Consumer Group Example



面向kafka编程
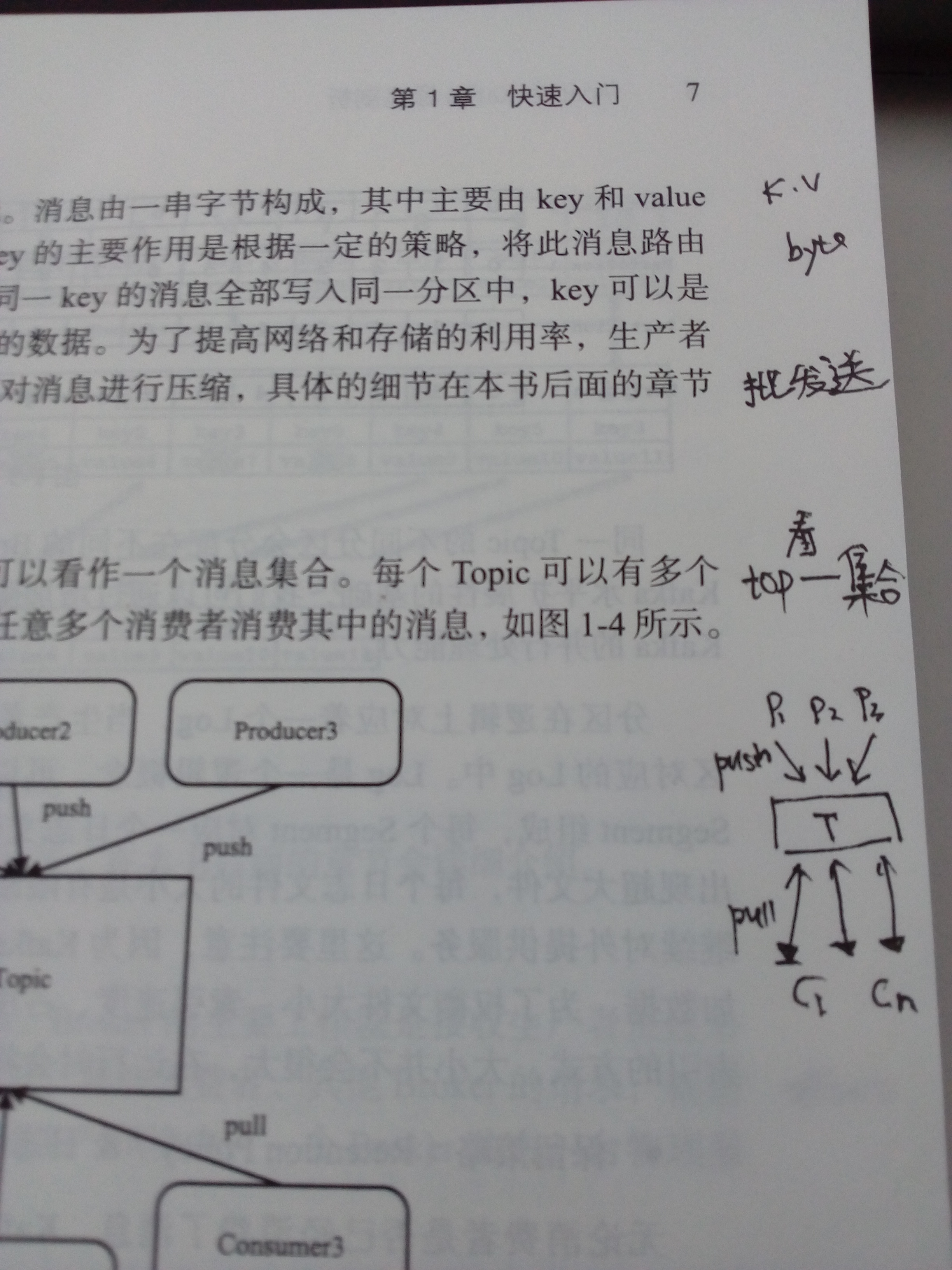
Consumer Group Example
https://cwiki.apache.org/confluence/display/KAFKA/Consumer+Group+Example
The ‘zookeeper.session.timeout.ms’ is how many milliseconds Kafka will wait for ZooKeeper to respond to a request (read or write) before giving up and continuing to consume messages.
The ‘zookeeper.sync.time.ms’ is the number of milliseconds a ZooKeeper ‘follower’ can be behind the master before an error occurs.
https://cwiki.apache.org/confluence/display/KAFKA/Consumer+Group+Example
http://kafka.apache.org/documentation.html
private static ConsumerConfig createConsumerConfig(String a_zookeeper, String a_groupId) {
Properties props = new Properties();
props.put("zookeeper.connect", a_zookeeper);
props.put("group.id", a_groupId);
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
【多对多】
package com.test.groups; import kafka.consumer.ConsumerConfig;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector; import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors; public class ConsumerGroupExample {
private final ConsumerConnector consumer;
private final String topic;
private ExecutorService executor; public ConsumerGroupExample(String a_zookeeper, String a_groupId, String a_topic) {
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
createConsumerConfig(a_zookeeper, a_groupId));
this.topic = a_topic;
} public void shutdown() {
if (consumer != null) consumer.shutdown();
if (executor != null) executor.shutdown();
try {
if (!executor.awaitTermination(5000, TimeUnit.MILLISECONDS)) {
System.out.println("Timed out waiting for consumer threads to shut down, exiting uncleanly");
}
} catch (InterruptedException e) {
System.out.println("Interrupted during shutdown, exiting uncleanly");
}
} public void run(int a_numThreads) {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(a_numThreads));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
List<KafkaStream<byte[], byte[]>> streams = consumerMap.get(topic); // now launch all the threads
//
executor = Executors.newFixedThreadPool(a_numThreads); // now create an object to consume the messages
//
int threadNumber = 0;
for (final KafkaStream stream : streams) {
executor.submit(new ConsumerTest(stream, threadNumber));
threadNumber++;
}
} private static ConsumerConfig createConsumerConfig(String a_zookeeper, String a_groupId) {
Properties props = new Properties();
props.put("zookeeper.connect", a_zookeeper);
props.put("group.id", a_groupId);
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000"); return new ConsumerConfig(props);
} public static void main(String[] args) {
String zooKeeper = args[0];
String groupId = args[1];
String topic = args[2];
int threads = Integer.parseInt(args[3]); ConsumerGroupExample example = new ConsumerGroupExample(zooKeeper, groupId, topic);
example.run(threads); try {
Thread.sleep(10000);
} catch (InterruptedException ie) { }
example.shutdown();
}
}
| group.id | A unique string that identifies the consumer group this consumer belongs to. This property is required if the consumer uses either the group management functionality by using subscribe(topic) or the Kafka-based offset management strategy. |
string |
Consumer Group Example的更多相关文章
- Kafka消费组(consumer group)
一直以来都想写一点关于kafka consumer的东西,特别是关于新版consumer的中文资料很少.最近Kafka社区邮件组已经在讨论是否应该正式使用新版本consumer替换老版本,笔者也觉得时 ...
- consumer group
Kafka消费组(consumer group)一直以来都想写一点关于kafka consumer的东西,特别是关于新版consumer的中文资料很少.最近Kafka社区邮件组已经在讨论是否应该正式使 ...
- .net Kafka.Client多个Consumer Group对Topic消费不能完全覆盖研究总结(一)
我们知道Kafka支持Consumer Group的功能,但是最近在应用Consumer Group时发现了一个Topic 的Partition不能100%覆盖的问题. 程序部署后,发现Kafka在p ...
- 查询订阅某topic的所有consumer group(Java API)
在网上碰到的问题,想了下使用现有的API还是可以实现的. 首先,需要引入Kafka服务器端代码,比如加入Kafka 1.0.0依赖: Maven <dependency> <grou ...
- Kafka consumer group位移0ffset重设
本文阐述如何使用Kafka自带的kafka-consumer-groups.sh脚本随意设置消费者组(consumer group)的位移.需要特别强调的是, 这是0.11.0.0版本提供的新功能且只 ...
- Consumer group理解深入
每一个consumer实例都属于一个consumer group,每一条消息只会被同一个consumer group里的一个consumer实例消费.(不同consumer group可以同时消费同一 ...
- .net Kafka.Client多个Consumer Group对Topic消费不能完全覆盖研究总结(二)
依据Partition和Consumer的Rebalance策略,找到Kafka.Client Rebalance代码块,还原本地环境,跟踪调试,发现自定义Consumer Group 的Consum ...
- Kafka获取订阅某topic的所有consumer group【客户端版】
之前写过如何用服务器端的API代码来获取订阅某topic的所有consumer group,参见这里.使用服务器端的API需要用到kafka.admin.AdminClient类,但是这个类在0.11 ...
- Java API获取consumer group最新提交位移的时间
碰到了有人问起这个问题,目前java consumer没有利用OffsetAndMetadata中的metadata字段记录提交的时间,故直接通过java consumer来查询是不行,我们需要直接读 ...
- Kafka设计解析(十九)Kafka consumer group位移重设
转载自 huxihx,原文链接 Kafka consumer group位移重设 本文阐述如何使用Kafka自带的kafka-consumer-groups.sh脚本随意设置消费者组(consumer ...
随机推荐
- 10.1综合强化刷题 Day5
T1 拼不出的数 lost.in/.out/.cpp[问题描述]3 个元素的集合{5; 1; 2}的所有子集的和分别是0; 1; 2; 3; 5; 6; 7; 8.发现最小的不能由该集合子集拼出的数字 ...
- Xamarin XAML语言教程Xamarin.Forms中改变活动指示器颜色
Xamarin XAML语言教程Xamarin.Forms中改变活动指示器颜色 在图12.10~12.12中我们会看到在各个平台下活动指示器的颜色是不一样的.Android的活动指示器默认是深粉色的: ...
- Kali Linux 2017.1脚本gerix.py修复
Kali Linux 2017.1脚本gerix.py修复 Gerix是一款优秀的图形界面的无线渗透工具.从Kali Linux 2016.2开始,该工具在Kali Linux中运行就存在一些问题 ...
- Apollo 分布式配置中心
1. 介绍 Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境.不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限.流程治理等特性,适用于微服务配置 ...
- 单源最短路Dijstra算法
Dijstra算法是寻找从某一顶点i出发到大其他顶点的最短路径.Distra算法的思想与Prim算法很像,它收录顶点的规则是按照路径长度递增的顺序收录的.设v0是源顶点,我们要寻找从v0出发到其他任意 ...
- IntelliJ IDEA创建文件时自动填入作者时间 定制格式
IntelliJ IDEA创建文件时自动填入作者时间 定制格式 学习了:https://blog.csdn.net/Hi_Boy_/article/details/78205483 学习了:http: ...
- mysql 远程登陆不上
当使用 TCP/IP 连接 mysql 时, 出现 : Can't connect to MySQL server on 'xxx.xxx.xxx.xxx.'(111) 这个错误. 经过重复折腾: 确 ...
- CentOS SVN 服务器搭建
源码目录:/home/user/project 工程名:project 工程目录:/source/svn/project 访问地址:svn://ip/project 一. 安装svn yum inst ...
- 应用设置Setting的实现
有非常多应用都在iOS设置中有相关的设置.例如以下图: 通过这个设置能够方便的相应用的一些主要的设置进行更改. 要完整的实现这个设置功能,有下面几方面问题须要解决: 1)设置的编写(实现设置的 ...
- [LeetCode] Decode Ways 解码方法个数、动态规划
A message containing letters from A-Z is being encoded to numbers using the following mapping: 'A' - ...