深度学习之文本分类模型-前馈神经网络(Feed-Forward Neural Networks)
DAN(Deep Average Network)
MLP(Multi-Layer Perceptrons)叫做多层感知机,即由多层网络简单堆叠而成,进而我们可以在输出层加入softmax,或者将输入层作为特征进行提取后,输入到SVM,逻辑回归,朴素贝叶斯等传统分类器进行分类预测。其中最具代表的是DAN,其基本结构如下图所示:
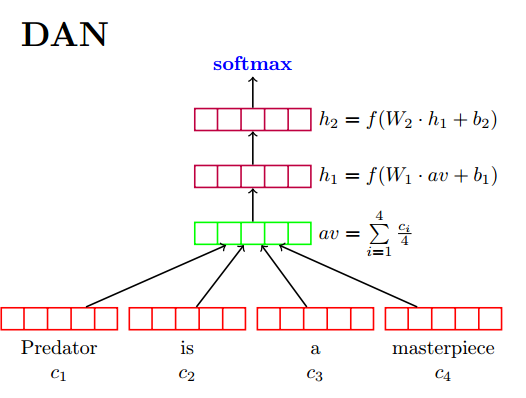
在输入层,我们对每一篇文章中的词汇向量进行相加求平均。在中间隐藏层,我们建立了多层的神经网络单元,进行深层次的特征提取,对每一层,我们都有相应的激活函数,其中激活函数可以按照我们的需求自己进行选择。在输出层,我们加入了softmax层,对输出层的个数即为分类标签的个数,我们要做的事情就是最大化当前文章标签所对应的神经元节点,进而构造损失函数,进行参数更新。
在预测阶段,我们将文章的单词进行输入,最终根据输出层softmax最大的节点,得到我们的预测标签。对于多分类,我们可以自己限定阈值和多分类的个数,取最大的topK个标签。
模型使用中的trick:在作者的论文中[1],加了了dropout,将输入层随机的进行丢弃,增加了模型的健壮性。
那这种模型有什么优缺点吗?我们来总结一下:
优点:
- 模型简单,训练速度快。
- 模型通过增加隐藏层节点的个数,可以增加模型的复杂度,进而提升模型的准确率。
缺点:
- 由于输入层使用的加和平均作为,并没有考虑单词之间的顺序信息。
Fasttext
fasttext是facebook在2016年推出的一款获取词向量和快速分类的一个工具[2],其基本思想是建立在Google提出的Word2vector的基础上,并对其进行些许的改进,打造成了一种既可以获取词向量又可以进行文本分类的工具,其中,fasttext根据Piotr Bojanowski[2]等人的文章,加入了n-gram模型,增加了单词的顺序信息,从而增加了准确率。论文实验结果表明,在情感分析和tag标注上都取得了不错的效果。
fasttext文本分类
如果想了解fasttext的基本原理,首先要对word2vec有一定的了解,可以参考词向量模型word2vec详解。
fasttext用于文本分类,其基本模型和word2vec类似,无非是将叶子节点改成类别标签。我们设文章集合为\(D\),\(d_{i} \in D\),表示第\(i\)篇文章,\(w_{ij}\)表示第\(i\)篇文章中的第\(j\)个单词,我们假设词汇集合为\(V\),类别标签为\(label_i\),表示第\(i\)篇文章的标签是\(label_i\),对于第\(i\)篇文章的第\(j\)个单词\(w_{ij}\)来说,我们抽取其上下文的单词\(context(w_{ij})\),我们可以构建模型
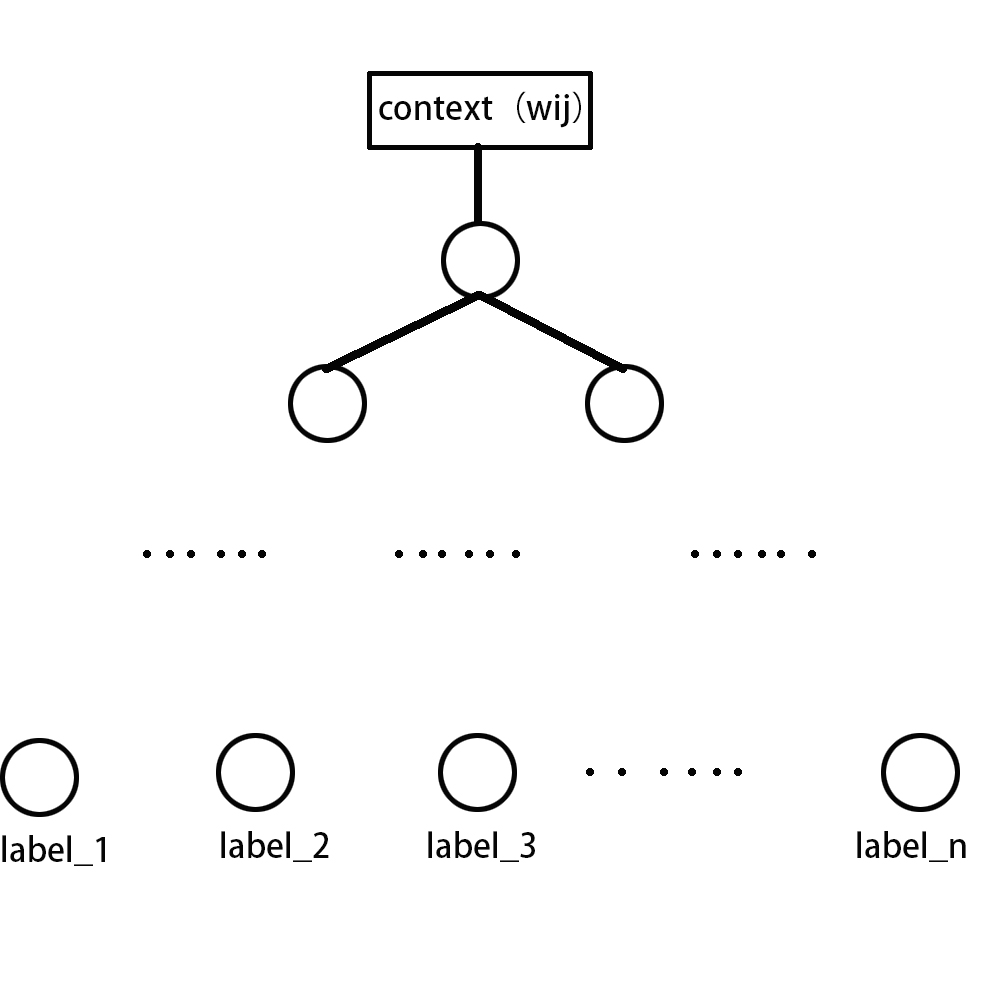
输入层到隐藏层,对于CBOW模型来说,输入的就是当前词的上下文单词,我们这里可以设定一个窗口的阈值,比如是1,则我们输入的当前单词的前后两个单词,从输入层到隐藏层,我们会对这两个单词的词向量进行相加,得到vec(context(wij)),得到隐藏层的节点。从隐藏层到叶子结点,我们可以设置一个全连接层, 在输出层,我们可以进行一个softmax,最终最大化当前文章的label,进而构造损失函数,进行求解。
在隐藏层到输出层中,我们可以用哈夫曼树来代替全连接结构,进而加快训练的速度。个人认为,其实对于量级比较少的label,构造哈夫曼树的作用不大,但是对于类别标签较多的样本来说,构造哈夫曼树作用还是比较大的
以上便是fasttext用于文本分类的整体流程,笔者实验了在大数据集上的文本分类速度和效果,整体上还是不错的,可以作为文本分类的一个baseline。
fasttext的n-gram模型
由于输入的单词仅仅做了一个简单的加和,并没有考虑单词之间的顺序特征,举个例子,"我 爱 你"和"你 爱 我"经过分词之后,可以看到如果根据词袋模型,两者的输入是完全相同的,但是如果加入n-gram信息的话,就变成了"我 爱 你 我爱 爱你"和"你 爱 我 你爱 爱我"这样输入的特征就不一样了,区分了两者。
所以根据[3]的思想,我们可以在分类或者是向量学习的阶段,将n-gram特征作为输入的信息,增加更多的特征,使得学习的更充分。
那么综上,我们来总结一下fasttext的优缺点
优点:
- fasttext在构建使用的哈夫曼树,极大增加了训练和预测的速度。
- 加入了n-gram模型,考虑了单词之间的顺序问题,有效的提高了准确率。
缺点:
- 虽然fasttext加入了n-gram模型以增加单词之间的顺序信息,但是总体来说其受限于context的长度,对于大于context窗口大小的单词,无法捕捉其顺序信息。
Doc2vec
Doc2vec是一种获取文章向量的一种方法,为什么要放在文本分类的里面呢,是因为当我们获取文章向量之后,我们就可以将文章向量输入到SVM,逻辑回归进行分类预测了,所以,本质上doc2vec目的并不是用于分类,而是获取文章向量的上面。
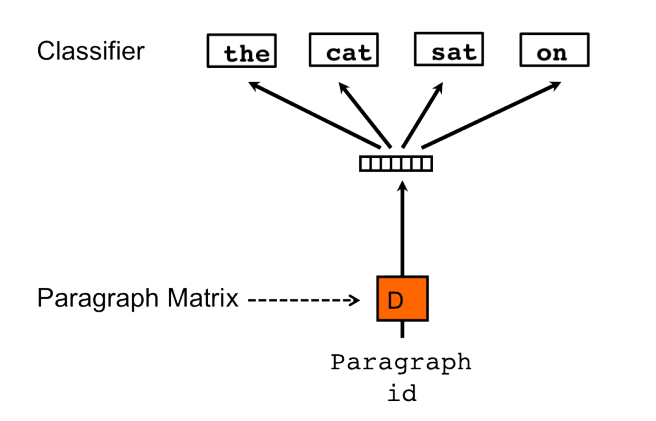
Doc2vec是由Tomas Mikolov[4]提出的一种文章向量获取的方法,其思想是建立在Word2vec的基础上,区别在于将文章的向量D也作为一种可变的参数,加入到训练中,如下图所示,当我们要预测第四个单词"on"的时候,我们将这批词所对应的文章向量D与另外三个单词作为输入,同时进行预测,在输入层,我们可以利用简单的加和或者是取平均值,剩下的基本就和Word2vec一样,从隐藏层到输出层我们可以建立一个神经网络,输出节点的个数即为单词的个数,或者我们用哈夫曼树,加快训练的时间。

同样,作者在论文中还提出了一种skim-gram的doc2vec,如下图所示,即我们用当前文章向量D作为输入。
我们简单总结一下doc2vec的优缺点
优点:
- doc2vec是一种无监督的学习,根据语料可以直接获得文章的向量,省去了手工获取特征的麻烦,而且随着我们语料的增加,模型会更加的精确。
- 文章和词向量一起训练,一定程度上使得文章向量的表达更准确。
缺点:
- 模型结构比较简单,不能捕获单词的order信息。
参考文献
[1]Mohit Iyyer.(2015)Deep Unordered Composition Rivals Syntactic Methods for Text Classification
[2]Armand Joulin.(2016)Bag of Tricks for Efficient Text Classification.
[3]Piotr Bojanowski(2016)Enriching Word Vectors with Subword Information.
[4]Tomas Mikolov(2014)Distributed Representations of Sentences and Documents.
深度学习之文本分类模型-前馈神经网络(Feed-Forward Neural Networks)的更多相关文章
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- 深度学习论文翻译解析(五):Siamese Neural Networks for One-shot Image Recognition
论文标题:Siamese Neural Networks for One-shot Image Recognition 论文作者: Gregory Koch Richard Zemel Rusla ...
- 深度学习的集成方法——Ensemble Methods for Deep Learning Neural Networks
本文主要参考Ensemble Methods for Deep Learning Neural Networks一文. 1. 前言 神经网络具有很高的方差,不易复现出结果,而且模型的结果对初始化参数异 ...
- 吴恩达《深度学习》-课后测验-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-Week 1 - Practical aspects of deep learning(第一周测验 - 深度学习的实践)
Week 1 Quiz - Practical aspects of deep learning(第一周测验 - 深度学习的实践) \1. If you have 10,000,000 example ...
- 基于深度学习的文本分类案例:使用LSTM进行情绪分类
Sentiment classification using LSTM 在这个笔记本中,我们将使用LSTM架构在电影评论数据集上训练一个模型来预测评论的情绪.首先,让我们看看什么是LSTM? LSTM ...
- NLP学习(2)----文本分类模型
实战:https://github.com/jiangxinyang227/NLP-Project 一.简介: 1.传统的文本分类方法:[人工特征工程+浅层分类模型] (1)文本预处理: ①(中文) ...
- 【AI in 美团】深度学习在文本领域的应用
背景 近几年以深度学习技术为核心的人工智能得到广泛的关注,无论是学术界还是工业界,它们都把深度学习作为研究应用的焦点.而深度学习技术突飞猛进的发展离不开海量数据的积累.计算能力的提升和算法模型的改进. ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
随机推荐
- 动态规划-计数dp-Distinct Subsequences II
2020-02-06 17:01:36 问题描述: 问题求解: 非常经典的计数dp问题,思路就是统计以每个字符为结尾的个数,最后求和即可. dp[i] = sum of (dp[j]) 0 <= ...
- 动态规划-Distinct Subsequences
2020-01-03 13:29:04 问题描述: 问题求解: 经典的动态规划题目,一般来说dp题目是递推关系公式难想,但是实际代码量还是比较少的. 有尝试过dfs来做,但是由于时间复杂度是指数级别的 ...
- RDD的Cache、Persist、Checkpoint的区别和StorageLevel存储级别划分
为了增强容错性和高可用,避免上游RDD被重复计算的大量时间开销,Spark RDD设计了包含多种存储级别的缓存和持久化机制,主要有三个概念:Cache.Persist.Checkout. 1.存储级别 ...
- MySQL datetime类型详解
研发反馈问题,数据库中datetime数据类型存储的值末尾会因四舍五入出现不一致数据,影响查询结果,比如:程序中自动获取带毫秒精度的日期'2019-03-05 01:53:55.63',存入数据库后变 ...
- OpenCV-Python 轮廓分层 | 二十五
目标 这次我们学习轮廓的层次,即轮廓中的父子关系. 理论 在前几篇关于轮廓的文章中,我们已经讨论了与OpenCV提供的轮廓相关的几个函数.但是当我们使用cv.findcontour()函数在图像中找到 ...
- 2020 | 可替代Selenium的测试框架Top15
本文首发于 微信公众号: 软测小生 Selenium是一种开源自动测试工具.它可以跨不同的浏览器和平台在Web应用程序上执行功能,回归,负载测试.Slenium是最好的工具之一,但确实有一些缺点. 业 ...
- 各种杂记关于Linux
修改Linux 日期 修改Linux时间
- 在线诊断工具arthas (windows)
介绍: arthas是阿里巴巴开发的一款开源的,Java应用程序排查问题的非常好用的工具 当你遇到以下类似问题而束手无策时 arthas 可以帮助你解决: 这个类从哪个 jar 包加载的?为什么会报各 ...
- C++动态内存new和delete(超详细)
C++动态内存new和delete C++动态内存是C++灵活.炫酷的一种操作.学好它,能让自己编程逼格上一个level. 在学习动态内存之前,我们先要了解C++是怎么划分内存的: 栈:在函数内部声明 ...
- 【docker linux】linux系统镜像转化为docker镜像
概述 使用docker安装linux的同学都知道,你在docker提供的仓库安装linux系统,你就会体验到最精简的.最纯净的linux系统,当然,他会精简到你连ifconfig命令都需要自己配置,恰 ...