HiBench成长笔记——(4) HiBench测试Spark SQL
很多内容之前的博客已经提过,这里不再赘述,详细内容参照本系列前面的博客:https://www.cnblogs.com/ratels/p/10970905.html 和 https://www.cnblogs.com/ratels/p/10976060.html
执行脚本
bin/workloads/sql/scan/prepare/prepare.sh
返回信息
[root@node1 prepare]# ./prepare.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/spark.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/sql/scan.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start HadoopPrepareScan bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Scan/Input rm: `hdfs://node1:8020/HiBench/Scan/Input': No such file or directory Pages:, USERVISITS: Submit MapReduce Job: /opt/cloudera/parcels/CDH--.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn jar /home/cf/app/HiBench-master/autogen/target/autogen-7.1-SNAPSHOT-jar-with-dependencies.jar HiBench.DataGen -t hive -b hdfs://node1:8020/HiBench/Scan -n Input -m 8 -r 8 -p 120 -v 1000 -o sequence // :: INFO HiBench.HiveData: Closing hive data generator... finish HadoopPrepareScan bench

执行脚本
bin/workloads/sql/scan/spark/run.sh
返回信息
[root@node1 spark]# ./run.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/spark.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/sql/scan.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start ScalaSparkScan bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Scan/Output rm: `hdfs://node1:8020/HiBench/Scan/Output': No such file or directory Export env: SPARKBENCH_PROPERTIES_FILES=/home/cf/app/HiBench-master/report/scan/spark/conf/sparkbench/sparkbench.conf Export env: HADOOP_CONF_DIR=/etc/hadoop/conf.cloudera.yarn Submit Spark job: /opt/cloudera/parcels/CDH--.cdh5./lib/spark/bin/spark-submit --properties- --executor-cores --executor-memory 4g /home/cf/app/HiBench-master/sparkbench/assembly/target/sparkbench-assembly-7.1-SNAPSHOT-dist.jar ScalaScan /home/cf/app/HiBench-master/report/scan/spark/conf/../rankings_uservisits_scan.hive // :: INFO CuratorFrameworkSingleton: Closing ZooKeeper client. hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -du -s hdfs://node1:8020/HiBench/Scan/Output finish ScalaSparkScan bench

查看ResourceManager Web UI
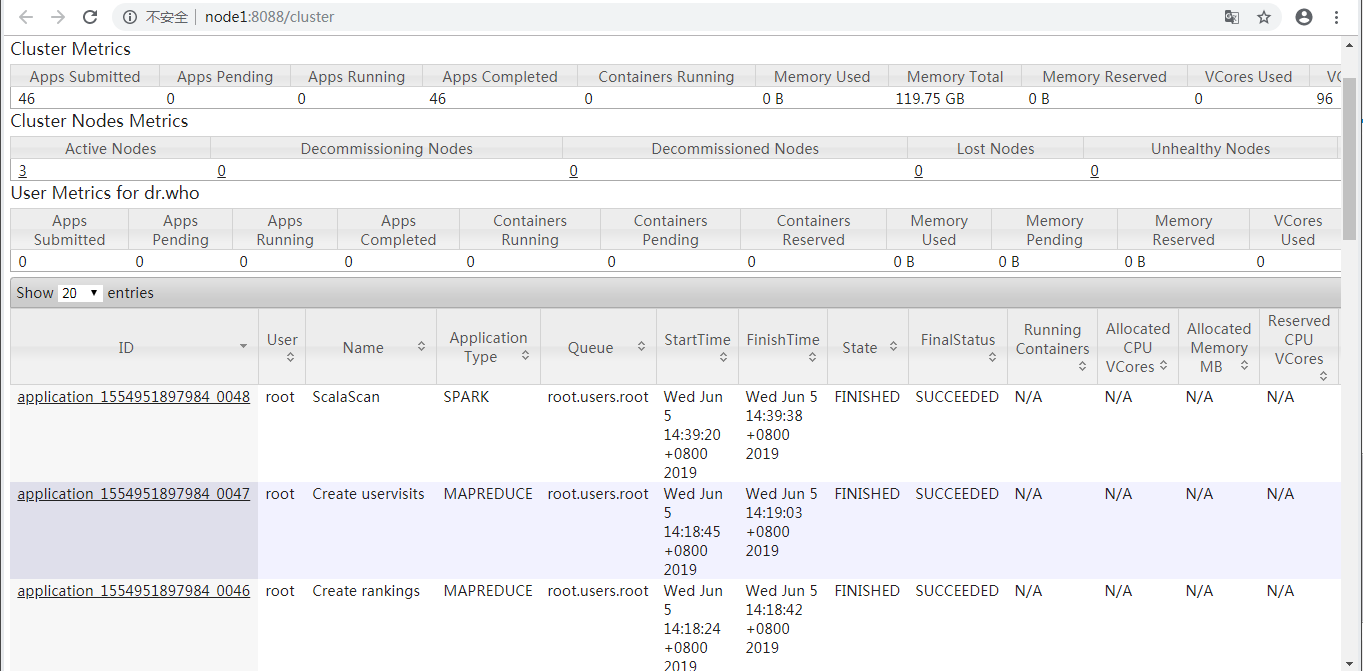
prepare.sh启动了application_1554951897984_0047和application_1554951897984_0046两个MAPREDUCE任务,run.sh启动了application_1554951897984_0048这个Spark任务。
查看(Hadoop)HistoryServer Web UI
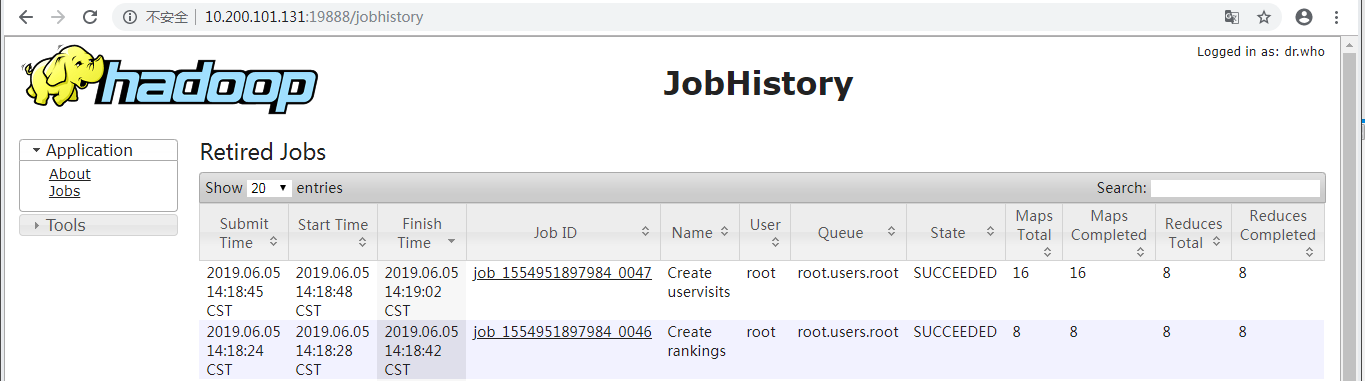
显示了prepare.sh启动的application_1554951897984_0047和application_1554951897984_0046两个MAPREDUCE任务。
查看(Spark) History Server Web UI
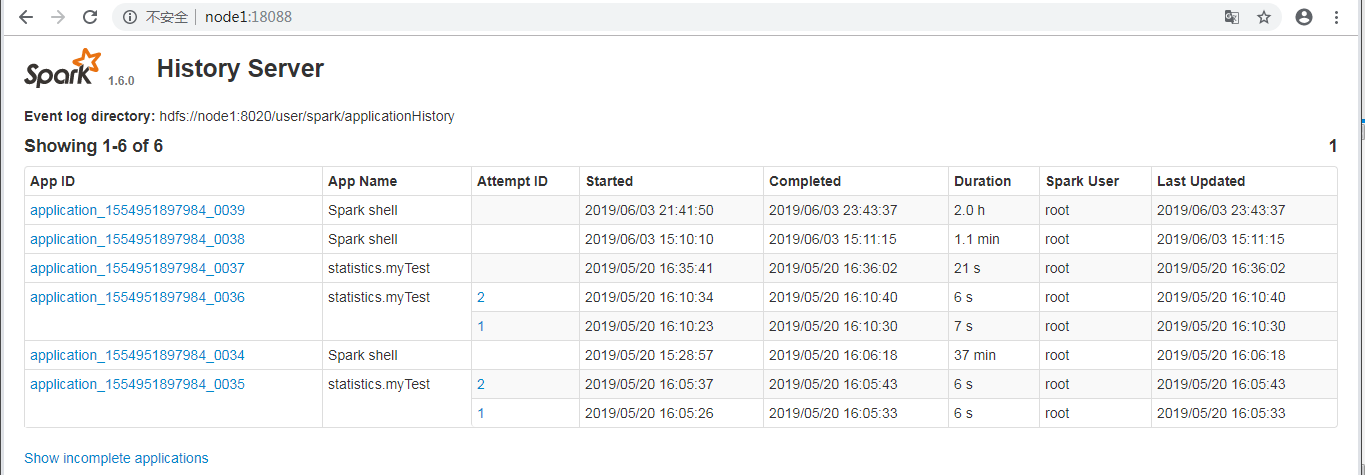
并未显示run.sh启动的application_1554951897984_0048这个Spark任务。
执行脚本
bin/workloads/sql/join/prepare/prepare.sh
返回信息
[root@node1 prepare]# ./prepare.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/spark.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/sql/join.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start HadoopPrepareJoin bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Join/Input rm: `hdfs://node1:8020/HiBench/Join/Input': No such file or directory Pages:, USERVISITS: Submit MapReduce Job: /opt/cloudera/parcels/CDH--.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn jar /home/cf/app/HiBench-master/autogen/target/autogen-7.1-SNAPSHOT-jar-with-dependencies.jar HiBench.DataGen -t hive -b hdfs://node1:8020/HiBench/Join -n Input -m 8 -r 8 -p 120 -v 1000 -o sequence // :: INFO HiBench.HiveData: Closing hive data generator... finish HadoopPrepareJoin bench
执行脚本
bin/workloads/sql/join/spark/run.sh
返回信息
[root@node1 spark]# ./run.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/spark.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/sql/join.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start ScalaSparkJoin bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -du -s hdfs://node1:8020/HiBench/Join/Input hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Join/Output rm: `hdfs://node1:8020/HiBench/Join/Output': No such file or directory Export env: SPARKBENCH_PROPERTIES_FILES=/home/cf/app/HiBench-master/report/join/spark/conf/sparkbench/sparkbench.conf Export env: HADOOP_CONF_DIR=/etc/hadoop/conf.cloudera.yarn Submit Spark job: /opt/cloudera/parcels/CDH--.cdh5./lib/spark/bin/spark-submit --properties- --executor-cores --executor-memory 4g /home/cf/app/HiBench-master/sparkbench/assembly/target/sparkbench-assembly-7.1-SNAPSHOT-dist.jar ScalaJoin /home/cf/app/HiBench-master/report/join/spark/conf/../rankings_uservisits_join.hive // :: INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports. finish ScalaSparkJoin bench
执行脚本
bin/workloads/sql/aggregation/prepare/prepare.sh
返回信息
[root@node1 prepare]# ./prepare.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/spark.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/sql/aggregation.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start HadoopPrepareAggregation bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Aggregation/Input rm: `hdfs://node1:8020/HiBench/Aggregation/Input': No such file or directory Pages:, USERVISITS: Submit MapReduce Job: /opt/cloudera/parcels/CDH--.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn jar /home/cf/app/HiBench-master/autogen/target/autogen-7.1-SNAPSHOT-jar-with-dependencies.jar HiBench.DataGen -t hive -b hdfs://node1:8020/HiBench/Aggregation -n Input -m 8 -r 8 -p 120 -v 1000 -o sequence // :: INFO HiBench.HiveData: Closing hive data generator... finish HadoopPrepareAggregation bench
执行脚本
bin/workloads/sql/aggregation/spark/run.sh
返回信息
[root@node1 spark]# ./run.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/spark.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/sql/aggregation.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start ScalaSparkAggregation bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Aggregation/Output rm: `hdfs://node1:8020/HiBench/Aggregation/Output': No such file or directory Export env: SPARKBENCH_PROPERTIES_FILES=/home/cf/app/HiBench-master/report/aggregation/spark/conf/sparkbench/sparkbench.conf Export env: HADOOP_CONF_DIR=/etc/hadoop/conf.cloudera.yarn Submit Spark job: /opt/cloudera/parcels/CDH--.cdh5./lib/spark/bin/spark-submit --properties- --executor-cores --executor-memory 4g /home/cf/app/HiBench-master/sparkbench/assembly/target/sparkbench-assembly-7.1-SNAPSHOT-dist.jar ScalaAggregation /home/cf/app/HiBench-master/report/aggregation/spark/conf/../uservisits_aggre.hive // :: INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports. hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -du -s hdfs://node1:8020/HiBench/Aggregation/Output finish ScalaSparkAggregation bench
参考:https://www.cnblogs.com/barneywill/p/10436299.html
HiBench成长笔记——(4) HiBench测试Spark SQL的更多相关文章
- HiBench成长笔记——(1) HiBench概述
测试分类 HiBench共计19个测试方向,可大致分为6个测试类别:分别是micro,ml(机器学习),sql,graph,websearch和streaming. 2.1 micro Benchma ...
- HiBench成长笔记——(3) HiBench测试Spark
很多内容之前的博客已经提过,这里不再赘述,详细内容参照本系列前面的博客:https://www.cnblogs.com/ratels/p/10970905.html 创建并修改配置文件conf/spa ...
- HiBench成长笔记——(6) HiBench测试结果分析
Scan Join Aggregation Scan Join Aggregation Scan Join Aggregation Scan Join Aggregation Scan Join Ag ...
- HiBench成长笔记——(5) HiBench-Spark-SQL-Scan源码分析
run.sh #!/bin/bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributo ...
- HiBench成长笔记——(2) CentOS部署安装HiBench
安装Scala 使用spark-shell命令进入shell模式,查看spark版本和Scala版本: 下载Scala2.10.5 wget https://downloads.lightbend.c ...
- HiBench成长笔记——(8) 分析源码workload_functions.sh
workload_functions.sh 是测试程序的入口,粘连了监控程序 monitor.py 和 主运行程序: #!/bin/bash # Licensed to the Apache Soft ...
- HiBench成长笔记——(7) 阅读《The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis》
<The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis>内容精选 We th ...
- HiBench成长笔记——(10) 分析源码execute_with_log.py
#!/usr/bin/env python2 # Licensed to the Apache Software Foundation (ASF) under one or more # contri ...
- HiBench成长笔记——(9) 分析源码monitor.py
monitor.py 是主监控程序,将监控数据写入日志,并统计监控数据生成HTML统计展示页面: #!/usr/bin/env python2 # Licensed to the Apache Sof ...
随机推荐
- 在iOS项目中,这样才能完美的修改项目名称
https://www.cnblogs.com/liangyi-cn/p/8657474.html 前言: 在iOS开发中,有时候想改一下项目的名字,这会遇到很多麻烦. 直接改项目名的话,Xcode不 ...
- 阿里云linux挂载磁盘
1)使用fdisk -l命令查看主机上的硬盘 2.使用mkfs.ext4命令把硬盘格式化: mkfs.ext4 磁盘名称 如:mkfs.ext4 /dev/vdb/ 3. 使用mount命令 ...
- ADO.Net实体数据模型添加DB-First/Code First报错
Authentication method 'caching_sha2_password' not supported by any of the available plugins. 解决办法: 1 ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 显示代码:多行代码带有滚动条
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 排版:设定文本小写
<!DOCTYPE html> <html> <head> <title>菜鸟教程(runoob.com)</title> <meta ...
- idea 添加 阿里代码规范
参考: https://blog.csdn.net/weixin_39220472/article/details/80077803
- 5G时代,行业市场用户的公网与专网如何选择
导读 今年,5G开启了真刀真枪的商用元年,尤其中国5G正式启动商用服务,5G规模商用进程再次大提速.除了面向消费者领域,5G更大的商业价值还是寄望于进入各个垂直行业,赋能千行百业数字化转型. 5G进入 ...
- Hexo引入Mermaid流程图和MathJax数学公式
近来用Markdown写文章,越来越不喜欢插入图片了,一切能用语法解决的问题坚决不放图,原因有二: 如果把流程图和数学公式都以图片方式放到文章内,当部署到Github上后,访问博客时图片加载实在太慢, ...
- 移动端禁止缩放<meta>
<meta name="viewport" content="width=device-width,initial-scale=1.0,minimum-scale= ...
- luogu P2754 [CTSC1999]家园
本题是分层图最大流问题,相当于按时间拆点,每个当前点向下一点的下一时间层连点,每一层有n+1个点 #include<bits/stdc++.h> using namespace std; ...