8、Flink Table API & Flink Sql API
一、概述
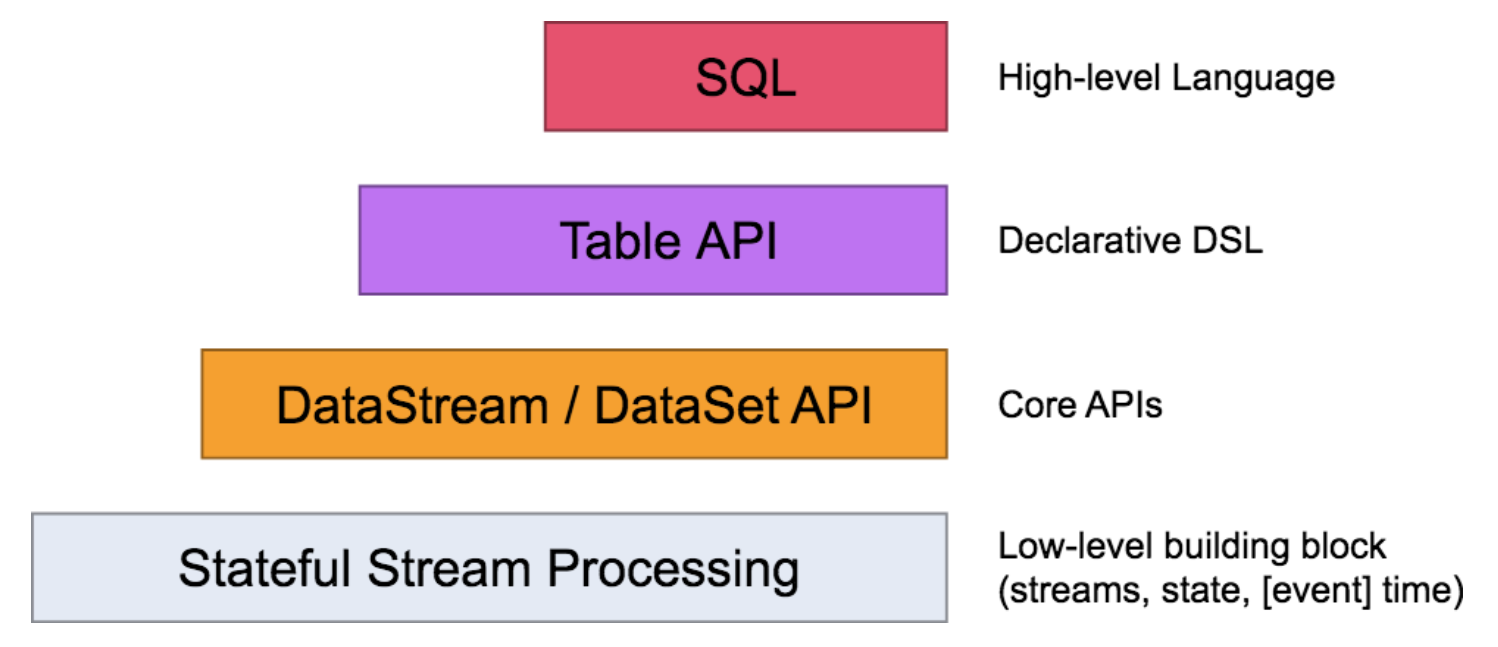
- 上图是flink的分层模型,Table API 和 SQL 处于最顶端,是 Flink 提供的高级 API 操作。Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
- Flink 在编程模型上提供了 DataStream 和 DataSet 两套 API,并没有做到事实上的批流统一,因为用户和开发者还是开发了两套代码。正是因为 Flink Table & SQL 的加入,可以说 Flink 在某种程度上做到了事实上的批流一体。
原理
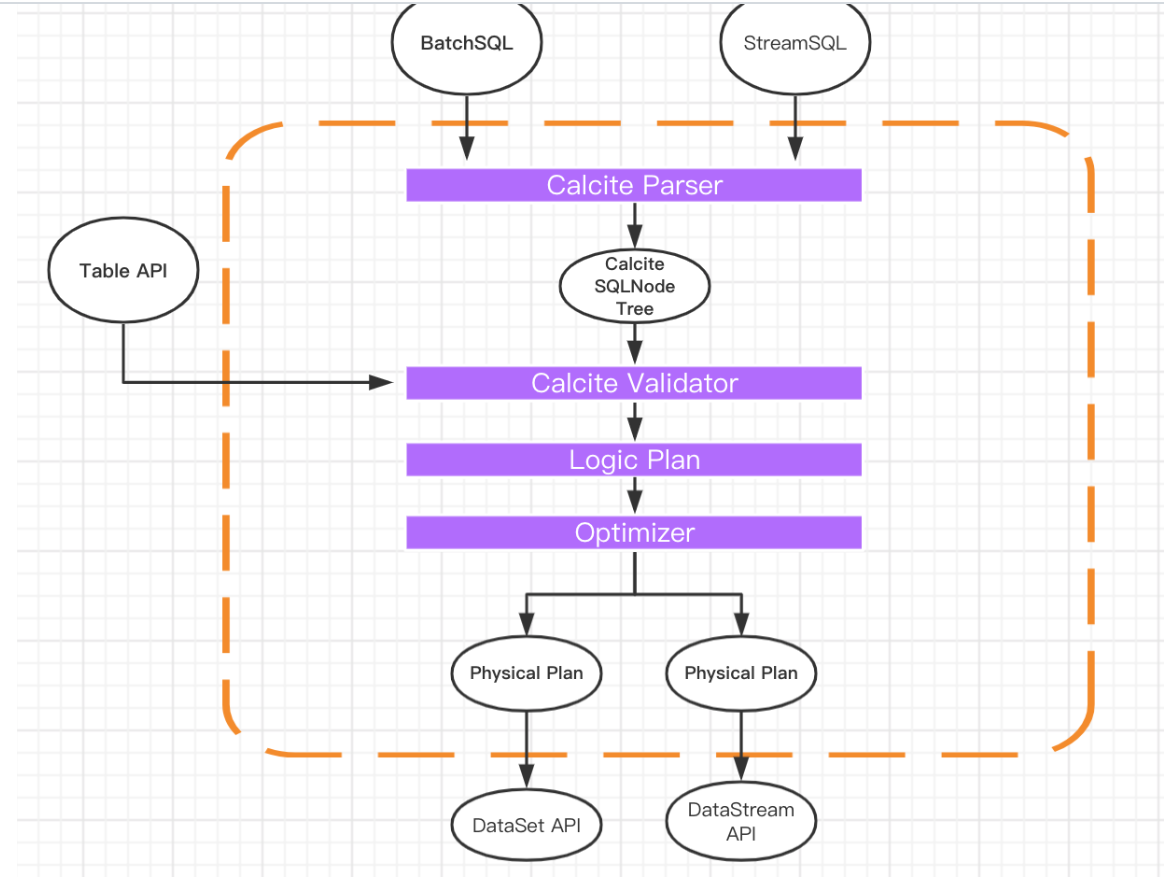
- Flink 底层对 SQL 的解析,优化,执行用到了 Apache Calcite。
- 下图是一张经典的 Flink Table & SQL 实现原理图,可以看到 Calcite 在整个架构中处于绝对核心地位。
二、Flink Table & SQL 算子和内置函数
Table API 操作

以 Table -> GroupedTable -> Table 为例:
一个Table 经过 groupBy 后得到 GroupedTable,GroupedTable经过select后又得到Table。
Columns operators

比如有一张100列的表去除一列,可以选择 DropColumns
Columns Function

Flink sql API操作
Flink SQL 和传统的 SQL 一样,支持了包含查询、连接、聚合等场景,另外还支持了包括窗口、排序等场景:
query:
values
| {
select
| selectWithoutFrom
| query UNION [ ALL ] query
| query EXCEPT query
| query INTERSECT query
}
[ ORDER BY orderItem [, orderItem ]* ]
[ LIMIT { count | ALL } ]
[ OFFSET start { ROW | ROWS } ]
[ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY] orderItem:
expression [ ASC | DESC ] select:
SELECT [ ALL | DISTINCT ]
{ * | projectItem [, projectItem ]* }
FROM tableExpression
[ WHERE booleanExpression ]
[ GROUP BY { groupItem [, groupItem ]* } ]
[ HAVING booleanExpression ]
[ WINDOW windowName AS windowSpec [, windowName AS windowSpec ]* ] selectWithoutFrom:
SELECT [ ALL | DISTINCT ]
{ * | projectItem [, projectItem ]* } projectItem:
expression [ [ AS ] columnAlias ]
| tableAlias . * tableExpression:
tableReference [, tableReference ]*
| tableExpression [ NATURAL ] [ LEFT | RIGHT | FULL ] JOIN tableExpression [ joinCondition ] joinCondition:
ON booleanExpression
| USING '(' column [, column ]* ')' tableReference:
tablePrimary
[ matchRecognize ]
[ [ AS ] alias [ '(' columnAlias [, columnAlias ]* ')' ] ] tablePrimary:
[ TABLE ] [ [ catalogName . ] schemaName . ] tableName
| LATERAL TABLE '(' functionName '(' expression [, expression ]* ')' ')'
| UNNEST '(' expression ')' values:
VALUES expression [, expression ]* groupItem:
expression
| '(' ')'
| '(' expression [, expression ]* ')'
| CUBE '(' expression [, expression ]* ')'
| ROLLUP '(' expression [, expression ]* ')'
| GROUPING SETS '(' groupItem [, groupItem ]* ')' windowRef:
windowName
| windowSpec windowSpec:
[ windowName ]
'('
[ ORDER BY orderItem [, orderItem ]* ]
[ PARTITION BY expression [, expression ]* ]
[
RANGE numericOrIntervalExpression {PRECEDING}
| ROWS numericExpression {PRECEDING}
]
')'
...
主要来看一下flink sql的Windows操作
根据窗口数据划分的不同,目前 Apache Flink 有如下 3 种:
- 滚动窗口,窗口数据有固定的大小,窗口中的数据不会叠加;
- 滑动窗口,窗口数据有固定大小,并且有生成间隔;
- 会话窗口,窗口数据没有固定的大小,根据用户传入的参数进行划分,窗口数据无叠加;
滚动窗口
- 滚动窗口的特点是:有固定大小、窗口中的数据不会重叠,如下图所示

语法:
SELECT
[gk],
[TUMBLE_START(timeCol, size)],
[TUMBLE_END(timeCol, size)],
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], TUMBLE(timeCol, size)
比如我们计算每个用户每天的订单量:
SELECT user, TUMBLE_START(timeLine, INTERVAL '' DAY) as winStart, SUM(amount) FROM Orders GROUP BY TUMBLE(timeLine, INTERVAL '' DAY), user;
其中,TUMBLE_START 和 TUMBLE_END 代表窗口的开始时间和窗口的结束时间,TUMBLE (timeLine, INTERVAL '1' DAY) 中的 timeLine 代表时间字段所在的列,INTERVAL '1' DAY 表示时间间隔为一天。
滑动窗口
滑动窗口有固定的大小,与滚动窗口不同的是滑动窗口可以通过 slide 参数控制滑动窗口的创建频率。需要注意的是,多个滑动窗口可能会发生数据重叠,具体语义如下:
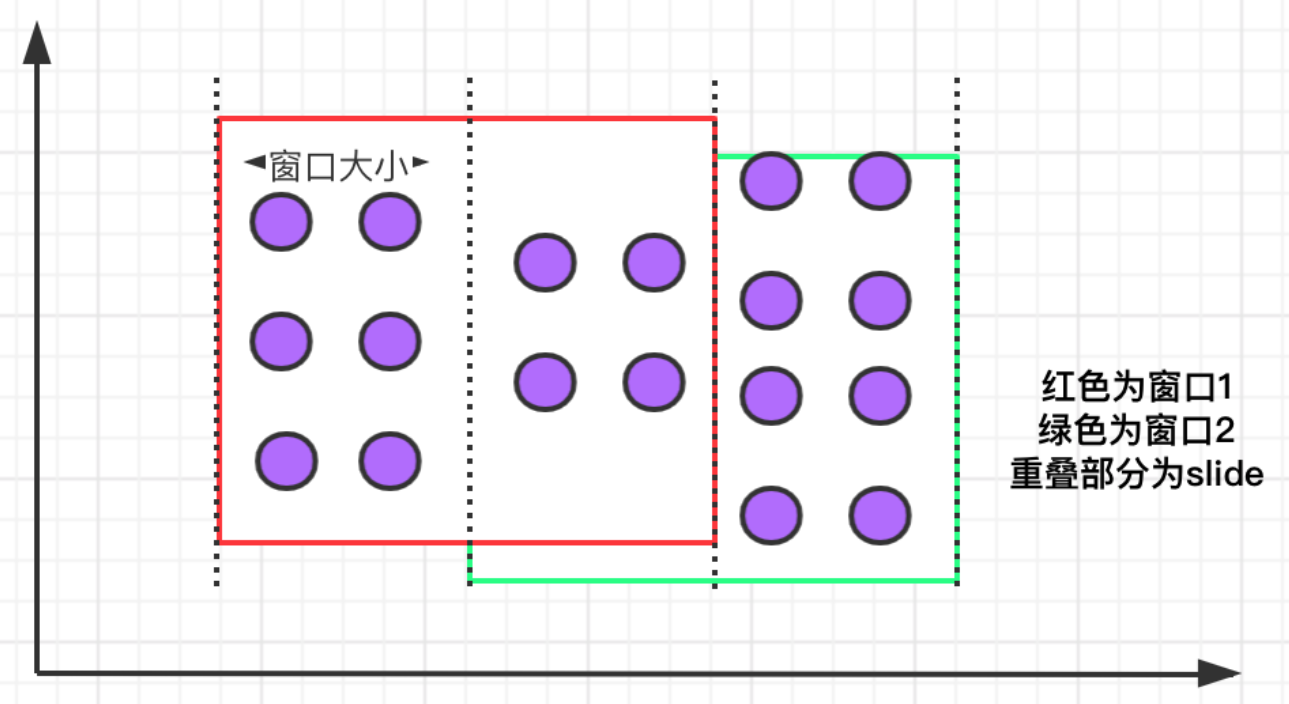
滑动窗口的语法与滚动窗口相比,只多了一个 slide 参数:
SELECT
[gk],
[HOP_START(timeCol, slide, size)] ,
[HOP_END(timeCol, slide, size)],
agg1(col1),
...
aggN(colN)
FROM Tab1
GROUP BY [gk], HOP(timeCol, slide, size)
例如,我们要每间隔一小时计算一次过去 24 小时内每个商品的销量:
SELECT product, SUM(amount) FROM Orders GROUP BY HOP(rowtime, INTERVAL '' HOUR, INTERVAL '' DAY), product
上述案例中的 INTERVAL '1' HOUR 代表滑动窗口生成的时间间隔。
会话窗口
- 会话窗口定义了一个非活动时间,假如在指定的时间间隔内没有出现事件或消息,则会话窗口关闭。
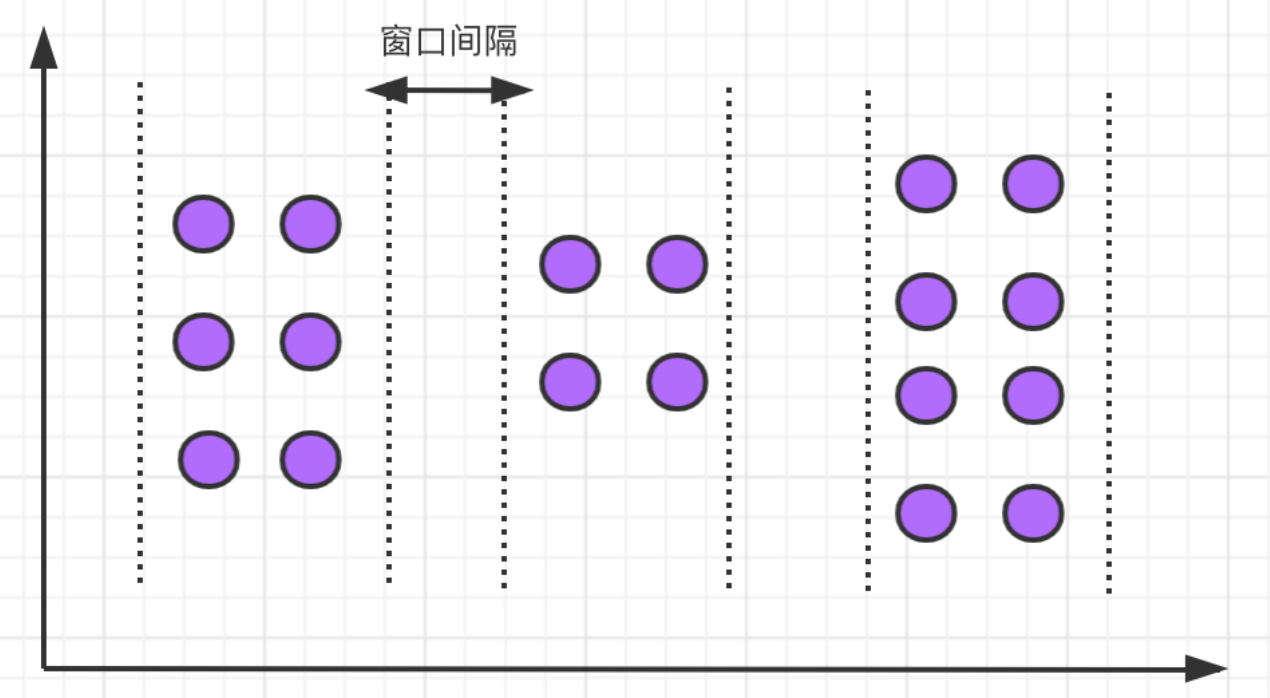
语法如下:
SELECT
[gk],
SESSION_START(timeCol, gap) AS winStart,
SESSION_END(timeCol, gap) AS winEnd,
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], SESSION(timeCol, gap)
举例,我们需要计算每个用户过去 1 小时内的订单量:
SELECT user, SESSION_START(rowtime, INTERVAL '' HOUR) AS sStart, SESSION_ROWTIME(rowtime, INTERVAL '' HOUR) AS sEnd, SUM(amount) FROM Orders GROUP BY SESSION(rowtime, INTERVAL '' HOUR), user
内置函数
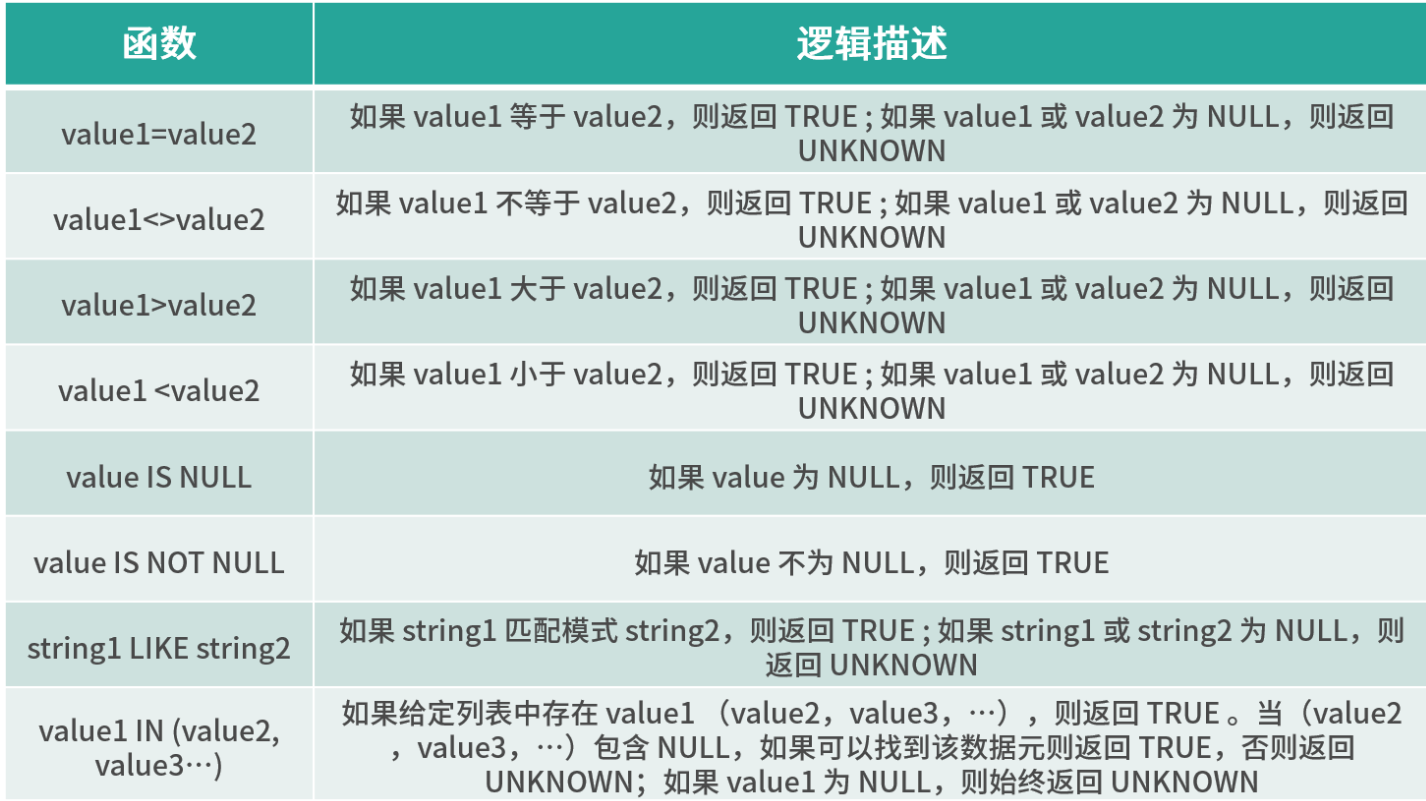
Flink 中还有大量的内置函数,我们可以直接使用,将内置函数分类如下:
- 比较函数
逻辑函数
- 算数函数
- 字符串处理函数
- 时间函数




三、demo
import org.apache.flink.api.scala._
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala.{DataStream, SplitStream, StreamExecutionEnvironment}
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.table.api.{StreamQueryConfig, Table} import scala.collection.mutable.{ArrayBuffer, ListBuffer}
import scala.util.Random /**
* @author xiandongxie
*/ // 商品类
case class Item(id: Int, name: String) // 自定义实时数据源
class MyStreamSourceFunction extends SourceFunction[Item] { var isCancel: Boolean = false override def cancel(): Unit = {
isCancel = true
} override def run(ctx: SourceFunction.SourceContext[Item]): Unit = {
while (!isCancel) {
val item: Item = getItem()
ctx.collect(item)
Thread.sleep(1000)
}
} def getItem(): Item = {
val random: Random = new Random()
val id: Int = random.nextInt(100)
val buffer: ArrayBuffer[String] = new ArrayBuffer[String]()
buffer.append("HAT")
buffer.append("TIE")
buffer.append("SHOE")
new Item(id, buffer(random.nextInt(3))) } } /**
* 我们把实时的商品数据流进行分流,分成 even 和 odd 两个流进行 JOIN,条件是名称相同
* 最后,把两个流的 JOIN 结果输出
*/
object StreamJoinDemo {
def main(args: Array[String]): Unit = {
val logPath: String = "/tmp/logs/flink_log" // 生成配置对象
var conf: Configuration = new Configuration()
// 开启flink web UI
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
// 配置web UI的日志文件,否则打印日志到控制台
conf.setString("web.log.path", logPath)
// 配置taskManager的日志文件,否则打印到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, logPath)
// 获取local运行环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
// val build: EnvironmentSettings = EnvironmentSettings.newInstance.useBlinkPlanner.inStreamingMode.build
// val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(streamEnv, build)
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(streamEnv) val source: DataStream[Item] = streamEnv.addSource(new MyStreamSourceFunction)
val split: SplitStream[Item] = source.split(f => {
val out: ListBuffer[String] = new ListBuffer[String]
val id: Int = f.id
if (id % 2 == 0) {
out.append("even")
} else {
out.append("odd")
}
out
}) val evenData: DataStream[Item] = split.select("even")
val oddData: DataStream[Item] = split.select("odd") tableEnv.createTemporaryView("event_table", evenData)
tableEnv.createTemporaryView("odd_table", oddData) val queryTable: Table = tableEnv.sqlQuery("select a.id,a.name,b.id,b.name from event_table as a join odd_table as b on a.name = b.name")
queryTable.printSchema()
tableEnv.toRetractStream[(Int, String, Int, String)](queryTable, new StreamQueryConfig())
.print() streamEnv.execute()
}
}
结果:
8、Flink Table API & Flink Sql API的更多相关文章
- 使用flink Table &Sql api来构建批量和流式应用(1)Table的基本概念
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- 使用flink Table &Sql api来构建批量和流式应用(3)Flink Sql 使用
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- Flink Table Api & SQL 翻译目录
Flink 官网 Table Api & SQL 相关文档的翻译终于完成,这里整理一个安装官网目录顺序一样的目录 [翻译]Flink Table Api & SQL —— Overv ...
- 【翻译】Flink Table Api & SQL —— Overview
本文翻译自官网:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/ Flink Table Api & ...
- 【翻译】Flink Table Api & SQL —— 概念与通用API
本文翻译自官网:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/common.html Flink Tabl ...
- 【翻译】Flink Table Api & SQL —— 数据类型
本文翻译自官网:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/types.html Flink Table ...
- 【翻译】Flink Table Api & SQL —Streaming 概念 ——动态表
本文翻译自官网:Flink Table Api & SQL 动态表 https://ci.apache.org/projects/flink/flink-docs-release-1.9/de ...
- 【翻译】Flink Table Api & SQL —Streaming 概念 ——在持续查询中 Join
本文翻译自官网 : Joins in Continuous Queries https://ci.apache.org/projects/flink/flink-docs-release-1.9 ...
- 【翻译】Flink Table Api & SQL —Streaming 概念 —— 表中的模式匹配 Beta版
本文翻译自官网:Detecting Patterns in Tables Beta https://ci.apache.org/projects/flink/flink-docs-release-1 ...
随机推荐
- HIT软件构造课程3.4总结(Object-Oriented Programming )
上一节学习了ADT理论,这一节学习ADT的具体实现:OOP 1.基本概念:对象,类,属性,方法 对象 对象是状态和行为的捆绑.java中,状态=成员变量,行为=方法. 类 每个对象都定义了一个类,类定 ...
- 8.MSFvenom
Meterpreter 01 Meterpreter API调用 Meterpreter提供了多种APl调用,在编写自己的脚本时可以使用这些API来提供额外功能或定制功能. 关于ruby的更多信息,请 ...
- Unity 游戏框架搭建 2019 (二十五) 类的第一个作用 与 Obselete 属性
在上一篇我们整理到了第七个示例,我们今天再接着往下整理.我们来看第八个示例: #if UNITY_EDITOR using UnityEditor; #endif using UnityEngine; ...
- PTA数据结构与算法题目集(中文) 7-10
PTA数据结构与算法题目集(中文) 7-10 7-10 公路村村通 (30 分) 现有村落间道路的统计数据表中,列出了有可能建设成标准公路的若干条道路的成本,求使每个村落都有公路连通所需要的最低 ...
- CentOS 6.5系统实现NFS文件共享
一台Linux server ip 192.168.1.254,一台Linux client ip 192.168.1.100操作系统:CentOS 6.5需求描述:1:将/root 共享给192.1 ...
- MariaDB使用数据库查询《三》
MariaDB使用数据库查询 案例5:使用数据库查询 5.1 问题 本例要求配 ...
- Jmeter 压力测试笔记(3)--脚本调试/签名/cookie/提升吞吐量/降低异常率/提升单机并发性能
import XXXsign.Openapi2sign;---导入jar包中的签名方法 String str1 = "12121"; ---需要被签名的字段:向开发了解需要哪些哪些 ...
- 多转一ETH(ERC20代币汇集)
1.下载表格模板 2.导入小号地址 NO1.地址整理 NO2.地址导入 NO3.导入完成 3.查询地址余额1.下图是汇集ETH的操作图片 2.下图是汇集ERC20代币的操作图片 注 ...
- 28.5 Integer-- int的包装类
* 由于基本数据类型只能做一些简单的操作和运算,所以Java为我们封装了基本数据类型,为每种基本数据类型提供了包装类 * 包装类就是封装了基本数据类型的类,为我们提供了更多复杂的方法和一些变量 * * ...
- win10+ubuntu双系统修复ubuntu启动引导
因为windows是不能引导linux的,而每次win10升级或恢复都会将linux的启动引导覆盖掉,导致无法进入linux, 所以一直就禁止了win10更新.这几天win10出了点小毛病,所以就狠下 ...