一、HDFS 原理分析
HDFS 全称 Hadoop Distribute File System,是 Hadoop 的一个分布式文件系统
一、HDFS 的系统结构
1.1 数据块 —— block
- 文件在 HDFS 上分块存储。
- 一个文件分多少块,是按照你设置的存储单位大小算的。
- 设置存储单位时,不能太大,也不能太小。
- 太大:处理数据时,需要教高的配置。
- 太小:数据块的映射信息是存在 NameNode 的内存中(一个快占用 150 字节),内存也是受限的,如果块太小,会占用较多 namenode 的存储空间。
80M 文件,1M一个块,就会分成80块数据。占用 NameNode 内存 80 * 150 字节
80M 文件,64M一个块,分2块一块:64M,一块:16M(如果小于块大小,就按照实际存储)。占用 NameNode 内存 2 * 150 字节
总结如下:
- 数据块是 HDFS 中基本的数据存储单位,一般大小为64M/128M/256M,一个大文件根据数据块的大小,将文件分为若干个块。
- NameNode 存储的文件对应的 block 映射信息;而 datanode 存储块信息对应的数据。
- 块越小读取的速度就越快,但是整体占用 NameNode 的空间就越大,因为不管块大小一个块所占用的 NameNode 内存存储空间为一般为150字节。
- 一个大文件会被拆分成一个个的块,然后存储于不同的机器。对于大规模的集群会存储在不同的机架上,如果一个文件少于 Block 大小,那么实际占用的空间为其文件的大小。
- 数据块也是基本的读写单位,类似于磁盘的扇区,每次都是读写一个块。读写多个块就合成了一个文件。
- 为了容错,文件的所有数据块都会有副本,也就是说复制的是数据块而不是单独的一个文件被复制了,默认复制3份,可以在 hdft-site.xml 里进行配置。
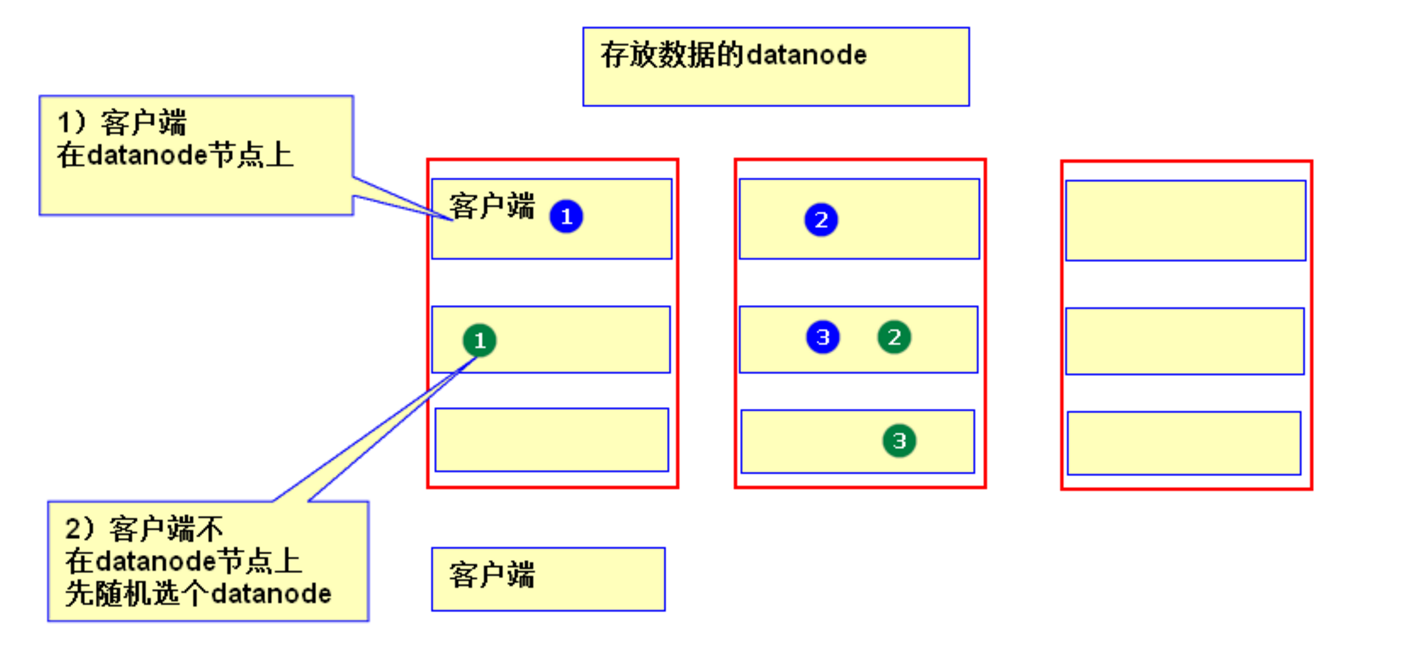
- 副本的数据的存储规则:
- 若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
- 若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
1.2 各组件介绍
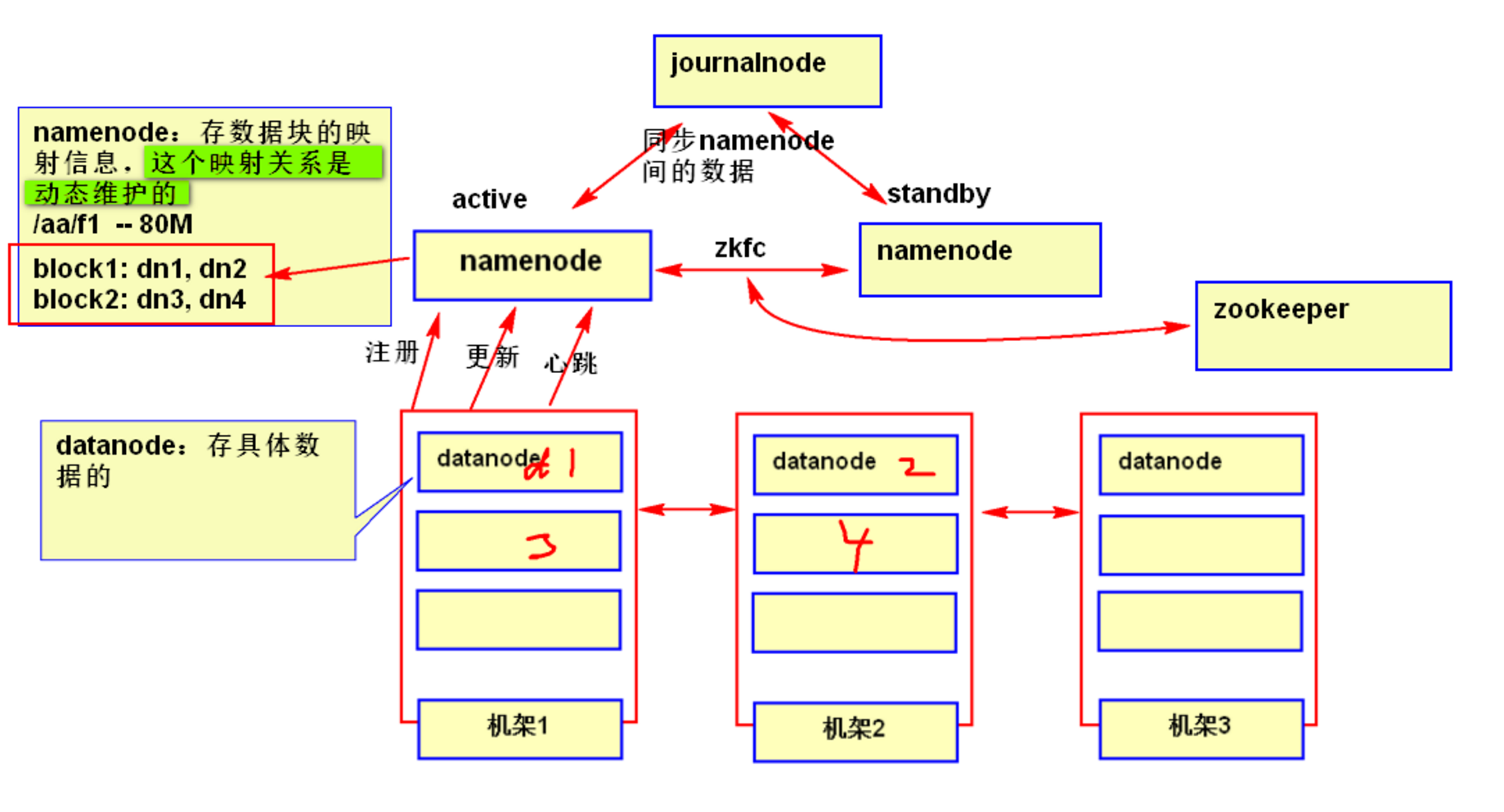
NameNode:
- 是整个集群的中心,负责安排管理集群中数据的存储并记录存储文件的元数据和负责客户端对文件的访问。
- HA 模式下,一般有一个 active 状态的 NameNode,若干个 standby 状态的 NameNode,其中,active 状态的 NameNode 负责所有的客户端操作,standby 状态的 NameNode 处于从属地位,维护着数据状态,随时准备切换。
- 存储文件的元数据(metadata),主要包括整个文件系统的目录树、文件名与 blockid 的映射关系、blockid 在哪个 datanode 上等。
- 在运行时把所有的元数据都保存到 NameNode 机器的内存中,所以整个 HDFS 可存储的文件数受限于 NameNode 的内存大小。
- 一个 block 在 NameNode 中对应一条记录。
- NameNode 的元数据的镜像文件会保存到本地磁盘,但不保存 block 具体的位置信息,而是由 DataNode 注册和运行时进行上报维护。
- NameNode 完蛋了,那整个 HDFS 也就完蛋了,所以要采用冗余的方案来保证 NameNode 的高可用性。
DataNode:
- 保存 block 块对应的具体数据。
- 负责数据的读写和复制操作。
- DataNode 启动时会向 NameNode 报告当前存储的数据块信息,也会持续的报告数据块的修改信息。
- DataNode 之间会进行互相通信,来完成复制数据块的动作,以保证数据的冗余性。
- DataNode 启动时要在 NameNode 上注册,当 DataNode 改变时,也要通知 NameNode 。DataNode 会定期向 NameNode 发送心跳,告知 NameNode 该节点的 DataNode 是可用的。
JournalNode:
- 负责两个状态的 NameNode 进行数据同步,保持数据一致
ZKFC:
- 作用是 HA 自动切换。会将 NameNode 的 active 状态信息保存到 zookeeper。
二、数据的读取和写入过程
2.1 HDFS 的数据写入过程
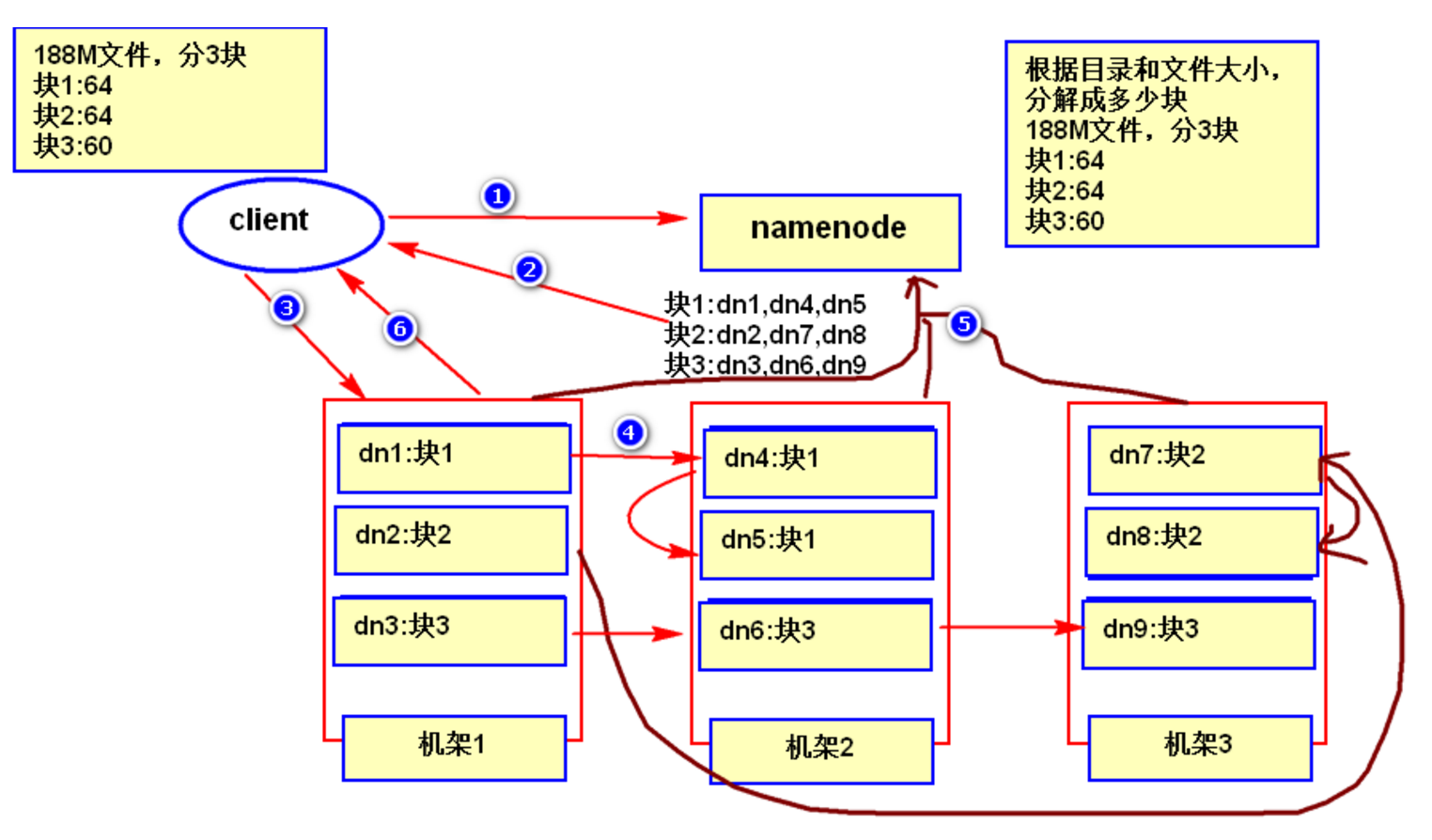
- 客户端发起数据写入请求,告诉 NameNode 要写入的文件信息;
- NameNode 根据你的情况(client端所在位置、文件大小)分配给你分配写入数据的位置也就是写到那几个机器上;
- 客户端根据 NameNode 反馈的信息向 DataNode 写入数据;
- DataNode 之前感觉副本数复制数据;
- 复制完成之后,各数据节点向 NameNode 上报 block 信息;
- DataNode 通知客户端已完成;
2.2 HDFS 的数据读取过程
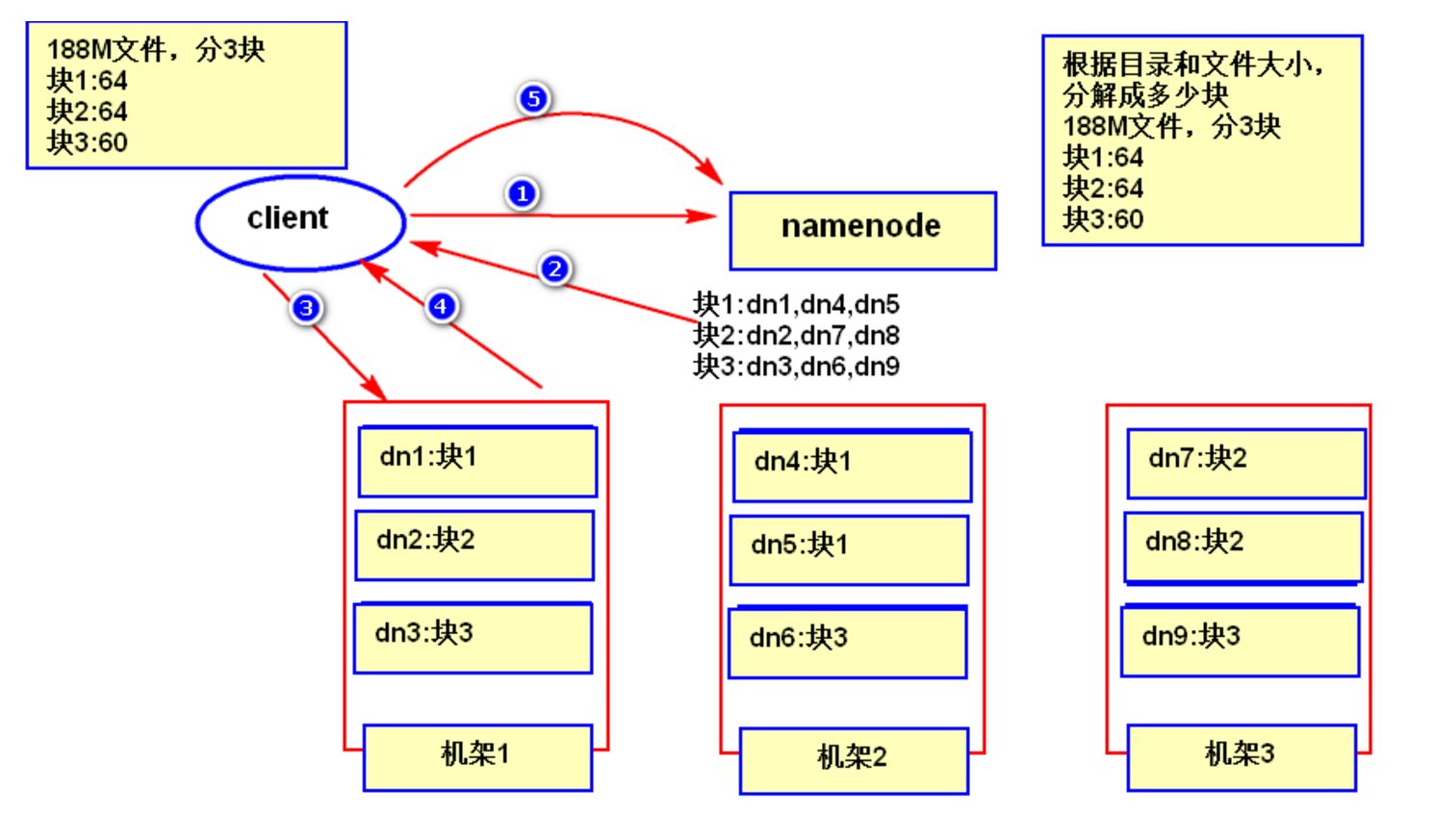
- 客户端发起读数据的请求;
- 告诉 NameNode 要读那个文件;
- NameNode 返回 block 信息列表(包括要读取的数据在那个机器上);
- 到指定的机器上读取具体的数据;
- DataNode 根据 block 信息找到数据的存储位置并返回数据给客户端;
- 客户端读完数据之后告诉 NameNode 已经读取完成;
三、HDFS 常用配置文件
3.1 hdfs-site.xml
| name | value | description |
|---|---|---|
| dfs.datanode.data.dir | /data1/dfs,/data2/dfs,/data3/dfs,/data4/dfs,/data5/dfs,/data6/dfs | datanode本地文件存放地址 |
| dfs.replication | 3 | 副本数 |
| dfs.namenode.name.dir | /data1/dfsname,/data2/dfsname,/data3/dfsname | namenode本地文件存放地址 |
| dfs.support.append | TRUE | 是否支持追加,但不支持并发线程往里追加 |
| dfs.permissions.enabled | FALSE | 是否开启目录权限 |
| dfs.nameservices | ns1 | 提供服务的NS逻辑名称,与core-site.xml里的对应,可以配置多个命名空间的名称,使用逗号分开即可。 |
| dfs.ha.namenodes.[nameservice ID] | nn1,nn2 | 命名空间中所有NameNode的唯一标示名称。可以配置多个,使用逗号分隔。该名称是可以让DataNode知道每个集群的所有NameNode。 |
| dfs.namenode.rpc-address.ns1.nn1 | nn1.hadoop:9000 | 指定NameNode的RPC位置 |
| dfs.namenode.http-address.ns1.nn1 | nn1.hadoop:50070 | 指定NameNode的Web Server位置 |
| dfs.namenode.rpc-address.ns1.nn2 | nn2.hadoop:9000 | 指定NameNode的RPC位置 |
| dfs.namenode.http-address.ns1.nn2 | nn2.hadoop:50070 | 指定NameNode的Web Server位置 |
| dfs.namenode.shared.edits.dir | qjournal://nn1.hadoop:8485;nn2.hadoop:8485/ns1 | 指定用于HA存放edits的共享存储,通常是namenode的所在机器 |
| dfs.journalnode.edits.dir | /data/journaldata/ | journaldata服务存放文件的地址 |
| fs.trash.interval | 2880 | 垃圾回收周期,单位分钟 |
| dfs.blocksize | 134217728 | 块的大小 |
| dfs.datanode.du.reserved | 2147483648 | 每个存储卷保留用作其他用途的磁盘大小 |
| dfs.datanode.fsdataset.volume.choosing.policy | org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy | datanode数据副本存放的磁盘选择策略,、有2种方式一种是轮询方式 (org.apache.hadoop.hdfs.server.datanode.fsdataset.RoundRobinVolumeChoosingPolicy,为默认方式),另一种为选择可用空间足够多的磁盘存储方式 (org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy)。 |
| dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold | 2147483648 | 当选择可用空间足够多的磁盘存储方式才生效,hdfs计算最大可用空间-最小可用空间的差值,如果差值小于此配置,则选择轮询方式存储 |
3.2 core-site.xml
| name | value | description |
|---|---|---|
| io.native.lib.available | true | 开启本地库支持 |
| fs.defaultFS | hdfs://ns1 | 客户端连接HDFS时,默认的路径前缀。默认文件服务的协议和NS(nameservices)逻辑名称,和hdfs-site里的对应此配置替代了1.0里的fs.default.name |
| io.compression.codecs | org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec | 相应编码的操作类,用逗号分隔 |
| ha.zookeeper.quorum | nn1.hadoop:2181,nn2.hadoop:2181,s1:2181 | HA使用的zookeeper地址 |
3.3 slaves
- slaves文件里面记录的是集群里所有DataNode的主机名
3.4 hadoop-env.sh
- HADOOP_CLASSPATH:hadoop的classpath
- JAVA_LIBRARY_PATH:java加载本地库的地址
- HADOOP_HEAPSIZE:java虚拟机使用的最大内存
- HADOOP_OPTS:hadoop启动公用参数
- HADOOP_NAMENODE_OPTS:namenode专用参数
- HADOOP_DATANODE_OPTS:datanode专用参数
- HADOOP_CLIENT_OPTS:hadoop client专用参数
一、HDFS 原理分析的更多相关文章
- HDFS原理分析之HA机制:avatarnode原理
一.问题描述 由于namenode 是HDFS的大脑,而这个大脑又是单点,如果大脑出现故障,则整个分布式存储系统就瘫痪了.HA(High Available)机制就是用来解决这样一个问题的.碰到这么个 ...
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- HDFS原理介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Googl ...
- HDFS 原理、架构与特性介绍--转载
原文地址:http://www.uml.org.cn/sjjm/201309044.asp 本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前H ...
- Hadoop数据管理介绍及原理分析
Hadoop数据管理介绍及原理分析 最近2014大数据会议正如火如荼的进行着,Hadoop之父Doug Cutting也被邀参加,我有幸听了他的演讲并获得亲笔签名书一本,发现他竟然是左手写字,当然这个 ...
- HDFS 原理、架构与特性介绍
本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前HDFS架构详尽分析 HDFS架构 •NameNode •DataNode •Senc ...
- 1、Hbase原理分析
一.Hbase介绍 1.1.对Hbase的认识 HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随机读写操作,HBase正是为此而出现. HBase参考 Google 的 Bigtable ...
- Handler系列之原理分析
上一节我们讲解了Handler的基本使用方法,也是平时大家用到的最多的使用方式.那么本节让我们来学习一下Handler的工作原理吧!!! 我们知道Android中我们只能在ui线程(主线程)更新ui信 ...
随机推荐
- javascript: Object对象生成URL参数
code: function makeQuery(queryObject) { const query = Object.entries(queryObject) .reduce((result, e ...
- Java集合:ArrayList (JDK1.8 源码解读)
ArrayList ArrayList几乎是每个java开发者最常用也是最熟悉的集合,看到ArrayList这个名字就知道,它必然是以数组方式实现的集合 关注点 说一下ArrayList的几个特点,也 ...
- python之实现图像的手绘效果
https://blog.csdn.net/riba2534/article/details/74152285 原图: b: c: d: 最终图:
- mac、window版编辑器 webstorm 2016... 永久破解方法。
第一步:从官网下载最新版本的webstorm编辑器(建议在官网下载,防止第三方插件恶意攻击!): 下载链接 http://www.jetbrains.com/webstorm/ , 点击 DOWN ...
- 进制之间转换——day_01
一.计算机文件大小单位 b = bit 位(比特) B = Byte 字节 1B = 8b #一个字节等于8位 简写 1Byte = 8 bit 1KB = 1024B 1MB = 1024KB 1G ...
- python-trade
https://tool.lu/pyc/在线反编译pyc import base64 correct = 'XlNkVmtUI1MgXWBZXCFeKY+AaXNt' flag = base64.b6 ...
- ubuntu server 18.04 网络配置
从17.10开始放弃在/etc/network/interfaces里固定IP的配置 配置文件是:/etc/netplan/50-cloud-init.yaml .用缩进来表示层级关系 冒号之后要有个 ...
- HTTP 1.1, 返回值100.
HTTP 1.1支持只发送header信息(不带任何body信息),如果服务器认为客户端有权限请求服务器,则返回100,否则返回401.客户端如果接受到100,才开始把请求body发送到服务器. 这样 ...
- 09-5.部署 EFK 插件
09-5.部署 EFK 插件 EFK 对应的目录:kubernetes/cluster/addons/fluentd-elasticsearch $ cd /opt/k8s/kubernetes/cl ...
- VUE 后台管理系统权限控制
谈一谈VUE 后台管理系统权限控制 前端权限从本质上来讲, 就是控制视图层的展示,比如说是某个页面或者某个按钮,后端权限可以控制某个用户是否能够查询数据, 是否能够修改数据等操作,后端权限大部分是基于 ...