<强化学习>基本概念
马尔可夫决策过程MDP,是强化学习的基础。
MDP --- <S,A,P,R,γ>
AGENT
STATE
ENV
REWARD ,由ENV给出。agent处于状态s下,采取action之后离开状态获得一个reward。即f:S x A --->R
所有强化学习问题解决的目标都可以描述成最大化累积奖励。All goals can be described by the maximisation of expected cumulative reward。即我们的目标是最大化Gt 。

ACTION ,离散分布,或者连续分布。
POLICY ,策略。 π :S x A --->[0,1]
|——Deterministic policy: a = π(s)
|——Stochastic policy: π(a|s) = P[At = a|St = s] //一个典型的随机策略 e-greedy policy derived from Q
VALUE ,a prediction of future reward; 形象地说AGENT.VALUE是agent对env的感觉,这样好,那样不好,对这个感到舒服,对那个感到upside
|——state value V(s),表示State好坏的量。V(s)的值代表了State s的好坏。好坏是对于未来reward累积而言的。
| 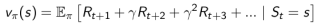
|——state-action value Q(s,a),
| 
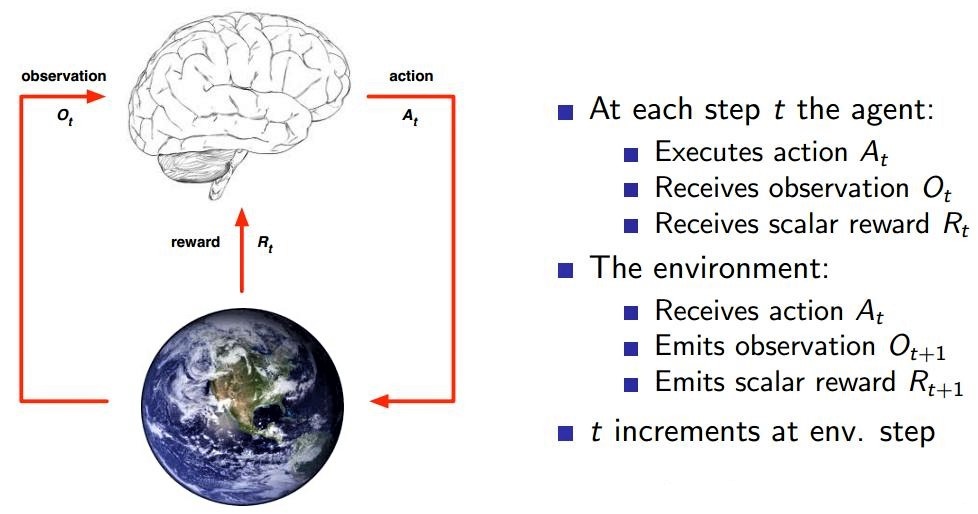
下面是一个”迷宫游戏“的例子:


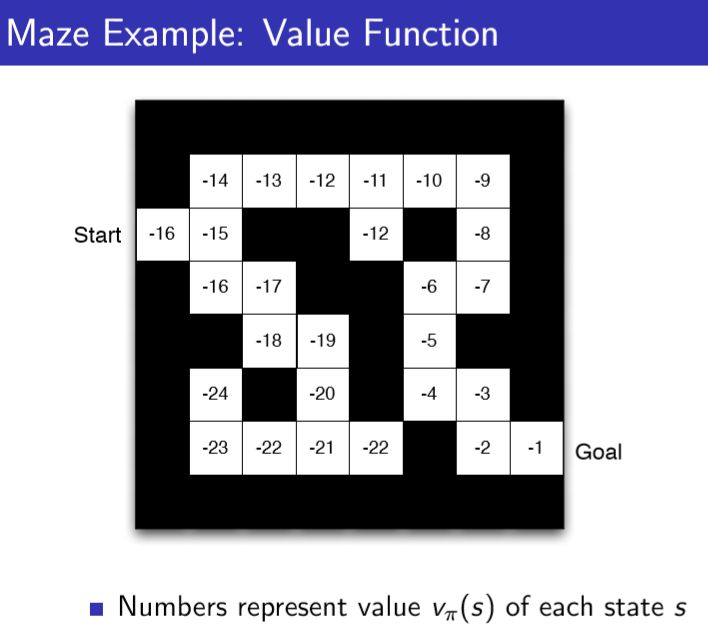
以及算法中基本上用不到的概念Model,我们也给画出来:

History & Observation & State三个概念辩解:
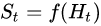
如下图中,红框为History,黑圈为Observation。
至于State,要看f()是如何定义的,St = f(Ht),f()是我们人为定义的。
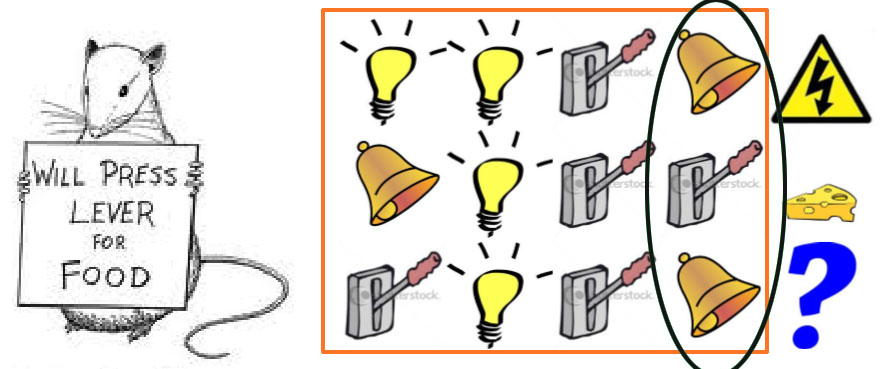
AGENT分为以下三类:

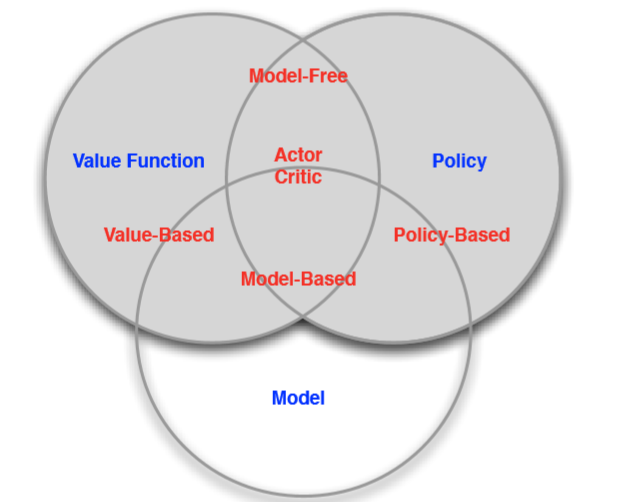
Model free和Model based辩解:
我们进一步把RL算法分为Model free和Model based两类。
Model based算法需要全知env,或者说已知Reward(s,a) for any (s,a)
Model free算法不需要全知env。
<强化学习>基本概念的更多相关文章
- 分布式强化学习基础概念(Distributional RL )
分布式强化学习基础概念(Distributional RL) from: https://mtomassoli.github.io/2017/12/08/distributional_rl/ 1. Q ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...
- 深度强化学习day01初探强化学习
深度强化学习 基本概念 强化学习 强化学习(Reinforcement Learning)是机器学习的一个重要的分支,主要用来解决连续决策的问题.强化学习可以在复杂的.不确定的环境中学习如何实现我们设 ...
- 深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-fu ...
- Deep Learning专栏--强化学习之MDP、Bellman方程(1)
本文主要介绍强化学习的一些基本概念:包括MDP.Bellman方程等, 并且讲述了如何从 MDP 过渡到 Reinforcement Learning. 1. 强化学习基本概念 这里还是放上David ...
- 【强化学习】MOVE37-Introduction(导论)/马尔科夫链/马尔科夫决策过程
写在前面的话:从今日起,我会边跟着硅谷大牛Siraj的MOVE 37系列课程学习Reinforcement Learning(强化学习算法),边更新这个系列.课程包含视频和文字,课堂笔记会按视频为单位 ...
- 李宏毅强化学习完整笔记!开源项目《LeeDeepRL-Notes》发布
Datawhale开源 核心贡献者:王琦.杨逸远.江季 提起李宏毅老师,熟悉强化学习的读者朋友一定不会陌生.很多人选择的强化学习入门学习材料都是李宏毅老师的台大公开课视频. 现在,强化学习爱好者有更完 ...
- 【强化学习RL】必须知道的基础概念和MDP
本系列强化学习内容来源自对David Silver课程的学习 课程链接http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html 之前接触过RL ...
- 强化学习(一)—— 基本概念及马尔科夫决策过程(MDP)
1.策略与环境模型 强化学习是继监督学习和无监督学习之后的第三种机器学习方法.强化学习的整个过程如下图所示: 具体的过程可以分解为三个步骤: 1)根据当前的状态 $s_t$ 选择要执行的动作 $ a_ ...
随机推荐
- c++中比较好用的“黑科技”
切入正题,上黑科技 一.黑科技函数(常用的我就不写了,例如sort函数) 1.next_permutation(a+1,a+1+n) a[1-n]全排列 2.reverse(a+1,a+1+n) 将a ...
- Python爬虫连载5-Proxy、Cookie解析
一.ProxyHandler处理(代理服务器) 1.使用代理IP,是爬虫的常用手段 2.获取代理服务器的地址: www.xicidaili.com www.goubanjia.com 3.代理用来隐藏 ...
- AngularJs 禁止模板缓存
因为AngularJs的特性(or 浏览器本身的缓存?),angular默认的HTML模板加载都会被缓存起来.导致每次修改完模板之后都得经常需要清除浏览器的缓存来保证浏览器去获得最新的html模板,自 ...
- java多线程知识回顾(笔记)
线程创建的方式 有两种 第一种是继承Thread类 重写run方法 (个人偏向这一种实际中这种用的较多) 例如 public class MyThead extends Thread { int j= ...
- synchronized和锁(ReentrantLock) 区别
synchronized和锁(ReentrantLock) 区别 java的两种同步方式, Synchronized与ReentrantLock的区别 并发(一):理解可重入锁 可重入锁和不可重入锁 ...
- swing开发图形界面工具配置(可自由拖控件上去)
swing开发图形界面工具,eclipse swing图形化操作界面工具配置 1.有一个小功能要有一个界面,之前知道有一个 图形化界面的(就是可以往上面拖控件布局的工具)JBuilder,今天上午就下 ...
- Java程序员学习Go指南(三)
转载:https://www.luozhiyun.com/archives/213 人是否会进步以及进步得有多快,依赖的恰恰就是对自我的否定,这包括否定的深刻与否,以及否定自我的频率如何.这其实就是& ...
- C++代做,C++编程代做,C++程序代做,留学生C++ Lab代写
C++代做,C++编程代做,C++程序代做 我们主要面向留学生,广泛接美加澳国内港台等地编程作业代写,中英文均可. C语言代写 C++代写 Python代写 Golang代写 Java代写 一年半的时 ...
- ORACLE添加新用户并配置权限 添加其他用户的表权限
添加用户配置权限 1.查出表空间所在位置 ,file_name from dba_data_files order by file_id; 2.根据步骤1查出的路径.将路径替换掉并指定用户名 路径:D ...
- PIP无法使用,script文件夹为空解决
[问题]环境变量已配置,但pip.pip3无法使用,且script文件夹为空解决: 一.安装pip3 python -m ensurepip 运行完之后就pip3有了: 二.安装pip python ...