[日志分析]Graylog2采集Nginx日志 主动方式
这次聊一下Graylog如何主动采集Nginx日志,分成两部分:
- 介绍一下 Graylog Collector Sidecar 是什么
- 如何配置 Graylog Collector Sidecar 采集nginx日志
一、首先介绍一下Graylog Collector Sidecar
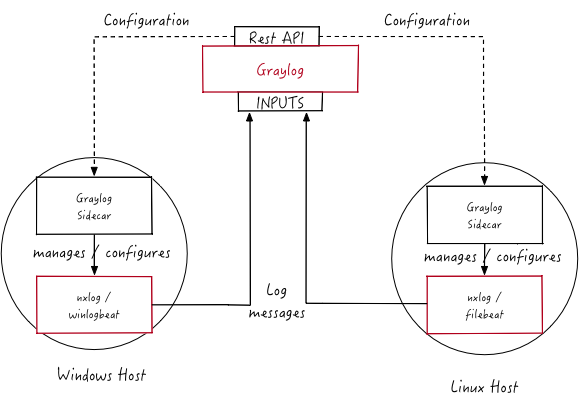
Graylog Collector Sidecar 是一个轻量级的日志采集器,通过访问graylog进行集中式管理,支持linux和windows系统。
Sidecar 守护进程会定期访问graylog的REST API接口获取Sidecar配置文件中定义的标签(tag),Sidecar在首次运行时会从graylog服务器拉取配置文件中指定标签(tag)的配置信息同步到本地。
目前Sidecar支持NXLog,Filebeat和Winlogbeat。他们都通过graylog中的web界面进行统一配置,支持Beats、CEF、Gelf、Json API、NetFlow等输出类型。
Graylog最厉害的在于可以在配置文件中指定Sidecar把日志发送到哪个graylog群集,并对graylog群集中的多个input进行负载均衡,这样在遇到日志量非常庞大的时候,graylog也能应付自如。
二、配置 Graylog Collector Sidecar 采集nginx日志
1、graylog服务器端配置:
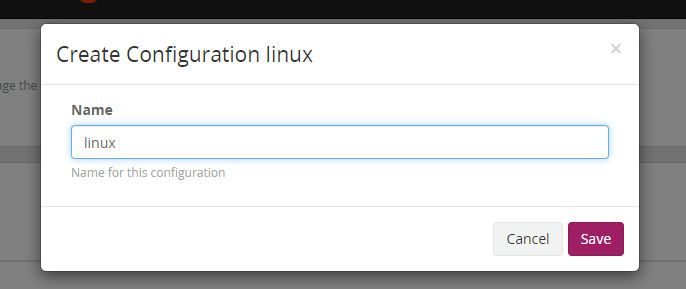
(1)导航栏 System/Collectors -> Collectors -> Manage Configurations -> Create configuration ,创建我们第一个名为linux的配置文件

(2)在输入栏写入配置文件的名字 linux ,表示这个是用来收集linux主机日志的配置文件,点击 save 保存
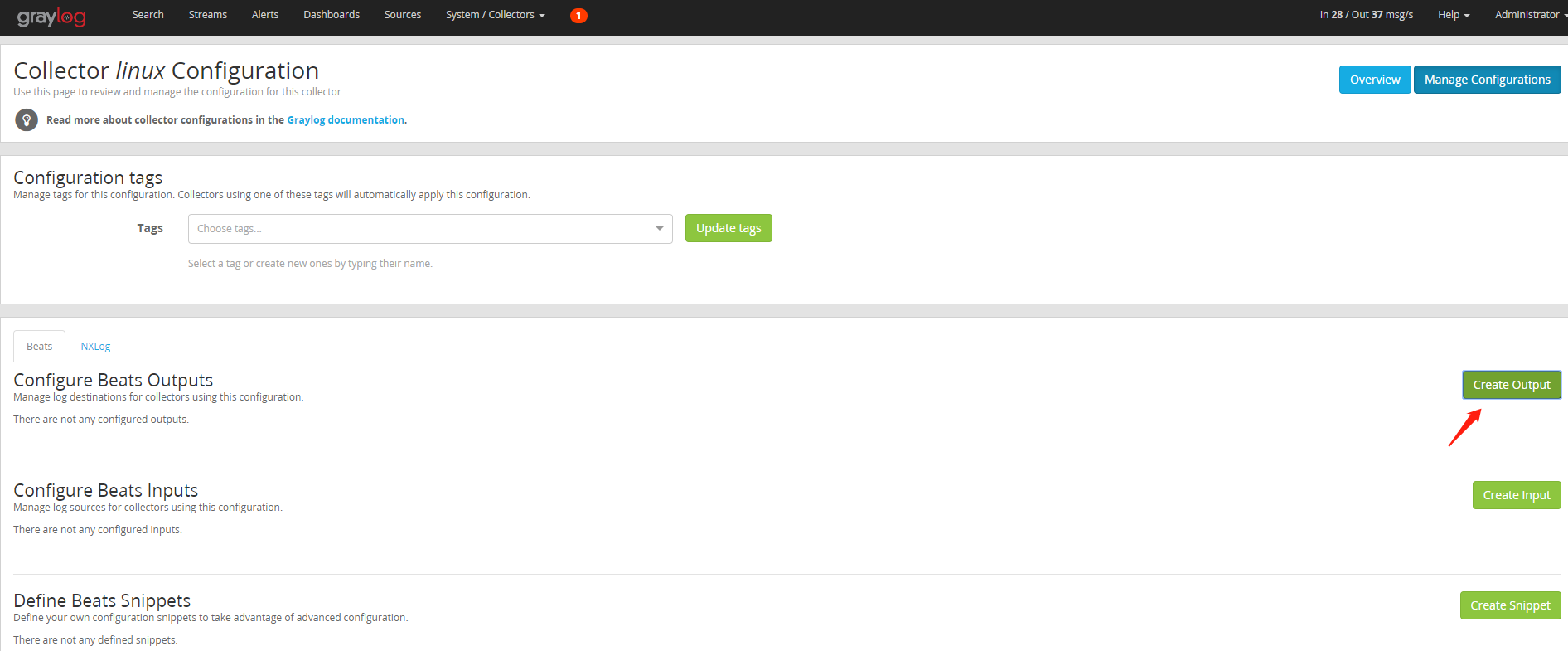
(3)创建 Beats Output ,我们在Configure Beats Outputs 中点击 Create Output ,Output 主要定义的是日志的类型以及它要流入的目标服务器(graylog),这就好比你寄出一个快递要写包裹接收的地址。
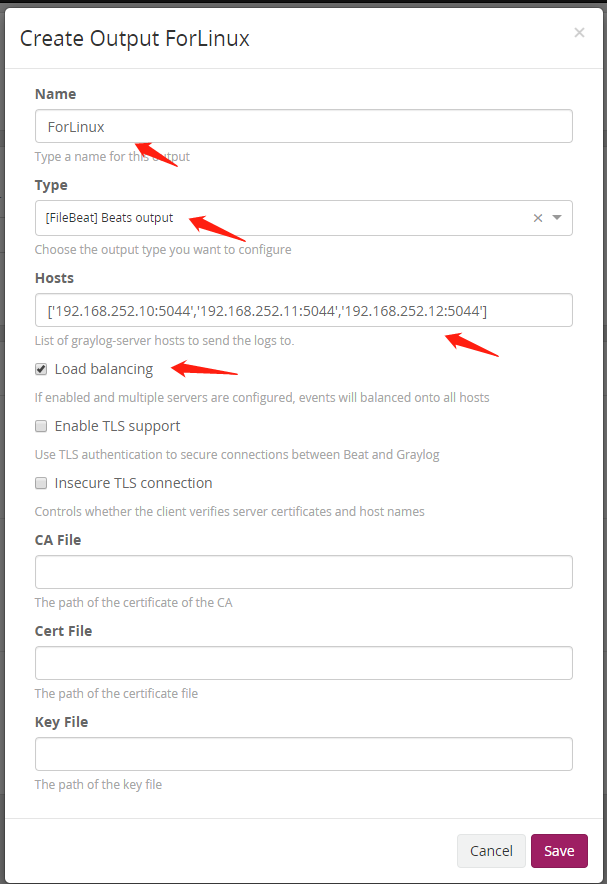
(4)Beats output 中需要填写的内容是output的名称(Name):ForLinux、类型(Type)我们选择Filebeat,Hosts里面填入的是graylog日志服务器的地址和端口(假设我们是三台graylog的集群192.168.252.10-12,5044是beats类型默认的端口),然后把Load balancing(负载均衡)选上,这样日志收集后就会轮询的向这三台主机发送日志了,最后点击 save 保存
(5)Beats Output 创建完毕之后,我们还要创建一个Input,点击 Configure Beats Inputs 下的 Create Input 进行创建。input相当于是属于ForLinux 配置下的一个tag,它用来定义来源日志的信息。还用发快递举例,这个input相当于填写发件人的地址信息,告知对方是谁发出的并寄给 ForLinux ,ForLinux 配置里面就是写的接收人的地址信息,你可以定义多个Input来区分不同的发件人,也就是来源日志的类型。
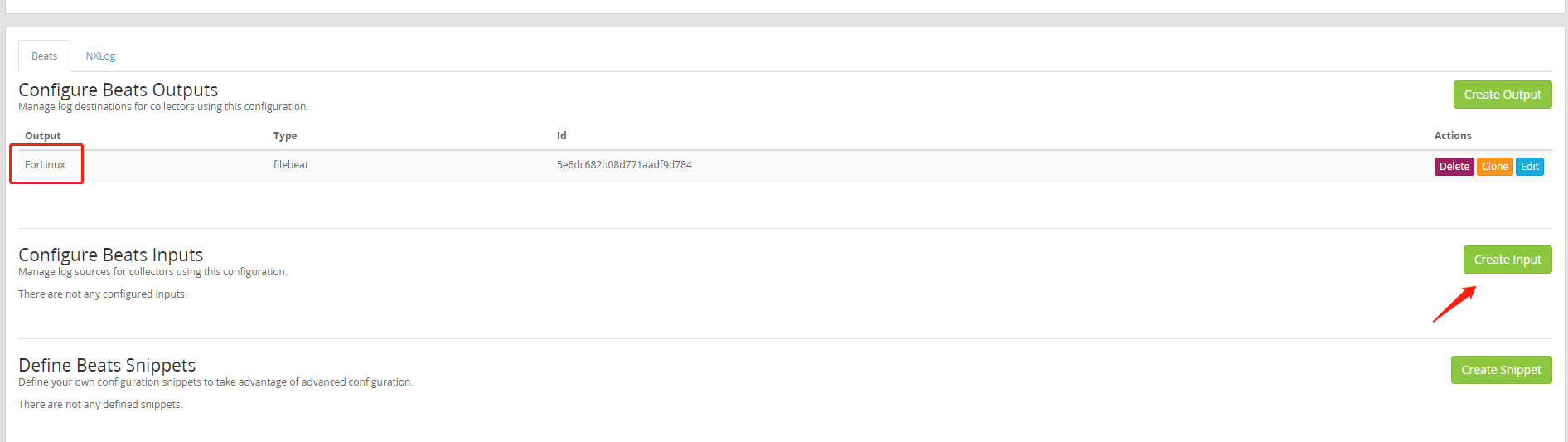
(6)Beats Input中要填写的是Name(谁发的)、Forward to(发给谁)、Type(linux or windows)、Path to Logfile(相当于发件人的详细地址)、Type of input file(ES分析日志中的type字段,便于区分日志类型),最后点击save保存
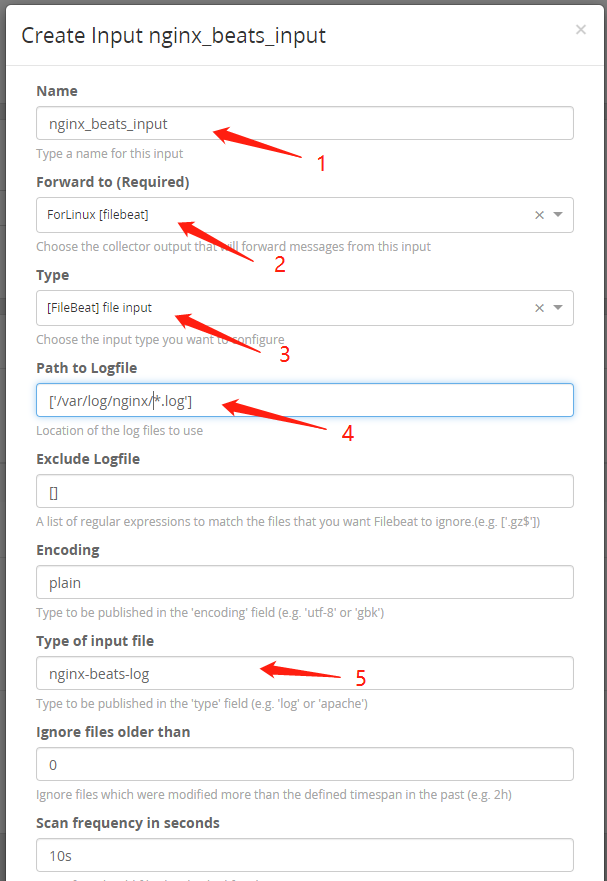
(7)保存好Beats Input之后不要忘记把创建好的tag进行Update tags,否则客户端将找不到这个tag。以上graylog服务器端的配置就都完成了。
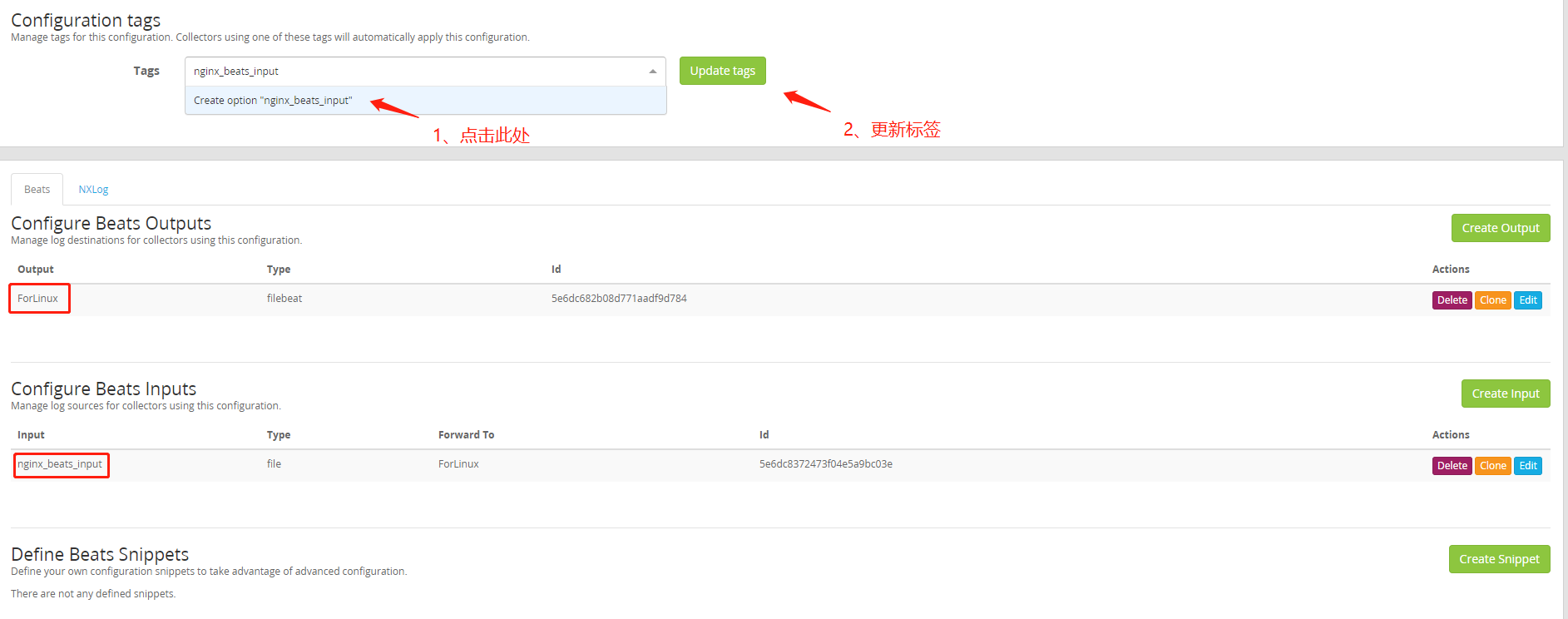
(8)graylog创建日志接收的Input 5044端口,导航栏System/Inputs -> Inputs ,在复选框里选择Beats,点击Launch new input

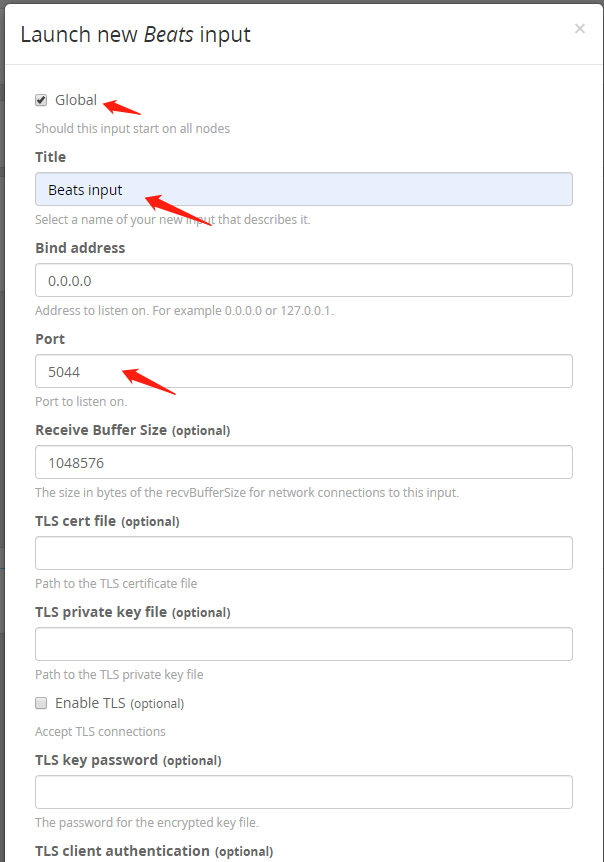
(9)如果你是garylog集群,选择Global,也就是在每个节点都启动5044端口,Title起个名字叫Beats input,端口保持默tcp 5044,最后点击save保存
(10)我们开始进行客户端的安装,我们以Ubuntu16.04为例,假设graylog服务器ip为192.168.252.10,nginx服务器主机名为nginx1:
1、在nginx1服务器上下载并安装collector-sidecar
wget https://github.com/Graylog2/collector-sidecar/releases/download/0.1.8/collector-sidecar_0.1.8-1_amd64.deb sudo /usr/bin/dpkg -i collector-sidecar_0.1.8-1_amd64.deb sudo /usr/bin/graylog-collector-sidecar -service install sudo systemctl enable collector-sidecar.service
2、编辑collector-sidecar配置文件:
vi /etc/graylog/collector-sidecar/collector_sidecar.yml
server_url: http://192.168.252.10:9000/api/
node_id: nginx1
update_interval: 10
tls_skip_verify: false
send_status: true
list_log_files:
collector_id: file:/etc/graylog/collector-sidecar/collector-id
cache_path: /var/cache/graylog/collector-sidecar
log_path: /var/log/graylog/collector-sidecar
log_rotation_time: 86400
log_max_age: 604800
tags:
- nginx_beats_input
backends:
- name: nxlog
enabled: false
binary_path: /usr/bin/nxlog
configuration_path: /etc/graylog/collector-sidecar/generated/nxlog.conf
- name: filebeat
enabled: true
binary_path: /usr/bin/filebeat
configuration_path: /etc/graylog/collector-sidecar/generated/filebeat.yml
service collector-sidecar restart
3、查看collector-sidecar的日志
tail -f /var/log/graylog/collector-sidecar/collector_sidecar.log

[日志分析]Graylog2采集Nginx日志 主动方式的更多相关文章
- [日志分析]Graylog2采集Nginx日志 被动方式
graylog可以通过两种方式采集nginx日志,一种是通过Graylog Collector Sidecar进行采集(主动方式),另外是通过修改nginx配置文件的方式进行收集(被动方式). 这次说 ...
- [日志分析]Graylog2采集mysql慢日志
之前聊了一下graylog如何采集nginx日志,为此我介绍了两种采集方法(主动和被动),让大家对graylog日志采集有了一个大致的了解. 从日志收集这个角度,graylog提供了多样性和灵活性,大 ...
- [日志分析]Graylog2进阶 通过正则解析Nginx日志
之前分享的 [日志分析]Graylog2采集Nginx日志 主动方式 这篇文章介绍了Graylog如何通过Graylog Collector Sidecar来采集nginx日志. 由于日志是未经处理的 ...
- elk系列3之通过json格式采集Nginx日志【转】
转自 elk系列3之通过json格式采集Nginx日志 - 温柔易淡 - 博客园http://www.cnblogs.com/liaojiafa/p/6158245.html preface 公司采用 ...
- Centos7 搭建 Flume 采集 Nginx 日志
版本信息 CentOS: Linux localhost.localdomain 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:24 UTC 2018 x ...
- 通过filebeat、logstash、rsyslog采集nginx日志的几种方式
由于nginx功能强大,性能突出,越来越多的web应用采用nginx作为http和反向代理的web服务器.而nginx的访问日志不管是做用户行为分析还是安全分析都是非常重要的数据源之一.如何有效便捷的 ...
- [日志分析]Graylog2进阶之获取Nginx来源IP的地理位置信息
如果你们觉得graylog只是负责日志收集的一个管理工具,那就too young too naive .日志收集只是graylog的最最基础的用法,graylog有很多实用的数据清洗和处理的进阶用法. ...
- elk系列3之通过json格式采集Nginx日志
preface 公司采用的LNMP平台,跑着挺多nginx,所以可以利用elk好好分析nginx的日志.下面就聊聊它吧. 下面的所有操作都在linux-node2上操作 安装Nginx nginx是开 ...
- Flume采集Nginx日志到HDFS
下载apache-flume-1.7.0-bin.tar.gz,用 tar -zxvf 解压,在/etc/profile文件中增加设置: export FLUME_HOME=/opt/apache-f ...
随机推荐
- 吴裕雄--天生自然python学习笔记:编写网络爬虫代码获取指定网站的图片
我们经常会在网上搜索井下载图片,然而一张一张地下载就太麻烦了,本案例 就是通过网络爬虫技术, 一次性下载该网站所有的图片并保存 . 网站图片下载并保存 将指定网站的 .jpg 和 .png 格式的图片 ...
- OpenCV 对两幅图像求和(求混合(blending))
#include <cv.h> #include <highgui.h> #include <iostream> using namespace cv; int m ...
- CDC与HDC的区别以及相互转换
CDC是MFC的DC的一个类 HDC是DC的句柄,API中的一个类似指针的数据类型. MFC类的前缀都是C开头的 H开头的大多数是句柄 这是为了助记,是编程读\写代码的好的习惯. CDC中所 ...
- spring和hibernate的集成
集成关系图: 项目目录树: User.java package com.donghai.bean; public class User { private String id; private Str ...
- Flash Builder 使用
1. 解决编译慢的问题:用记事本打开安装目录下的 FlashBuilder.ini ,将里面设置的容量都扩大一半,如-Xms256m改为 -Xms512m,另外几项类似修改: 定位到相应版本的sdks ...
- 在 mac osx 上安装OpenOffice并以服务的方式启动
OpenOffice是Apache基金会旗下的一款先进的开源办公软件套件,包含文本文档.电子表格.演示文稿.绘图.数据库等.包含Microsoft office所有功能.它不仅可以作为桌面应用供普通用 ...
- Lego:美团点评接口自动化测试实践
概述 接口自动化概述 众所周知,接口自动化测试有着如下特点: 低投入,高产出. 比较容易实现自动化. 和UI自动化测试相比更加稳定. 如何做好一个接口自动化测试项目呢? 我认为,一个“好的”自动化 ...
- 高效能Windows人士的N个习惯之一:启动篇
接触电脑十多年,经历了各种折腾阶段,这几年开始沉静下来,不再追求花哨的界面与应用,只注重工作的效率,逐渐养成了一套自己的操作习惯,感觉不错,特撰文分享.标题借用了一下<高效能人士的七个习惯> ...
- Ubuntu日常使用总结
Contents 使用了将近一年的Ubuntu,感觉不用windows也可以处理日常的事务.并且我相信只要合理利用Ubuntu,一定可以取代你手中的Windows.我不是说Ubuntu有多么好,只是从 ...
- jquery和zepto的异同
相同点 相同点: zepto: 是jquery 的 阉割版 是为移动端开发的库 jQuery的轻量级替代品.文件大小比较小 只有8k左右 ,是目前功能库中最小的一个,尽管不大,zepto 所提供的工具 ...