python 聚类分析 k均值算法
dataSet = [ #数据集
# 1
[0.697, 0.460],
# 2
[0.774, 0.376],
# 3
[0.634, 0.264],
# 4
[0.608, 0.318],
# 5
[0.556, 0.215],
# 6
[0.403, 0.237],
# 7
[0.481, 0.149],
# 8
[0.437, 0.211],
# 9
[0.666, 0.091],
# 10
[0.243, 0.267],
# 11
[0.245, 0.057],
# 12
[0.343, 0.099],
# 13
[0.639, 0.161],
# 14
[0.657, 0.198],
# 15
[0.360, 0.370],
# 16
[0.593, 0.042],
# 17
[0.719, 0.103],
# 18
[0.359, 0.188],
# 19
[0.339, 0.241],
# 20
[0.282, 0.257],
# 21
[0.748, 0.232],
# 22
[0.714, 0.346],
# 23
[0.483, 0.312],
# 24
[0.478, 0.437],
# 25
[0.525, 0.369],
# 26
[0.751, 0.489],
# 27
[0.532, 0.472],
# 28
[0.473, 0.376],
# 29
[0.725, 0.445],
# 30
[0.446, 0.459]
]
# print(len(dataSet))
# print(dataSet) # '''
m = len(dataSet) #存储dataSet的长度
# print(m)
k = int(input("请输入簇数:"))
miu = [] #用于存储均值向量
choice = sample(list(range(m)),k) #从列表中随机抽样k个元素
miu = [dataSet[i] for i in choice] #初始化均值向量
# print("μ:\n{}".format(miu)) times = 0
while True:
times = times+1
if times>100:
print("循环次数过多")
break
a = [[] for i in range(k)] # 用于存储样本与各均值向量的距离
# print(a)
for j in range(m): # 计算xj与各均值向量μi的距离
bar = 1000000000000000000000 #聚类比较值
biaoji = -1 # 簇标记
for i in range(k):
dis = np.hypot(dataSet[j][0]-miu[i][0],dataSet[j][1]-miu[i][1])
if dis<bar:
bar = dis; biaoji = i
a[biaoji].append(dataSet[j]) #根据距离最近的均值向量确定xj的簇标记
# print("簇0\n{}".format(a[0]))
# print("簇1\n{}".format(a[1]))
# print("簇2\n{}".format(a[2])) miu1 = [[] for i in range(k)] #重新计算均值向量
for i in range(k):
miu1[i].append(np.sum([a[i][j][0] for j in range(len(a[i]))])/len(a[i]))
miu1[i].append(np.sum([a[i][j][1] for j in range(len(a[i]))])/len(a[i]))
if miu==miu1: #如果前后均值向量相等,跳出
break
else:
miu = miu1
# break print("循环次数:\n{}".format(times))
print("簇0\n{}".format(a[0]))
print("簇1\n{}".format(a[1]))
print("簇2\n{}".format(a[2]))
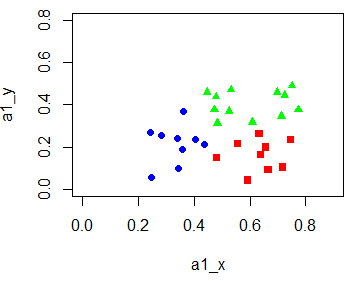
其中得到的一组结果:
x1 = [[0.634, 0.264], [0.556, 0.215], [0.481, 0.149], [0.666, 0.091], [0.639, 0.161], [0.657, 0.198], [0.593, 0.042], [0.719, 0.103], [0.748, 0.232]] x2 = [[0.403, 0.237], [0.437, 0.211], [0.243, 0.267], [0.245, 0.057], [0.343, 0.099], [0.36, 0.37], [0.359, 0.188], [0.339, 0.241], [0.282, 0.257]] x3 = [[0.697, 0.46], [0.774, 0.376], [0.608, 0.318], [0.714, 0.346], [0.483, 0.312], [0.478, 0.437], [0.525, 0.369], [0.751, 0.489], [0.532, 0.472], [0.473, 0.376], [0.725, 0.445], [0.446, 0.459]]
[0.46, 0.376, 0.318, 0.346, 0.437, 0.369, 0.489, 0.472, 0.376, 0.445, 0.459]
用R作图:
a1_x = c(0.634, 0.556, 0.481, 0.666, 0.639, 0.657, 0.593, 0.719, 0.748)
a1_y = c(0.264, 0.215, 0.149, 0.091, 0.161, 0.198, 0.042, 0.103, 0.232)
a2_x = c(0.403, 0.437, 0.243, 0.245, 0.343, 0.36, 0.359, 0.339, 0.282)
a2_y = c(0.237, 0.211, 0.267, 0.057, 0.099, 0.37, 0.188, 0.241, 0.257)
a3_x = c(0.697, 0.774, 0.608, 0.714, 0.483, 0.478, 0.525, 0.751, 0.532, 0.473, 0.725, 0.446)
a3_y = c(0.46, 0.376, 0.318, 0.346, 0.312, 0.437, 0.369, 0.489, 0.472, 0.376, 0.445, 0.459) plot(a1_x,a1_y,pch = 15,xlim = c(0,0.9),ylim = c(0,0.8),col = "red")
points(a2_x,a2_y,pch = 16,col = "blue")
points(a3_x,a3_y,pch = 17,col = "green")
#老师的代码,时间复杂度很低:
'''
1.对簇中心进行循环
2.利用numpy包的函数进行运算
'''
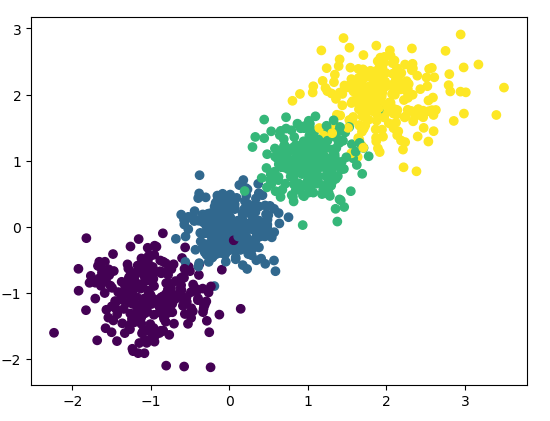
from sklearn.datasets.samples_generator import make_blobs
import numpy as np
import matplotlib.pyplot as plt
#生成数据
X,y = make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.3,0.3,0.4],random_state=7)
plt.scatter(X[:,0],X[:,1],c = y)
plt.show()
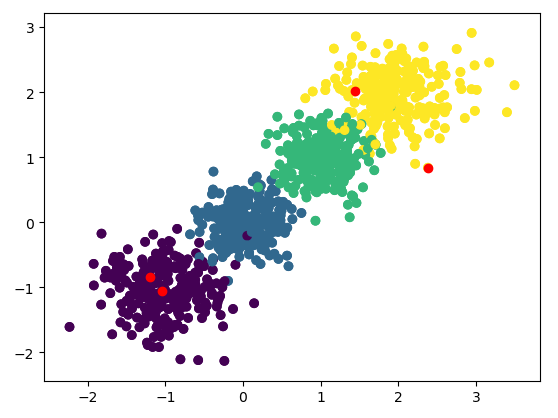
#k-means聚类
n_cluster = 4 #聚类簇数
n = len(X) #散点个数
dist = np.zeros((n,n_cluster)) #存放各点到簇中心点的距离
sample_index = np.arange(n)
cluster_center = X[np.random.choice(sample_index,n_cluster),:] #随机选取簇中心点
new_cluster_center = np.zeros((n_cluster,2)) #存放簇中心坐标
plt.scatter(X[:,0],X[:,1],c=y)
plt.scatter(cluster_center[:,0],cluster_center[:,1],c = 'red')
plt.show()
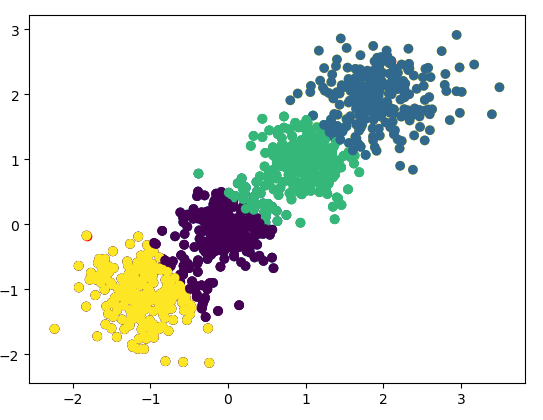
ISok = False
time = 0
while not ISok:
time = time + 1
if time>100:
break
#计算每个点到簇中心的距离
for i in range(n_cluster):
# dist[:,i] = np.sqrt(np.sum((X - cluster_center[i,:])**2,axis=1)) #存储各点到簇中心的距离
dist[:, i] = np.hypot(X[:, 0] - cluster_center[i, 0], X[:, 1] - cluster_center[i, 1])
#将数据点放进与其最近的簇
ClassID = np.argmin(dist,axis=1) #存储与数据点最近的簇中心编号
#计算新的簇中心
for i in range(n_cluster):
Classmask = (ClassID == i) #提取每个数据点的布尔值,也就是这个点属于第i簇布尔值为True
new_cluster_center[i,:] = np.average(X[Classmask,:],axis = 0) #计算新的簇中心
e = np.sum(np.sqrt(np.sum((new_cluster_center - cluster_center) ** 2, axis=1)))
# print(e)
if e < 1e-6 :
ISok = True
else:
cluster_center = new_cluster_center
print("运行了{}次".format(time))
plt.scatter(X[:,0],X[:,1],c = ClassID)
plt.show()
python 聚类分析 k均值算法的更多相关文章
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- K均值算法-python实现
测试数据展示: #coding:utf-8__author__ = 'similarface''''实现K均值算法 算法摘要:-----------------------------输入:所有数据点 ...
- 使用K均值算法进行图片压缩
K均值算法 上一期介绍了机器学习中的监督式学习,并用了离散回归与神经网络模型算法来解决手写数字的识别问题.今天我们介绍一种机器学习中的非监督式学习算法--K均值算法. 所谓非监督式学习,是一种 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- K 均值算法-如何让数据自动分组
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍到的一些机器学习算法都是监督学习算法.所谓监督学习,就是既有特征数据,又有目标数据. 而本篇文章要介绍 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
随机推荐
- 纪录片- 睡眠追踪(Chasing sleep) (共6集)
传送门:https://www.bilibili.com/bangumi/play/ep120260/ 小贴士传送门:https://www.bilibili.com/video/av11887055 ...
- 对于使用javaweb技术制作简单管理系统的学习
近期在老师的引导下我们学习了利用Javaweb技术制作简单的管理系统,其中涉及到的技术很多,由于大多都是自学 对这些技术的理解还太浅显但能实现一些相关功能的雏形. (一).登录功能 在登陆功能中通过与 ...
- navicat12破解详细教程
以管理员身份运行此注册机: 运行注册机 打开注册机后,1) Patch勾选Backup.Host和Navicat v12,然后点击Patch按钮: 默认勾选 找到Navicat Premium 12安 ...
- 前后端分离后API交互如何保证数据安全性?
一.前言 前后端分离的开发方式,我们以接口为标准来进行推动,定义好接口,各自开发自己的功能,最后进行联调整合.无论是开发原生的APP还是webapp还是PC端的软件,只要是前后端分离的模式,就避免不了 ...
- Java后端 带File文件及其它参数的Post请求
http://www.roak.com Java 带File文件及其它参数的Post请求 对于文件上传,客户端通常就是页面,在前端web页面里实现上传文件不是什么难事,写个form,加上enctype ...
- 获取Webshell方法总结
一.CMS获取Webshell方法 搜索CMS网站程序名称 eg:phpcms拿webshell.wordpress后台拿webshell 二.非CMS获取Webshell方法 2.1数据库备份获取W ...
- SVN提交失败:Changing file 'XXX' is forbidden by the server;Access to 'XXX' forbidden
解决方案:https://blog.csdn.net/m0_38084243/article/details/81503638 个人分析主要是后者,在SVN服务器上添加上我对本项目的读写权限即可: 添 ...
- winform跳转到bs
private void button7_Click(object sender, EventArgs e) { System.Diagnostics.Process.Start("http ...
- 单页面应用程序(SPA)的优缺点
我们通常所说的单页面应用程序通常通过前端框架(angular.react.vue)进行开发,单页面应用程序将所有的活动局限于一个Web页面中,仅在该Web页面初始化时加载相应的HTML.JavaScr ...
- CF1209C Paint the Digits
CF1209C Paint the Digits 题意:给定T组数据,每组数据第一行输入数字串长度,第二行输入数字串,用数字1和2对数字串进行涂色,被1涂色的数字子串和被2涂色的数字子串拼接成新的数字 ...