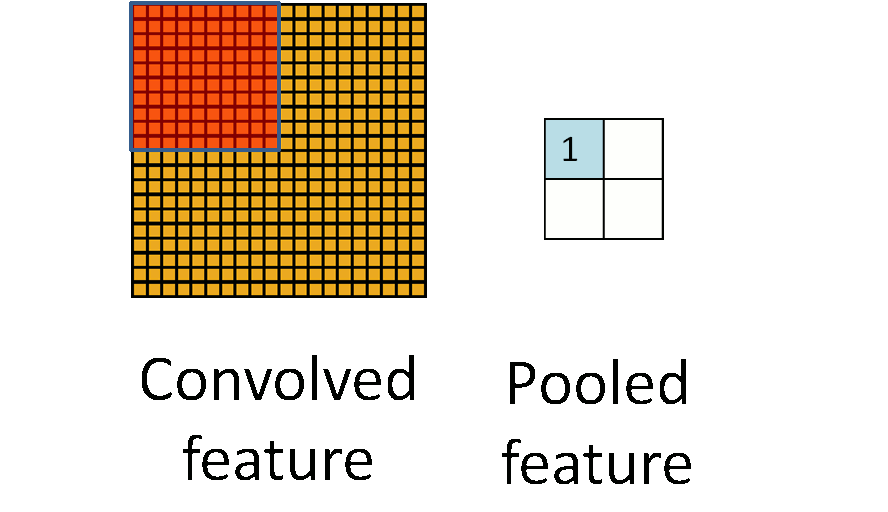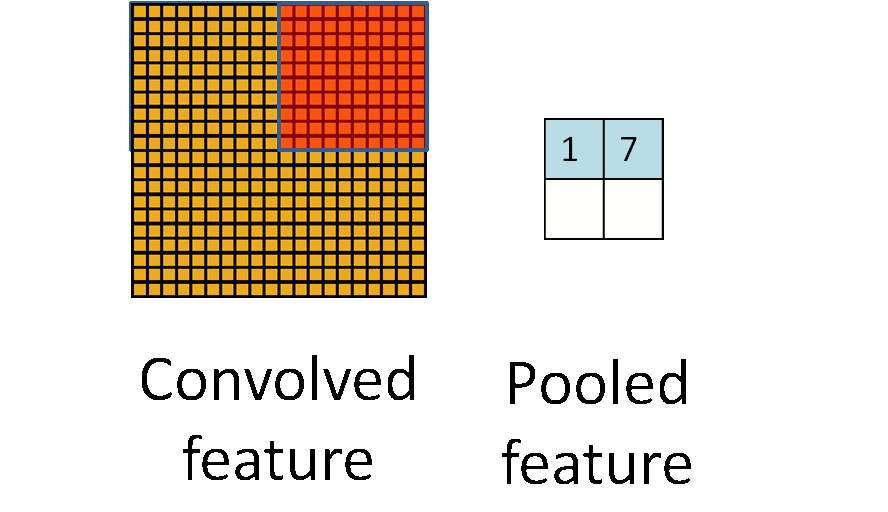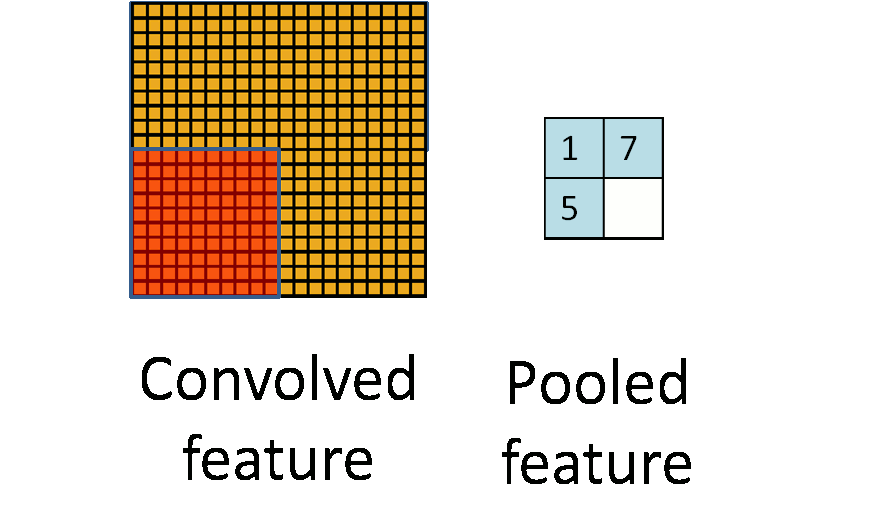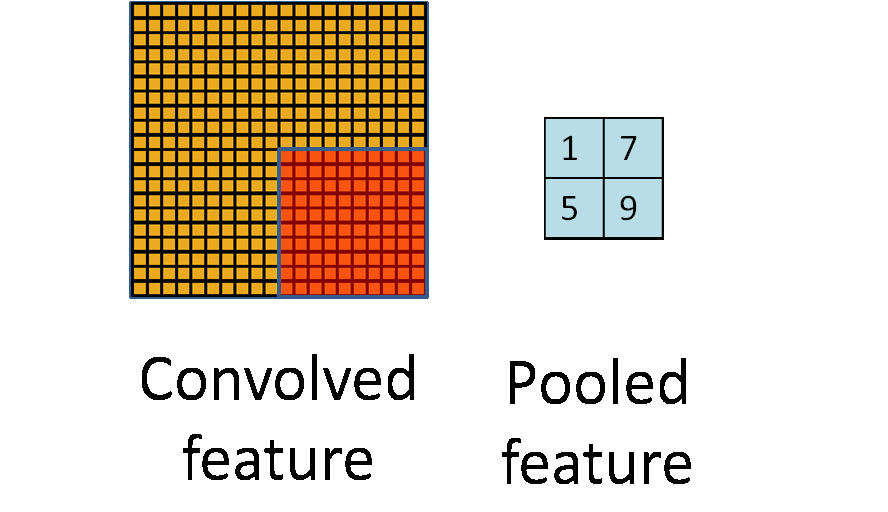
参数解释:
1 Required
2 kernel_size (or kernel_h and kernel_w):池化核
3 Optional
4 pool [default MAX]:指定池化方法. MAX, AVE, or STOCHASTIC(按照概率值大小随机选择,数值大的被选中的概率大)
5 pad (or pad_h and pad_w) [default 0]: 指定输入图片的两侧像素填充量
6 stride (or stride_h and stride_w) [default 1]:过滤器步长
7 Input
8 n * c * h_i * w_i
9 Output
10 n * c * h_o * w_o,where h_o = (h_i + 2 * pad_h - kernel_h) / stride_h + 1 and w_o likewise..
示例:
1 layers {
2 name: "pool1"
3 type: POOLING
4 bottom: "conv1"
5 top: "pool1"
6 pooling_param {
7 pool: MAX
8 kernel_size: 3 # 3*3 区域池化
9 stride: 2 # (in the bottom blob) between pooling regions
10 }
11 }
2.caffe初解的更多相关文章
- 基于window7+caffe实现图像艺术风格转换style-transfer
这个是在去年微博里面非常流行的,在git_hub上的代码是https://github.com/fzliu/style-transfer 比如这是梵高的画 这是你自己的照片 然后你想生成这样 怎么实现 ...
- caffe的python接口学习(7):绘制loss和accuracy曲线
使用python接口来运行caffe程序,主要的原因是python非常容易可视化.所以不推荐大家在命令行下面运行python程序.如果非要在命令行下面运行,还不如直接用 c++算了. 推荐使用jupy ...
- 基于Caffe的Large Margin Softmax Loss的实现(中)
小喵的唠叨话:前一篇博客,我们做完了L-Softmax的准备工作.而这一章,我们开始进行前馈的研究. 小喵博客: http://miaoerduo.com 博客原文: http://www.miao ...
- 基于Caffe的Large Margin Softmax Loss的实现(上)
小喵的唠叨话:在写完上一次的博客之后,已经过去了2个月的时间,小喵在此期间,做了大量的实验工作,最终在使用的DeepID2的方法之后,取得了很不错的结果.这次呢,主要讲述一个比较新的论文中的方法,L- ...
- 基于Caffe的DeepID2实现(下)
小喵的唠叨话:这次的博客,真心累伤了小喵的心.但考虑到知识需要巩固和分享,小喵决定这次把剩下的内容都写完. 小喵的博客:http://www.miaoerduo.com 博客原文: http://ww ...
- 基于Caffe的DeepID2实现(中)
小喵的唠叨话:我们在上一篇博客里面,介绍了Caffe的Data层的编写.有了Data层,下一步则是如何去使用生成好的训练数据.也就是这一篇的内容. 小喵的博客:http://www.miaoerduo ...
- 基于Caffe的DeepID2实现(上)
小喵的唠叨话:小喵最近在做人脸识别的工作,打算将汤晓鸥前辈的DeepID,DeepID2等算法进行实验和复现.DeepID的方法最简单,而DeepID2的实现却略微复杂,并且互联网上也没有比较好的资源 ...
- 基于英特尔® 至强™ 处理器 E5 产品家族的多节点分布式内存系统上的 Caffe* 培训
原文链接 深度神经网络 (DNN) 培训属于计算密集型项目,需要在现代计算平台上花费数日或数周的时间方可完成. 在最近的一篇文章<基于英特尔® 至强™ E5 产品家族的单节点 Caffe 评分和 ...
- 基于英特尔® 至强 E5 系列处理器的单节点 Caffe 评分和训练
原文链接 在互联网搜索引擎和医疗成像等诸多领域,深度神经网络 (DNN) 应用的重要性正在不断提升. Pradeep Dubey 在其博文中概述了英特尔® 架构机器学习愿景. 英特尔正在实现 Prad ...
随机推荐
- 【c# 学习笔记】接口
一.什么是接口 接口 可以理解为对一组方法声明进行的同一命名,但这些方法没有提供任何实现.也就是说,把一组方法声明在一个接口中,然后继承于该接口的类都 需要实现这些方法. 例如,很多类型(比如int ...
- 學校 iPad 使用學校google帳號登入Google Drive 提示"裝置政策提醒"的解決方法
因爲學校iPad 是給學生和老師使用,大多數是不需要設置鎖屏密碼的,然後 Gsuite 默認是開啓 “行動管理服務” 的策略為基本,就是需要設備設置鎖屏密碼以保障資料安全,不那麽容易被竊取. 然後就出 ...
- excel自学笔记 from av50264533
1.函数公式 MINUTE(serial_number) 函数解读 Serial_number 表示一个时间值,其中包含要查找的分钟 函数公式 NOW() 函数解读 显示出现在的时间 计算通话时 ...
- CentOS系统安装配置mysql
一.mysql安装 安装mysql数据库: yum install -y mysql mysql-server 判断mysql是否启动成功: service mysqld start 二.mysql配 ...
- GC(Garbage Collection)
GC(Garbage Collection) GC背景 创建对象会消耗内存,如果不回收对象占用的内存,内存使用率会越来越高,最终出现OutOfMemoryError(OOM) 在C++中专 ...
- Python之对象持久化笔记
pickle 序列化为字符串 .dumps(obj): 将对象序列为字符串 .loads(s): 从字符串反序列化对象 例如 import pickle person = {'name': 'Tom' ...
- STM32固件库模板下载以及固件库学习方法
固件库模板下载 固件库模板新建过程: 下载我们上节的固件库文件 电脑新建一个文件夹命名为Fwlib-Template,在此文件夹下分别新建DOC Libraries Project User 这四个文 ...
- java 用户线程和守护线程
在Java中通常有两种线程:用户线程和守护线程(也被称为服务线程)通过Thread.setDaemon(false)设置为用户线程通过Thread.setDaemon(true)设置为守护线程线程属性 ...
- atomikos 优化JDBC性能
JDBC performance comes for free with our pooling DataSource classes: AtomikosDataSourceBean for XA-e ...
- Spring 后台方法 重定向 与 转发
一.重定向:重定向是客户端行为,在使用时,务必使用全路径,否则可能因为外部环境导致错误 1.URL改变为重定向的URL地址 2.前台页面不能使用Ajax请求提交, 应该使用form表单提交 方法一.参 ...