MapReduce程序开发之流量求和(八)
1.分析记录手机流量的日志。
2.拿到日志中的一行数据,切分各个字段,抽取出我们需要的字段:手机号,上行流量,下行流量,然后封装成kv发送出去
3.使用java中的map方法;
public class FlowNumMapper extends Mapper<LongWritable,Text,Text,FlowBean> {
@Override
protected void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException{
//拿一行数据
String line = value.toString();
//切分成各个字段
String[] fields=StringUtils.split(line, "\t");
String phoneNB=fields[1];
long u_flow=Long.parseLong(fields[7]);
long d_flow=Long.parseLong(fields[8]);
//封装数据为KV并输出
context.write(new Text(phoneNB), new FlowBean(phoneNB,u_flow,d_flow));
}
}
4.在map方法中FlowBean参数传递的是一个序列化实体。
package hadoop.mr.flownum;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class FlowBean implements Writable {
private String phoneNB;
private long up_flow;
private long d_flow;
private long s_flow;
// 在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数
public FlowBean() {
}
// 为了对象数据的初始化方便,加入一个带参数的构造函数
public FlowBean(String phoneNB, long up_flow, long d_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.d_flow = d_flow;
this.s_flow = up_flow + d_flow;
}
public String getPhoneNB() {
return phoneNB;
}
public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB;
}
public long getUp_flow() {
return up_flow;
}
public void setUp_flow(long up_flow) {
this.up_flow = up_flow;
}
public long getD_flow() {
return d_flow;
}
public void setD_flow(long d_flow) {
this.d_flow = d_flow;
}
public long getS_flow() {
return s_flow;
}
public void setS_flow(long s_flow) {
this.s_flow = s_flow;
}
// 将对象数据序列化对流中
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNB);
out.writeLong(up_flow);
out.writeLong(d_flow);
out.writeLong(s_flow);
}
// 从数据流中反序列出对象的数据
// 从数据流中读出对象字段时,必须跟序列化时的顺序保持一样
@Override
public void readFields(DataInput in) throws IOException {
phoneNB = in.readUTF();
up_flow = in.readLong();
d_flow = in.readLong();
s_flow = in.readLong();
}
@Override
public String toString(){
return ""+up_flow+"\t"+d_flow+"\t"+s_flow;
}
}
5.传一组数据调用一次我们的reduce方法,reduce中的业务逻辑就是遍历values,然后进行累加求和输出.
package hadoop.mr.flownum;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowNumReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context)
throws IOException, InterruptedException {
long up_flow_counter=0;
long d_flow_counter=0;
for (FlowBean bean : values) {
up_flow_counter +=bean.getD_flow();
d_flow_counter+=bean.getD_flow();
}
context.write(key, new FlowBean(key.toString(),up_flow_counter,d_flow_counter));
}
}
6.job提交:
package hadoop.mr.flownum;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
public class FlowNumRunner extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FlowNumRunner.class);
job.setMapperClass(FlowNumMapper.class);
job.setMapOutputKeyClass(FlowNumReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new FlowNumRunner(), args);
System.exit(res);
}
}
7.对mapreduce进行打包。
8.把打包的jar包上传到虚拟机,把要统计的日志上传到hadoop
hadoop fs -put HTTP_20130313143750.dat /flow/data
在hadoop中执行flow.jar结果输出到flow/output文件下
hadoop jar flow.jar hadoop.mr.flownum.FlowNumRunner /flow/data /flow/output
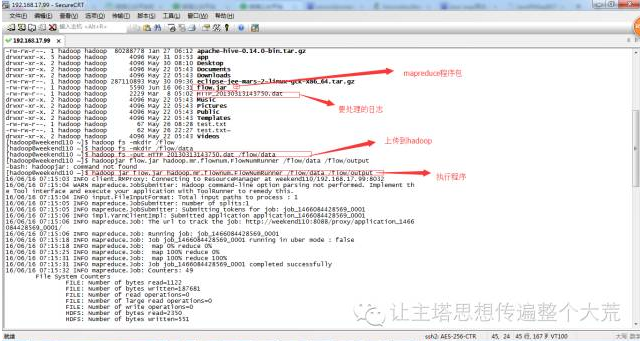
9.执行hadoop fs -cat /flow/output/part-r-00000命令查询里面输出的内容,对日志里面的内容统计如下:

MapReduce程序开发之流量求和(八)的更多相关文章
- 一脸懵逼学习Hadoop中的序列化机制——流量求和统计MapReduce的程序开发案例——流量求和统计排序
一:序列化概念 序列化(Serialization)是指把结构化对象转化为字节流.反序列化(Deserialization)是序列化的逆过程.即把字节流转回结构化对象.Java序列化(java.io. ...
- 基于HBase Hadoop 分布式集群环境下的MapReduce程序开发
HBase分布式集群环境搭建成功后,连续4.5天实验客户端Map/Reduce程序开发,这方面的代码网上多得是,写个测试代码非常容易,可是真正运行起来可说是历经挫折.下面就是我最终调通并让程序在集群上 ...
- 大数据笔记(七)——Mapreduce程序的开发
一.分析Mapreduce程序开发的流程 1.图示过程 输入:HDFS文件 /input/data.txt Mapper阶段: K1:数据偏移量(以单词记)V1:行数据 K2:单词 V2:记一次数 ...
- Hadoop(三):MapReduce程序(python)
使用python语言进行MapReduce程序开发主要分为两个步骤,一是编写程序,二是用Hadoop Streaming命令提交任务. 还是以词频统计为例 一.程序开发1.Mapper for lin ...
- 1 weekend110的复习 + hadoop中的序列化机制 + 流量求和mr程序开发
以上是,weekend110的yarn的job提交流程源码分析的复习总结 下面呢,来讲weekend110的hadoop中的序列化机制 1363157985066 13726230503 ...
- windows环境下Eclipse开发MapReduce程序遇到的四个问题及解决办法
按此文章<Hadoop集群(第7期)_Eclipse开发环境设置>进行MapReduce开发环境搭建的过程中遇到一些问题,饶了一些弯路,解决办法记录在此: 文档目的: 记录windows环 ...
- YARN应用程序开发流程(类似于MapReduce On Yarn)本内容版权归(小象学院所有)
MapReduce On Yarn和MapReduce程序区别 MapReduce On Yarn(由专业人员开发)1 为MapReduce作业运行在YARN上提供一个通用的运行时环境2 需要与Yar ...
- [MapReduce_add_1] Windows 下开发 MapReduce 程序部署到集群
0. 说明 Windows 下开发 MapReduce 程序部署到集群 1. 前提 在本地开发的时候保证 resource 中包含以下配置文件,从集群的配置文件中拷贝 在 resource 中新建 ...
- Windows平台开发Mapreduce程序远程调用运行在Hadoop集群—Yarn调度引擎异常
共享原因:虽然用一篇博文写问题感觉有点奢侈,但是搜索百度,相关文章太少了,苦苦探寻日志才找到解决方案. 遇到问题:在windows平台上开发的mapreduce程序,运行迟迟没有结果. Mapredu ...
随机推荐
- iOS10-配置获取隐私数据权限声明
iOS10中,苹果加强了对用户隐私数据的保护,在访问以下数据的时候都需要在info.list重配置privacy,进行声明,否则程序无法正常运行. Contacts, Calendar, Remind ...
- 【转】服务器证书安装配置指南(Weblogic)
服务器证书安装配置指南(Weblogic) 详情请点击: http://verisign.itrus.com.cn/html/fuwuyuzhichi/fuwuqizhengshuanzhuangpe ...
- HTML Canvas 鼠标画图
原文来自:http://www.williammalone.com/articles/create-html5-canvas-javascript-drawing-app(已被墙) 译文: http: ...
- Struts2 result type
Struts2支持的不同类型的返回结果为: type name 说明 dispatcher 缺省类型,用来转向页面,通常处理JSP chain 转向另一个action,用来处理Action链 redi ...
- Java多线程编程<一>
怎样做到线程安全? 1.不要跨线程共享变量: 2.使状态变量为不可变的: 3.或者在任何访问状态变量的时候使用同步 同步synchronized //静态的synchronized方法从Class对象 ...
- android入门系列- TextView EditText Button ImageView 的简单应用
第一篇原创,其实自己就是一菜鸟,简单分享点基本知识吧.希望能有所帮助吧. TextView EditText Button ImageView 这几个控件可能是Android开发中最常用.最基本的几个 ...
- oracle 导出导入数据
在window的运行中输出cmd,然后执行下面的一行代码, imp blmp/blmp@orcl full=y file=D:\blmp.dmp OK,问题解决.如果报找不到该blmp.dmp文件,就 ...
- window.showModalDialog()复制内容
ShowModalDialog 打开的 页面上加入个 <span id="mySpan" name="mySpan" contentEditable=&q ...
- 设置linux服务器定时与时间服务器同步
在一些大公司经常出现这样一个情况:公司或一些机关单位的内部业务系统的应用服务器以及数据都是做的多机集群部署而且基本都是linux系统,而且都是内部网,不与外网通讯的.这样经常就会出现一个情况,我发送任 ...
- app图标和启动页设置
弄了一下午,终于把iOS中图标的设置和启动页的设置弄明白了.我想以后再也不会浑了. 进入正题: 一:apple 1).iPhone4s 3.5寸屏,也就是640*960,但在模拟器上正常用的是320* ...