Git 常见问题 冲突原因分析及解决方案
仅结合本人使用场景,方法可能不是最优的
1. 忽略本地修改,强制拉取远程到本地
主要是项目中的文档目录,看的时候可能多了些标注,现在远程文档更新,本地的版本已无用,可以强拉
git fetch --all git reset --hard origin/dev git pull
关于commit和pull的先后顺序,commit——》pull——》push 和 pull——》commit——》push的顺序,两种情况都遇到过代码冲突。解决方法如下:
2. 未commit先pull,视本地修改量选择revert或stash
// 场景
同事 有新提交
我 没有pull -> 修改了文件 -> pull -> 提示有冲突
2.1 本地修改量小
如果本地修改量小,例如只修改了一行,可以按照以下流程
-> revert(把自己的代码取消) -> 重新pull -> 在最新代码上修改 -> [pull确认最新] -> commit&push
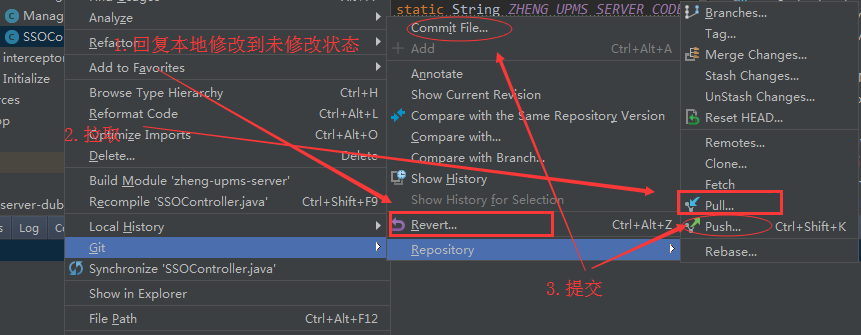
2.2 本地修改量大,冲突较多
有两种方式处理
-> stash save(把自己的代码隐藏存起来) -> 重新pull -> stash pop(把存起来的隐藏的代码取回来 ) -> 代码文件会显示冲突 -> 右键选择edit conficts,解决后点击编辑页面的 mark as resolved-> commit&push
-> stash save(把自己的代码隐藏存起来) -> 重新pull -> stash pop(把存起来的隐藏的代码取回来 ) -> 代码文件会显示冲突 -> 右键选择resolve conflict -> 打开文件解决冲突 ->commit&push
另外,由于我是通过IDEA来操作git的,所以显示冲突时,我是在图形化界面操作的示意如下

3. 已commit未push,视本地修改量选择reset或直接merge
// 场景
同事 有新提交
我 没有pull -> 修改了文件 -> commit -> pull -> 提示有冲突
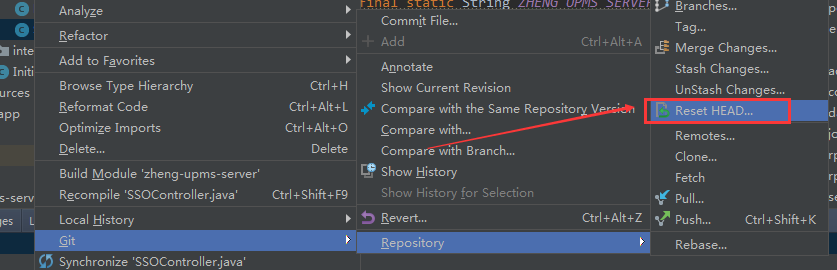
3.1 修改量小,直接回退到未提交的版本(可选择是否保存本地修改)
如果本地修改量小,例如只修改了一行,可以按照以下流程
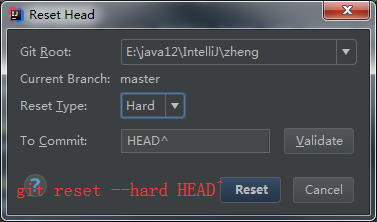
-> reset(回退到未修改之前,选hard模式,把自己的更改取消) -> 重新pull -> 在最新代码上修改 -> [pull确认最新] -> commit&push
ps:实际上完全可以采取直接merge的方法,这里主要是根据尽量避免merge的原则,提供一种思路
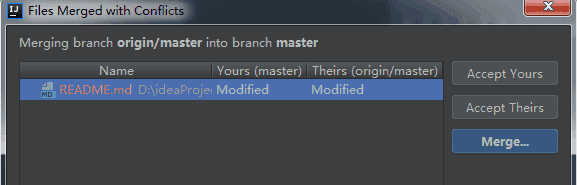
3.2 修改量大,直接merge,再提交(目前常用)
-> commit后pull显示冲突 -> 手动merge解决冲突 -> 重新commit -> push
Git 常见问题 冲突原因分析及解决方案的更多相关文章
- SQL查询速度慢的原因分析和解决方案
SQL查询速度慢的原因分析和解决方案 查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建 ...
- hive on spark:return code 30041 Failed to create Spark client for Spark session原因分析及解决方案探寻
最近在Hive中使用Spark引擎进行执行时(set hive.execution.engine=spark),经常遇到return code 30041的报错,为了深入探究其原因,阅读了官方issu ...
- Oracle包被锁定的原因分析及解决方案
http://blog.csdn.net/jojo52013145/article/details/7470812 在数据库的开发过程中,经常碰到包.存储过程.函数无法编译或编译时会导致PL/SQL ...
- CMMI5级——原因分析及解决方案(Causal Analysis and Resolution)
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u010825142/article/details/15338085 聪明的人在出现问题的时候,除了 ...
- IP访问频率限制不能用数组循环插入多个限制条件原因分析及解决方案
14.IP频率限制不能用数组循环插入多个限制条件原因分析及解决方案: define("RATE_LIMITING_ARR", array('3' => 3, '6' => ...
- 在Android library中不能使用switch-case语句访问资源ID的原因分析及解决方案
转自:http://www.jianshu.com/p/89687f618837 原因分析 当我们在Android依赖库中使用switch-case语句访问资源ID时会报如下图所示的错误,报的错误 ...
- Weblogic环境下hibernate、antlr类加载冲突问题分析及解决方案
公司应用项目在客户部署时经常遇到此类问题,为避免实施部署时增加配置量,花了点时间找到了此问题的终极解决办法(方案二.修改org.hibernate.hql.ast.HqlLexer的源代码).在此进行 ...
- Beforeunload打点丢失原因分析及解决方案
淘宝的鱼相在 2012 年 8 月份发表了一篇文章,里面讲述了他们通过一个月的数据采集试验,得到的结果是:如果在浏览器的本页面刷新之前发送打点请求,各浏览器都有不同程度的点击丢失情况,具体点击丢失率统 ...
- window.open浏览器弹出新窗口被拦截—原因分析和解决方案
最近在做项目的时候碰到了使用window.open被浏览器拦截的情况,在本机实验没问题,到了服务器就被拦截了,火狐有拦截提示,360浏览器拦截提示都没有,虽然在自己的环境可以对页面进行放行,但是对用户 ...
随机推荐
- 6. concat_ws用法
select CONCAT_WS('-', e.audit_one_name, e.audit_second_name) from t_audit_item_name e where e.id= ...
- SpringMVC框架——数据绑定
Spring MVC 数据绑定 使用POJO绑定参数 entity package com.sunjian.entity; /** * @author sunjian * @date 2020/3/1 ...
- SpringBoot2 + Druid + Mybatis 多数据源动态配置
在大数据高并发的应用场景下,为了更快的响应用户请求,读写分离是比较常见的应对方案.读写分离会使用多数据源的使用.下面记录如何搭建SpringBoot2 + Druid + Mybatis 多数据源配 ...
- 网维大师重建B盘方法
[操作步骤]操作前先熟悉步骤,以免手忙脚乱.请在人少的时候操作. 1.打开网维大师安装目录,进入barserver\找到barserver.ini打开,找到[PlatformUpdate]字段下的up ...
- SQL 分组内求最大N个或最小N个
题目描述 表 Employee +----+-------+--------+--------------+ | Id | Name | Salary | DepartmentId | +----+- ...
- Android LinearLayout线性布局详解
为了更好地管理Android应用的用户界面里的各组件,Android提供了布局管理器.通过使用布局管理器,Android应用图形用户界面具有良好的平台无关性.推荐使用布局管理器来管理组件的分布.大小, ...
- TensorFlow系列专题(七):一文综述RNN循环神经网络
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习.深度学习的知识! 目录: 前言 RNN知识结构 简单循环神经网络 RNN的基本结构 RNN的运算过程 ...
- arcgis10.4.X的oracle数据库要求
受支持的数据库版本:(标准版/标准独立版/企业版) Oracle 11g R2(64 位)11.2.0.4 Oracle 12c R1(64 位)12.1.0.2 受支持的操作系统: 数据库 支持的操 ...
- DNS 域名解析
DNS域名解析 整个过程大体描述如下,其中前两个步骤是在本机完成的,后8个步骤涉及到真正的域名解析服务器:1.浏览器会检查缓存中有没有这个域名对应的解析过的IP地址,如果缓存中有,这个解析过程就结束. ...
- Vue.js系列(一):Vue项目创建详解
引言 Vue.js作为目前最热门最具前景的前端框架之一,其提供了一种帮助我们快速构建并开发前端项目的新的思维模式.本文旨在帮助大家认识Vue.js,并详细介绍使用vue-cli脚手架工具快速的构建Vu ...