Python爬虫的简单入门(一)
Python爬虫的简单入门(一)
简介
这一系列教学是基于Python的爬虫教学在此之前请确保你的电脑已经成功安装了Python(本教程使用的是Python3).爬虫想要学的精通是有点难度的,尤其是遇到反爬,多线程,分布式.我的博客适用于对Python爬虫的入门.会讲一些静态动态网页的爬取,及一些简单的验证码的处理.到时候通过爬虫爬取QQ音乐还是很轻松的.
爬虫一般分为三个部分爬取网页,解析网页,保存数据 此节主要讲通过requests获取网页代码
第三方库的安装
- requests库的安装
- 安装方法打开cmd输入
pip install requests回车
看一段简单的代码
import requests # 导入requests库
url = "https://www.baidu.com" # 目标网址
r = requests.get(url) # 调用requests的get方法发起get请求
print(r.status_code) # 打印状态码
print(r.text) # 打印获取到的网页代码
运行结果
200
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>ç¾åº¦ä¸ä¸ï¼ä½ å°±ç¥é</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=ç¾åº¦ä¸ä¸ class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ°é»</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>å°å¾</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>è§é¢</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>ç»å½</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">ç»å½</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">æ´å¤äº§å</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å
³äºç¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使ç¨ç¾åº¦åå¿
读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æè§åé¦</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
这是我们获得的内容,可以看到第一行输出的是200,这就表明成功响应,更多关于HTTP状态码的知识请访问这里
但是这里还有两点奇怪的地方1.网页里面有奇怪的乱码 2.通过浏览器右键查看源代码可知百度的首页代码远比这个多
这也是爬虫十分常见的问题
先来解决第一个问题
乱码是因为编码不同引起的
我们可以打印一下网页的编码print(r.encoding)结果为ISO-8859-1,另外我们可以观察上面的网页源代码,发现里面有一句charset=utf-8.说明这个网页的编码为utf-8,两个编码不同当然会乱码.只要加上一句r.encoding = 'utf-8'就可以了,再次打印可得
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
这下就清楚多了.
但其实requests自带一个apparent_encoding的属性它可以理解为网页里的真编码.打印试试看print(r.apparent_encoding),得到结果utf-8和我们找到的结果一样.这样一来为了避免这种编码问题我们可以直接在代码中加上一句r.encoding = r.apparent_encoding
解决第二个问题
再此之前先讲讲浏览器的开发者工具
打开开发者工具
- 在浏览器的空白处右键选择检查
- 按一下键盘的
F12键
找到浏览器的标识信息
先点击network(火狐浏览器为网络)

我们发现底下什么也没有,接下来刷新网页
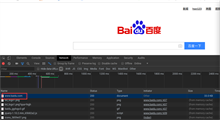
会出来很多的网址,这里我们找到百度的主页点击它,再选择右边的headers信息找到request headers下的User-Agent信息,这就是浏览器的标识信息

网站就是通过检测你的标识信息来判断你是正常的人访问还是程序访问,我们之前就是被检测到不是正常访问,所以返回了一个错误的网页信息
接下来我们要做的就是修改我们的头信息,让代码伪装成浏览器,具体操作如下
import requests # 导入requests库
url = "https://www.baidu.com" # 目标网址
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
} # 这里是复制刚刚网页上找到的浏览器标识信息,将他装换成字典,实际上整个request headers里的内容都可以复制进去,但是这里只用User-Agent就足够了
r = requests.get(url,headers=headers) # 调用requests的get方法发起get请求,添加headers参数(第一个headers为参数名称,第二个requests是上面定义的字典名称)
r.encoding = r.apparent_encoding # 矫正编码
print(r.text) # 打印获取到的网页代码
结果如下(下面内容很长,不予展示,有兴趣的可以去百度首页查看源代码)
至此就可以爬取大部分的网页源代码了,下一次介绍如何从源代码里提取我们想要的信息
给出静态网页爬取的代码框架(只做参考)
import requests
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
r = requests.get(url,headers=headers)
if r.status_code == 200:
r.encoding = r.apparent_encoding
print(r.text)
else:
print("访问失败")
其他
关于requests库的其他方法和参数常用的有post()方法,data参数后期会慢慢介绍
Python爬虫的简单入门(一)的更多相关文章
- 这个Python爬虫的简单入门及实用的实例,你会吗?
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:HOT_and_COOl 利用爬虫可以进行数据挖掘,比如可以爬取别人的网 ...
- 初学Python之爬虫的简单入门
初学Python之爬虫的简单入门 一.什么是爬虫? 1.简单介绍爬虫 爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等. 网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的 ...
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- Python爬虫三年没入门,传授一下绝世神功,经理唏嘘不已!
长期枯燥的生活,敲代码的时间三天两头往吸烟室跑,被项目经理抓去训话. "入门"是学习Python最重要的阶段,虽然这个过程也许会非常缓慢.当你心里有一个目标时,那么你学习起来就不会 ...
- python简介与简单入门
1.计算机基础 计算机组成: 输入输出设备内. 存储器 .cpu .电源 .显卡 中央处理器(cpu) 处理各种数据 相当于人的大脑 内存 存储数据 相当于临时记忆 硬盘 存储数据 相当于人的永久记忆 ...
- Python爬虫基础知识入门一
一.什么是爬虫,爬虫能做什么 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.比如它在抓取一个网 ...
- python爬虫基本原理及入门
爬虫:请求目标网站并获得数据的程序 爬虫的基本步骤: 使用python自带的urllib库请求百度: import urllib.request response = urllib.request.u ...
- Python Requests库简单入门
我对Python网络爬虫的学习主要是基于中国慕课网上嵩天老师的讲授,写博客的目的是为了更好触类旁通,并且作为学习笔记之后复习回顾. 1.引言 requests 库是一个简洁且简单的处理HTTP请求的第 ...
随机推荐
- 安卓:从assets目录下复制文件到指定目录
有些时候我们直接将某些资源文件内置到apk中,便于直接使用. 1.首先将文件放置在项目/app/src/main/assets目录中 2.功能代码: public void copyFile(Stri ...
- [转]Android 如何建立AIDL
建立AIDL服务要比建立普通的服务复杂一些,具体步骤如下: (1)在Eclipse Android工程的Java包目录中建立一个扩展名为aidl的文件.该文件的语法类似于Java代码,但会稍有不同.详 ...
- java随机函数用法Random
原文地址:http://blog.csdn.net/wpjava/article/details/6004492 import java.util.Random; public class Ran ...
- 【转】Spark Streaming 实时计算在甜橙金融监控系统中的应用及优化
系统架构介绍 整个实时监控系统的架构是先由 Flume 收集服务器产生的日志 Log 和前端埋点数据, 然后实时把这些信息发送到 Kafka 分布式发布订阅消息系统,接着由 Spark Streami ...
- HDU 4960 Handling the past 2014 多校9 线段树
首先确定的基本思想是按时间离散化后来建线段树,对于每个操作插入到相应的时间点上 但是难就难在那个pop操作,我之前对pop操作的处理是找到离他最近的那个点删掉,但是这样对于后面的peak操作,如果时间 ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 字体图标(Glyphicons):glyphicon glyphicon-pause
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- hihocoder 1241:Best Route in a Grid
#1241 : Best Route in a Grid 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 给定一个N行N列的非负整数方阵,从左上角(1,1)出发,只能向下 ...
- 【LeetCode 】验证回文串
[问题]给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写.说明:本题中,我们将空字符串定义为有效的回文串. 示例 : 输入: "A man, a plan, a ...
- 使用Kickstart+pxe自动化安装部署无人值守的linux服务器
Kickstart+pxe Kickstart无人职守安装RHEL5过程分享(详细图解版) 启动应用有:httpd.dhcpd.named.xinetd 无人职守自动批量安装linux系统超详细 参考 ...
- 五十二、SAP中的可编辑表格LVC
一.之前我们写的表格如下,都是通过WRITE输出,不支持同步编辑等操作,给人感觉非常之LOW 二.在SAP中还存在另外一种可编辑的表格,叫LVC表格,效果如下, 三.此可标记表格是座位SAP内置模块来 ...